ЮЪЬтвЛЃКЧыЮЪДѓЪ§ОнМЦЫуMaxCompute sparkв§ЧцЮЊЪВУДЖСВЛЕНmaxcomputeЩЯУцЕФБэФиЃП
ЧыЮЪДѓЪ§ОнМЦЫуMaxCompute sparkв§ЧцЮЊЪВУДЖСВЛЕНmaxcomputeЩЯУцЕФБэФиЃПЪЧЮвТЉХфжУСЫЪВУДВЮЪ§УДЃП 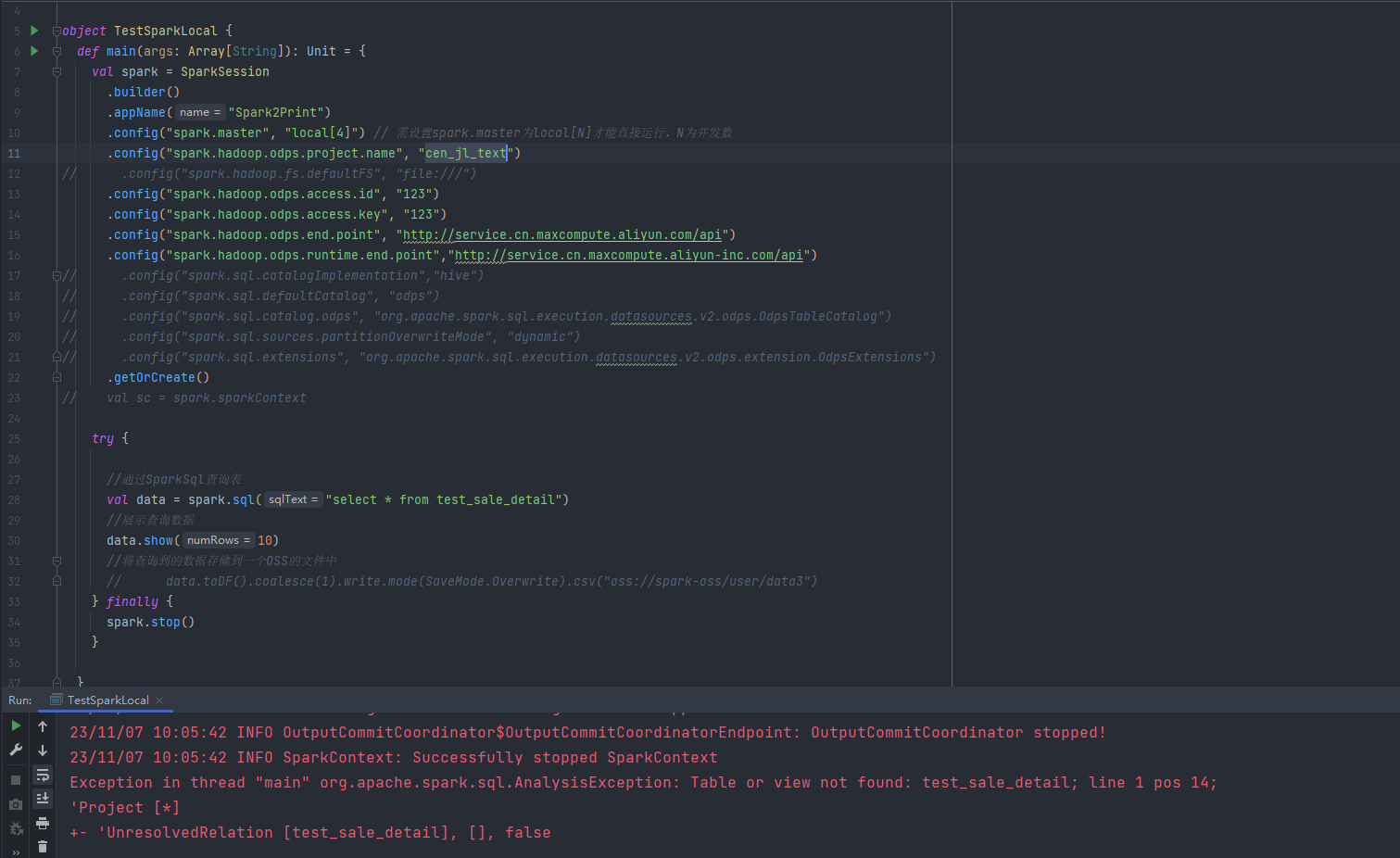
ВЮПМД№АИЃК
ЙигкБОЮЪЬтЕФИќЖрЛиД№ПЩЕуЛїНјааВщПДЃК
ЮЪЬтЖўЃКДѓЪ§ОнМЦЫуMaxComputeЮветБпЯыИќИФзжЖЮГЄЖШ БЈДэСЫЃП
ДѓЪ§ОнМЦЫуMaxComputeЮветБпЯыИќИФзжЖЮГЄЖШ га varhcar(32) ИФЮЊ string БЈДэСЫЃП 
ВЮПМД№АИЃК
аТНЈвЛеХБэЃЌИДжЦЙ§ШЅЁЃ2ЃКПЊЦєddlБфИќ
ЙигкБОЮЪЬтЕФИќЖрЛиД№ПЩЕуЛїНјааВщПДЃК
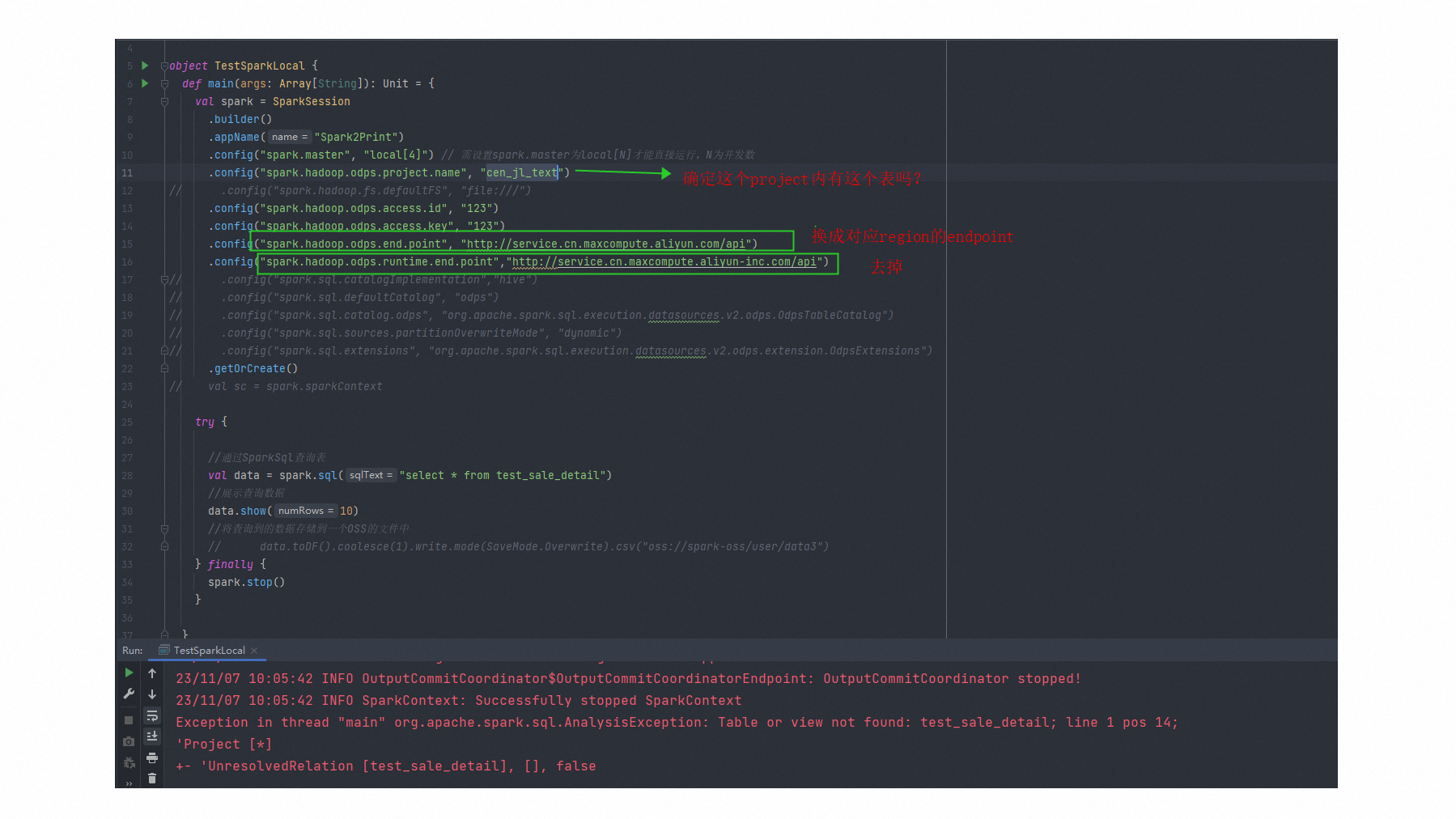
