ШЋЮФСДНгЃКhttp://tecdat.cn/?p=32418
ДѓСПЪ§ОнжаОпга"ЯрЫЦ"ЬиеїЕФЪ§ОнЕуЛђбљБОЛЎЗжЮЊвЛИіРрБ№ЁЃОлРрЗжЮіЬсЙЉСЫбљБОМЏдкЗЧМрЖНФЃЪНЯТЕФРрБ№ЛЎЗжЃЈЕуЛїЮФФЉЁАдФЖСдЮФЁБЛёШЁЭъећДњТыЪ§ОнЃЉЁЃ
ШЫУЧдкЭЖзЪЪБзмЦкЭћвдзюаЁЕФЗчЯеЛёШЁзюДѓЕФРћвцЃЌУцЖдХгДѓЕФЙЩЦБЪаГЁКЭЗБдгЕФЙЩЦБЪ§ОнЃЌвЊЯыЖдЙЩЦБНјааКЯРэЕФЗжЮіКЭбЁдёЃЌОлРрЗжЮіОЭЯдЕУгШЮЊживЊЁЃ
дкБОЮФжаЃЌЮвУЧВЩгУСЫИФНјK-meansОлРрЗЈАяжњПЭЛЇЖдЫцЛњбЁдёЕФИіЙЩЃЈВщПДЮФФЉСЫНтЪ§ОнУтЗбЛёШЁЗНЪНЃЉНјааСЫОлРрЃЌВЂЖдИїРрЙЩЦБНјааСЫЗжЮіЃЌИјГіСЫЯргІЕФЭЖзЪНЈвщЁЃ
ЖСШЁЪ§Он
ЙЩЦБгЏРћФмСІЗжЮіЪ§Он

data=read.xlsx("ЙЩЦБгЏРћФмСІЗжЮі.xlsx")

ГѕЪМОлРржааФИіЪ§
ГѕЪМОлРржааФЪ§ФПkЕФбЁШЁЪЧвЛИіНЯЮЊРЇФбЕФЮЪЬтЁЃДЋЭГЕФK-meansОлРрЫуЗЈашвЊгУЛЇЪТЯШИјЖЈОлРрЪ§ФПkЃЌЕЋЪЧгУЛЇвЛАуЧщПіЯТВЂВЛжЊЕРШЁЪВУДбљЕФkжЕЖдздМКзюгаРћЁЂЛђепЫЕЪВУДбљЕФkжЕЖдЪЕМЪгІгУВХЪЧзюКЯРэЕФЃЌетжжЧщПіЯТИјГіkжЕЫфШЛЖдОлРрБОЩэЛсБШНЯПьЫйЁЂИпаЇЃЌЕЋЪЧЖдгквЛаЉЪЕМЪЮЪЬтРДЫЕОлРраЇЙћШДЪЧВЛМбЕФЁЃЫљвдЃЌЯТУцЮвЬсГівЛжжШЗЖЈзюМбОлРрИіЪ§kЕФЗНЗЈЁЃ
ЫуЗЈУшЪігыВНжшЃК
ЪфШыЃКАќКЌnИіЖдЯѓЕФЪ§ОнМЏЃЛ
ЪфГіЃКЪЙЕУШЁжЕзюаЁЕФЖдгІЕФkжЕЁЃ
ЃЈ1ЃЉИљОнГѕВНШЗЖЈДиРрИіЪ§kЕФЗЖЮЇЃЛ
ЃЈ2ЃЉШдШЛЪЧгУK-meansЫуЗЈЖдЕФУПвЛИіkжЕЗжБ№НјааОлРрЃЛ
ЃЈ3ЃЉЗжБ№МЦЫуВЛЭЌОлРрИіЪ§kЫљЖдгІЕФЕФжЕЃЛ
ЃЈ4ЃЉевГізюаЁЕФжЕЃЌМЧЯТЖдгІЕФkжЕЃЌЫуЗЈНсЪјЁЃ
S[1]=sum(abs(data[,3:9]-result$centers)^2)/min(abs(data[,3:9]-result$ce plot(2:6,S,type="b")
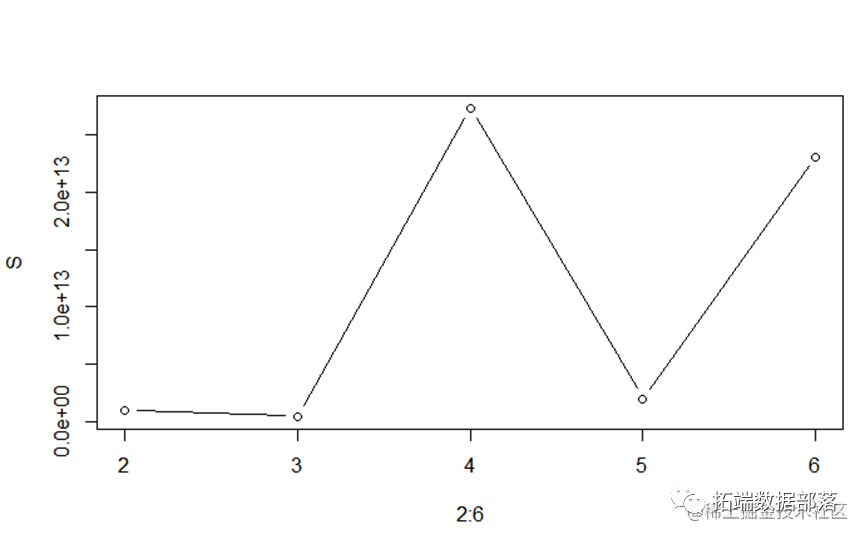
ЕуЛїБъЬтВщдФЭљЦкФкШн

