ЮЪЬтвЛЃКDataWorksжиаТЪдСЫвЛЯТСЌЯпЕФЗНЪН вВЪЧВЛаа ЃП
DataWorksжиаТЪдСЫвЛЯТСЌЯпЕФЗНЪН вВЪЧВЛаа ЃП 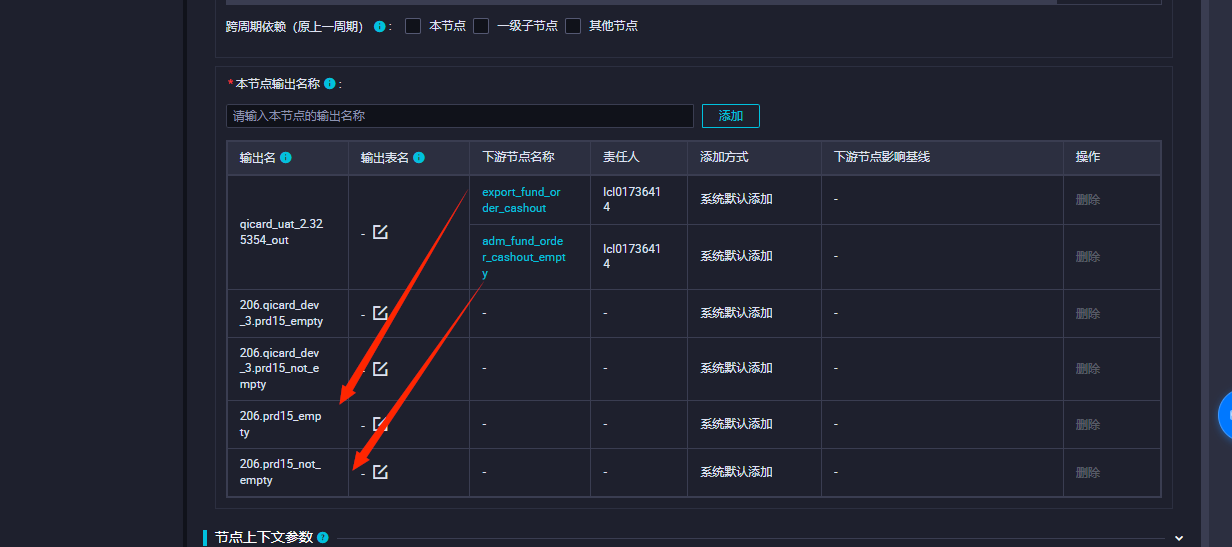
етСНИіSQLНХБОУЛгажИЯђЗжжЇЕФЪфГі
ВЮПМЛиД№ЃК
- МьВщЪ§ОндДЃКШЗБЃФњЕФЪ§ОндДе§ШЗХфжУЃЌВЂЧвАќКЌЫљашЕФЪ§ОнЁЃФњПЩвддкDataWorksПижЦЬЈжаВщПДКЭЙмРэЪ§ОндДЁЃ
- МьВщВщбЏгяОфЃКШЗБЃФњЕФВщбЏгяОфе§ШЗБраДЃЌВЂЧвФмЙЛДгЪ§ОндДжаМьЫїЕНЫљашЕФЪ§ОнЁЃ
- МьВщСЌНгХфжУЃКШЗБЃФњЕФСЌНгХфжУе§ШЗЃЌАќРЈЪ§ОнПтРраЭЁЂгУЛЇУћЁЂУмТыЕШаХЯЂЁЃ
- ВщПДШежОЃКDataWorksЛсЩњГЩЯъЯИЕФШежОЮФМўЃЌФњПЩвдВщПДетаЉШежОвдЛёШЁИќЖрЙигкЮЪЬтЕФЯъЯИаХЯЂЁЃ
ЙигкБОЮЪЬтЕФИќЖрЛиД№ПЩЕуЛїдЮФВщПДЃК/ask/571118
ЮЪЬтЖўЃКdataworks ЭЌВНesЪ§ОнЕНmaxcompute етИіБЈДэЪЧЪВУДЮЪЬтЃП
dataworks ЭЌВНesЪ§ОнЕНmaxcompute етИіБЈДэЪЧЪВУДЮЪЬтЃПexception occursЃКpath=[/di/getTableColumn]ЃЌremoteMessage=[ЛёШЁБэСааХЯЂЪЇАмЃЁ: index type is need! Ъ§ОндДУћ: es_prod зЪдДзщ: ytam_dataworks_job_01 . Error code: GET_TABLE_COLUMN_INFO_ERROR]