ЮЪЬтШ§ЃКгіЕНвЛИіBugЃЌДѓЪ§ОнМЦЫуMaxComputeгУJava-sdkЗНЪНДДНЈЕФКЏЪ§ЛсБЈДэевВЛЕНЮФМўзЪдДЃП
гіЕНвЛИіBugЃЌДѓЪ§ОнМЦЫуMaxComputeгУJava-sdkЗНЪНДДНЈЕФКЏЪ§ЛсБЈДэевВЛЕНЮФМўзЪдДЃП 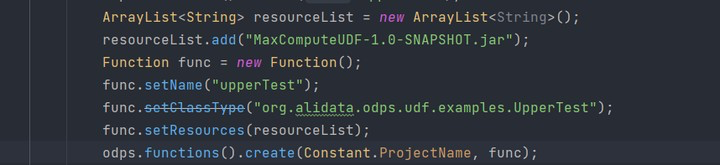

ЕЋЪЧгУетШ§жжЗНЪНДДНЈЕФздЖЈвхКЏЪ§ЖМЪЧе§ГЃЕФ
ВЮПМД№АИЃК
гУsdkЕФЗНЪННЈКУЕФКЏЪ§ЃЌБЈДэевВЛЕНзЪдДЃЌзХМБгУЕФЛАЯШгУSQLЕФЗНЪНДЋвЛЯТАЩЁЃ
ЮвгУФуНиЭМжаЕФДњТыЪдСЫЯТЃЌПЩвдгУЁЃвЊВЛФудйМьВщЯТВНжшЁЃЦфжагУЕНЕФjarАќЃЌашвЊЬсЧАЩЯДЋЕНprojectРяЁЃ 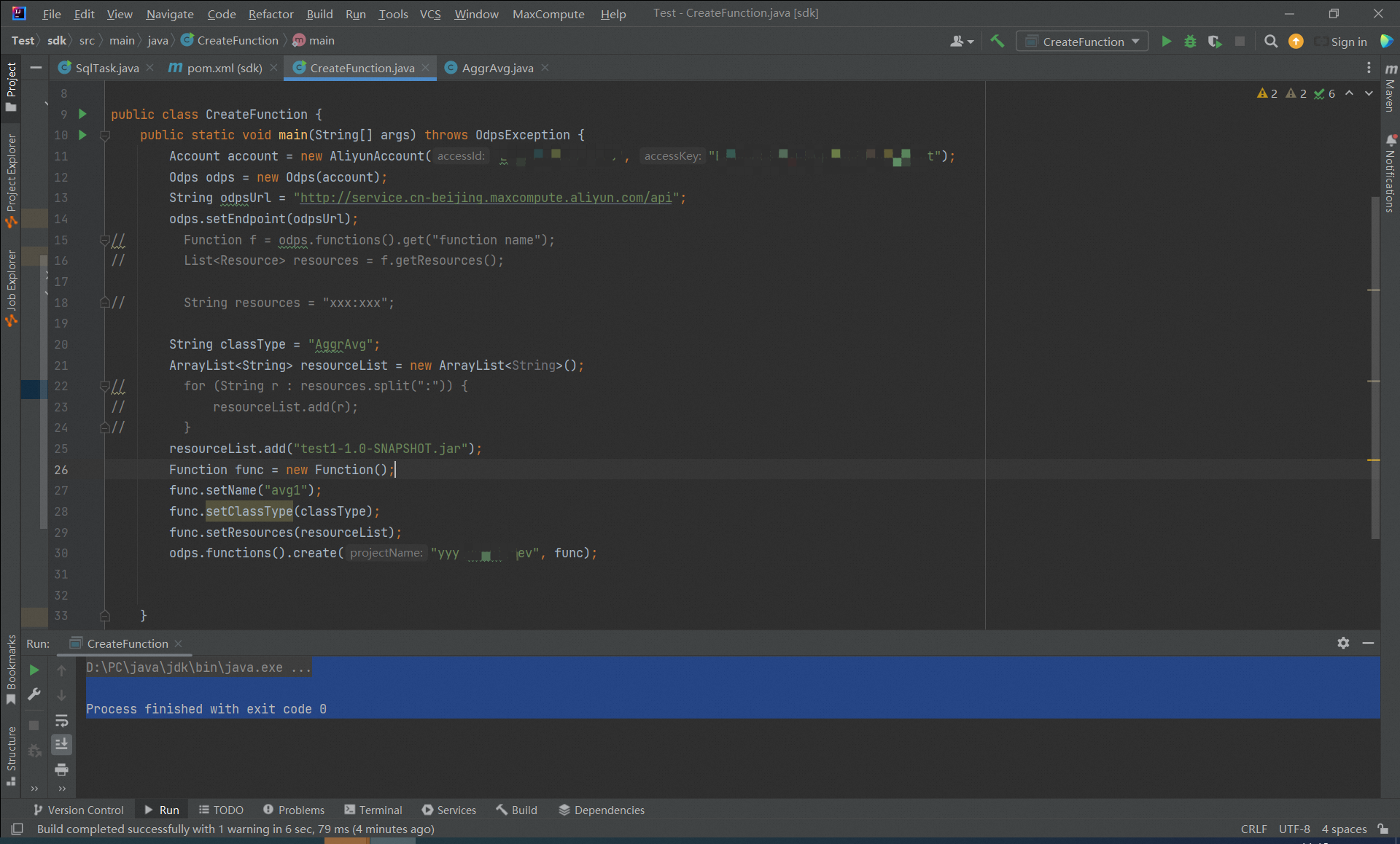

ЙигкБОЮЪЬтЕФИќЖрЛиД№ПЩЕуЛїНјааВщПДЃК
ЮЪЬтЫФЃКDataWorks MaxComputeгУJava-sdkЗНЪНДДНЈЕФКЏЪ§ЛсБЈДэевВЛЕНЮФМўзЪдДЃП