RгябдЮФБОЭкОђЃКkmeansОлРрЗжЮіЩЯКЃТъбХЫЎЙЋдАОАЧјЮхвЛМйЦкЦРТлДЪдЦПЩЪгЛЏ
01

02
03
04

ГѕЪМжааФЮЛжУЕФбЁШЁ
ДЋЭГЕФK-meansОлРрЫуЗЈжаЃЌЮвУЧзмЪЧЯЃЭћФмНЋЙТСЂЕуЖдОлРраЇЙћЕФгАЯьзюаЁЛЏЃЌЕЋЪЧЙТСЂЕуЪЕМЪЩЯдкеЉЦЬНВтЁЂАВШЋадМьВтвдМАЩшБИЙЪеЯЗжЮіЕШЗНУцЦ№зХВЛЗВЕФзїгУЃЛШЛЖјЃЌБОЮФХХГ§вдЩЯетаЉвђЫиЃЌЕЅДПЕиПМТЧОлРраЇЙћКУЛЕЁЃФЧУДЮЊСЫБмУтНЋЙТСЂЕуЮѓбЁЮЊГѕЪМжааФЃЌЮвУЧбЁдёИпУмЖШЪ§ОнМЏКЯЧјгђDжаЕФЪ§ОнзїЮЊОлРрГѕЪМжааФЁЃ
ЛљБОЫМЯыЃК
ДЋЭГK-meansОлРрВЩгУЫцЛњбЁдёГѕЪМжааФЕФЗНЗЈвЛЕЉбЁЕНЙТСЂЕуЃЌЛсЖдОлРрНсЙћВњЩњКмДѓЕФгАЯьЃЌЫљвдЮвУЧНЋГѕЪМжааФЕФбЁдёЗЖЮЇЗХдкИпУмЖШЧјЁЃЪзЯШдкИпУмЖШЧјбЁдёЯрОрзюдЖЕФСНИібљБОЕузїЮЊОлРрЕФГѕЪМжааФЕуЃЌдйевГігыетСНИіЕуЕФОрРыжЎКЭзюДѓЕФЕузїЮЊЕк3ИіГѕЪМжааФЃЌгаСЫЕк3ИіГѕЪМжааФЃЌЭЌбљевЕНгывбгаЕФШ§ИіГѕЪМОлРржааФОрРыКЭзюдЖЕФЕузїЮЊЕк4ИіГѕЪМжааФЃЌвдДЫРрЭЦЃЌжБЕНдкИпУмЖШЧјНЋkИіОлРржааФЖМевГіРДЮЊжЙЁЃ
ЫуЗЈУшЪігыВНжшЃК
ЪфШыЃКАќКЌnИіЖдЯѓЕФЪ§ОнМЏЃЌДиРрЪ§ФПkЃЛ
ЪфГіЃКkИіГѕЪМОлРржааФЁЃ
ЃЈ1ЃЉМЦЫуnИіЪ§ОнбљБОжаУПИіЖдЯѓxЕФЕФУмЖШЃЌЕБТњзуКЫаФЖдЯѓЕФЬѕМўЪБЃЌНЋИУЖдЯѓМгЕНИпУмЖШЧјгђDжаШЅЃЛ
ЃЈ2ЃЉдкЧјгђDжаМЦЫуСНСНЪ§ОнбљБОМфЕФОрРыЃЌевЕНМфОрзюДѓЕФСНИібљБОЕузїЮЊГѕЪМОлРржааФЃЌМЧЮЊЃЛ
ЃЈ3ЃЉдйДгЧјгђDжаевГіТњзуЬѕМўЃКЕФЕуЃЌНЋзїЮЊЕкШ§ИіГѕЪМОлРржааФЃЛ
ЃЈ4ЃЉШдШЛДгЧјгђDжаевГіТњзуЕНЧАУцШ§ИіОлРржааФЕФОрРыКЭзюДѓЕФЕуЃЛ