ВЮПМЛиД№ЃК
ДгФњЬсЙЉЕФДэЮѓЯћЯЂРДПДЃЌЁАexception occursЃКpath=[/di/getTableColumn]ЃЌremoteMessage=[ЛёШЁБэСааХЯЂЪЇАмЃЁ: index type is need! Ъ§ОндДУћ: es_prod зЪдДзщ: ytam_dataworks_job_01 . Error code: GET_TABLE_COLUMN_INFO_ERROR]ЁБГіЯжЕФдвђПЩФмЪЧЃК
- Ъ§ОндДЫїв§РраЭВЛе§ШЗЃКгЩгкДэЮѓЯћЯЂжаЬсЕНЁАindex type is needЁБЃЌвђДЫПЩФмГіЯжЮЪЬтЪЧЪ§ОндДЫїв§РраЭУЛгаЩшжУе§ШЗЃЌгІШЗШЯЫїв§РраЭЕФЩшжУЪЧЗёе§ШЗЁЃ
- ЛёШЁБэСааХЯЂЪЇАмЃКгЩгкДэЮѓЯћЯЂжаЬсЕНЁАЛёШЁБэСааХЯЂЪЇАмЃЁЁБЃЌвђДЫПЩФмГіЯжЮЪЬтЪЧЮоЗЈДг Elasticsearch Ъ§ОндДжае§ШЗЛёШЁБэСааХЯЂЃЌгІМьВщ DataWorks КЭ Elasticsearch жЎМфЕФСЌНгзДЬЌвдМАЯрЙиХфжУЪЧЗёе§ШЗЁЃ
- зЪдДзщХфжУЮЪЬтЃКгЩгкДэЮѓЯћЯЂжаЬсЕНСЫОпЬхЕФзЪдДзщУћГЦЁАytam_dataworks_job_01ЁБЃЌвђДЫПЩФмДцдкЮЪЬтЪЧгыЬиЖЈзЪдДзщЯрЙиЕФХфжУГіЯжЮЪЬтЃЌгІМьВщзЪдДзщЕФЩшжУКЭШЈЯоЗжХфЁЃ
ЮЊСЫаоИДДЫЮЪЬтЃЌНЈвщФњЃК
- ШЗШЯЪ§ОндДЫїв§РраЭЩшжУе§ШЗЁЃ