DataWorksгІИУЪЧИіBugЃЌMaxComputeгУJava-sdkЗНЪНДДНЈЕФКЏЪ§ЛсБЈДэевВЛЕНЮФМўзЪдДЃП 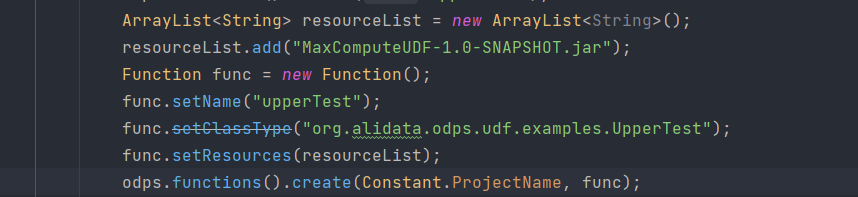

гУетШ§жжЗНЪНДДНЈЕФздЖЈвхКЏЪ§ЖМЪЧе§ГЃЕФ
ВЮПМД№АИЃК
дкЪЙгУMaxComputeЕФJava SDKДДНЈКЏЪ§ЪБЃЌШЗЪЕЛсГіЯжевВЛЕНЮФМўзЪдДЕФЧщПіЁЃетПЩФмЪЧвђЮЊMaxComputeФПЧАВЛжЇГжЖЏЬЌЩЯДЋЮФМўзїЮЊзЪдДЃЌЫљвдФњашвЊдкПЊЗЂЙ§ГЬжаНЋзЪдДЮФМўЩЯДЋжСOSSжаЃЌШЛКѓдкДДНЈКЏЪ§ЕФЪБКђЃЌАбossСДНгвВвЛЦ№ДЋНјШЅЁЃ
СэЭтЃЌФњЛЙПЩвдГЂЪдЪЙгУmaxcompute cliУќСюааЙЄОпЩЯДЋЮФМўЃЌВЂНЋЮФМўЕижЗзїЮЊзЪдДв§гУЁЃ
ЙигкБОЮЪЬтЕФИќЖрЛиД№ПЩЕуЛїНјааВщПДЃК