ЃЈ5ЃЉАДееЭЌбљЕФЗНЗЈНјааЯТШЅЃЌжБЕНевЕНЕкkИіГѕЪМОлРржааФЃЌНсЪјЁЃ
#ЪзЯШдкИпУмЖШЧјбЁдёЯрОрзюдЖЕФСНИібљБОЕузїЮЊОлРрЕФГѕЪМжааФЕуЃЌдйевГігыетСНИіЕуЕФОрРыжЎКЭзюДѓЕФЕузїЮЊЕк3ИіГѕЪМжааФЃЌ dd=dist(data) dd=as.matrix(dd) #ИпУмЖШЧјгђ D=which(dd<max(dd)/6 & dd!=0,arr.ind = T) D=unique(D[,1]) dataD=data[D,] index=0 for(i in 1:k){ index[i]=as.numeric(row.names(which (
ЯрЫЦадЖШСПЕФИФНј
дкЧАУцШЗЖЈСЫkжЕвдМАkИіГѕЪМОлРржааФКѓЃЌжЛвЊдйШЗЖЈЯрЫЦадЖШСПМДПЩЕУЕНОлРрНсЙћЁЃШЛЖјДЋЭГЕФK-meansОлРрВЩгУХЗЪЯОрРызїЮЊЯрЫЦадЖШСПЃЌетжжЗНЗЈУЛгаКмКУЕиПМТЧЕНЦфЪЕУПИіЪ§ОнбљБОЖдОлРрНсЙћЕФгАЯьПЩФмЪЧВЛЭЌЕФЃЌвЛТЩВЩгУХЗЪЯОрРыНјааЯрЫЦадКтСПЖдОлРрНсЙћЛсВњЩњНЯДѓгАЯьЁЃФЧУДЃЌЮвУЧШчЙћИљОнЪ§ОнбљБОЕФживЊадЖдЦфИГгшвЛИіШЈжЕЃЌОЭЛсМѕаЁЙТСЂЕуЕШвЛаЉвђЫиЖдОлРрЕФгАЯьЃЌетжжИФНјЕФЖШСПЗНЗЈЮвУЧГЦжЎЮЊМгШЈХЗЪЯОрРыЁЃ
###ИљОнИФНјКѓЕФМгШЈХЗЪЯОрРыЙЋЪН ## МьбщОлРрВйзїЪЧЗёашвЊНсЪјЃЌИФНјКѓЕФМгШЈзМдђКЏЪ§ЙЋЪНЃКЕФжЕзюаЁЛђБЃГжВЛБфСЫ sqrt(sum((c1$Centers/(sum(c1$Centers)/len
ЛцжЦОлРржааФКЭПЩЪгЛЏ
lot(data[,-c(1:4)], fit$cluste

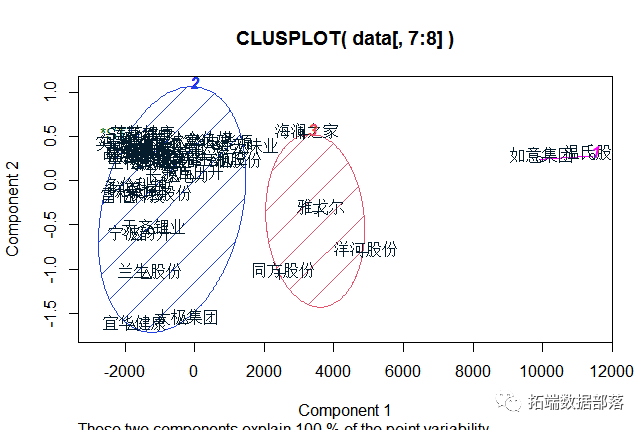
ЪфГіОлРрНсЙћКЭОлРржааФ
###########################ОлРрРрБ№############### fit$Clusters ###########################ОлРржааФ######################### fit$Centers