ЮЪЬтЮхЃКDataWorksжаmaxcomputeДДНЈСЫздЖЈвхКЏЪ§ЃЌдкЪЙгУЕФЪБКђБЈДэЃКЮоЗЈМгди ЃП
DataWorksжаmaxcomputeДДНЈСЫздЖЈвхКЏЪ§ЃЌдкЪЙгУЕФЪБКђБЈДэЃКЮоЗЈМгди ЃП
ВЮПМД№АИЃК
дкDataWorksжаЃЌЪЙгУздЖЈвхКЏЪ§ЪБПЩФмЛсГіЯжЁАЮоЗЈМгдиЁБЕФДэЮѓЃЌвдЯТЪЧМИИіГЃМћЕФдвђЃК
- КЏЪ§ТЗОЖДэЮѓЃКЧыШЗБЃФњдкSQLгяОфжаЪЙгУСЫе§ШЗЕФздЖЈвхКЏЪ§УћГЦКЭТЗОЖЁЃ
- КЏЪ§вРРЕШБЪЇЃКШЗБЃФњЩЯДЋЕФздЖЈвхКЏЪ§ЕФЫљгавРРЕЯюЖМвбдкдЊЪ§ОнДцДЂЗўЮёЃЈMRSЃЉжаЃЌВЂдкНХБОжае§ШЗв§гУЫќУЧЁЃ
- здЖЈвхКЏЪ§вбНћгУЃКЧыШЗШЯздЖЈвхКЏЪ§вбБЛЦєгУЁЃФњПЩвдНјШыЪ§ОнЙЄГЬвГУцЃЌевЕНздЖЈвхКЏЪ§ЃЌВЂЕЅЛїЁАЦєгУЁБЁЃ
ЙигкБОЮЪЬтЕФИќЖрЛиД№ПЩЕуЛїНјааВщПДЃК