- МьВщ DataWorks КЭ Elasticsearch жЎМфЕФСЌНгзДЬЌКЭЯрЙиХфжУЁЃ
- МьВщжИЖЈзЪдДзщЕФЯрЙиХфжУКЭШЈЯоЗжХфЁЃ
ЙигкБОЮЪЬтЕФИќЖрЛиД№ПЩЕуЛїдЮФВщПДЃК/ask/571117
ЮЪЬтШ§ЃКDataWorksетИівГУцОГЃЮоЯьгІЃЌЪЧЮЊЩЖЃП
DataWorksетИівГУцОГЃЮоЯьгІЃЌЪЧЮЊЩЖЃП 
ВЮПМЛиД№ЃКchromeЩ§МЖзюаТАц ЮоКлФЃЪНвВЛсгаетИіЮЪЬтТ№ ЛђепЧаЛЛвЛЯТЭјТчЛЗОГЪдЪд
ЙигкБОЮЪЬтЕФИќЖрЛиД№ПЩЕуЛїдЮФВщПДЃК/ask/570941
ЮЪЬтЫФЃКDataWorksетЪЧЪВУДвтЫМЃП
DataWorksетЪЧЪВУДвтЫМЃП 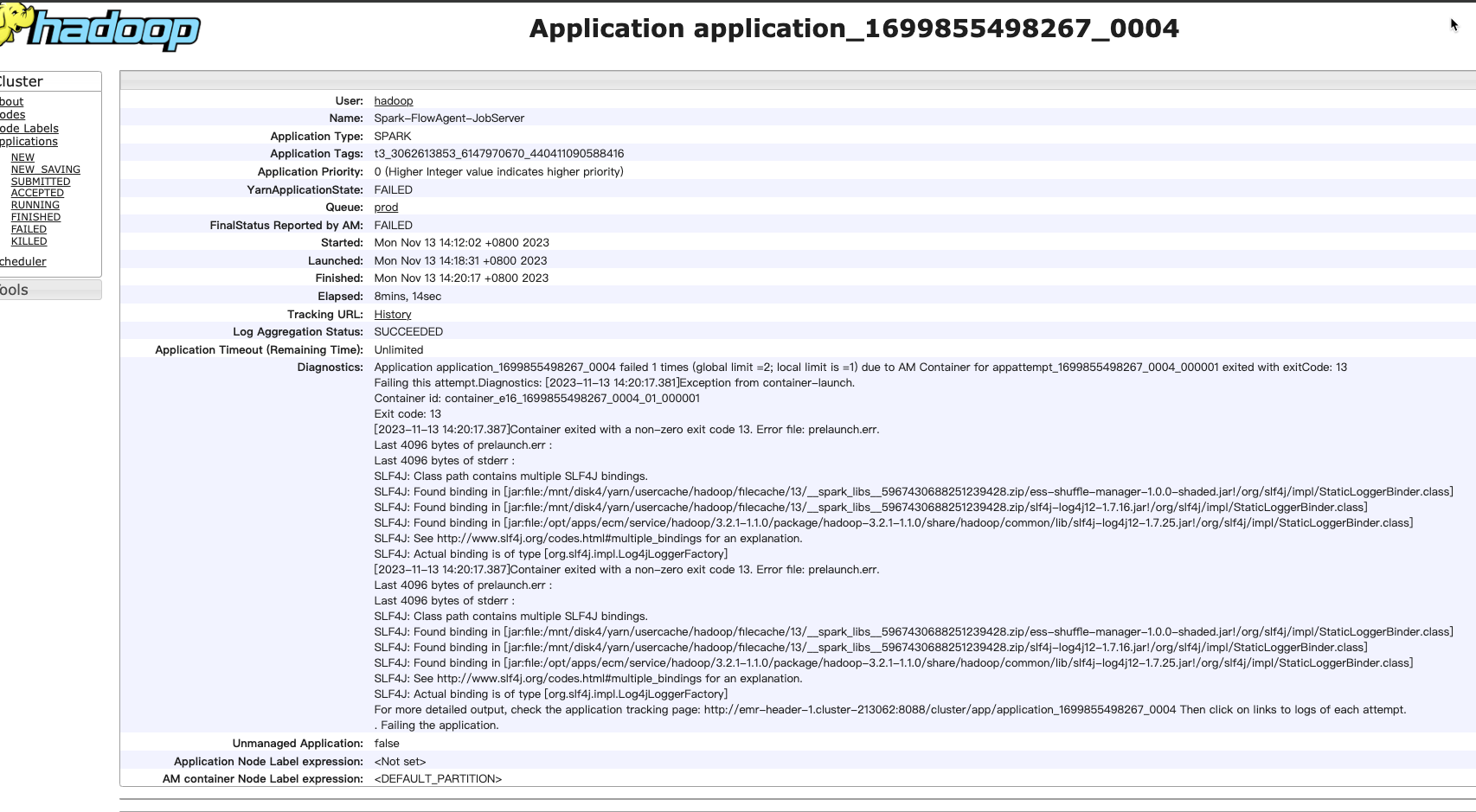
ВЮПМЛиД№ЃК
етИіДэЮѓаХЯЂБэЪОдкдЫааDataWorksШЮЮёЪБЃЌгІгУГЬађгіЕНСЫЮЪЬтЁЃОпЬхРДЫЕЃЌЫќЪЧвђЮЊSLF4JЃЈSimple Logging Facade for JavaЃЉРрТЗОЖжаДцдкЖрИіSLF4JАѓЖЈЃЌЕМжТЮоЗЈШЗЖЈЪЙгУФФИіАѓЖЈЁЃЮЊСЫНтОіетИіЮЪЬтЃЌФуашвЊМьВщФуЕФЯюФПжаЪЧЗёгаЖрИіSLF4JАѓЖЈЃЌВЂШЗБЃжЛгавЛИіАѓЖЈБЛЪЙгУЁЃ
ФуПЩвдГЂЪдвдЯТЗНЗЈРДНтОіетИіЮЪЬтЃК
- МьВщЯюФПЕФвРРЕЙиЯЕЃЌШЗБЃжЛгавЛИіSLF4JАѓЖЈБЛв§ШыЁЃШчЙћгаЖрИіАѓЖЈЃЌЧыЩОГ§ВЛашвЊЕФАѓЖЈЁЃ
- ШчЙћЪЙгУЕФЪЧMavenЛђGradleЕШЙЙНЈЙЄОпЃЌПЩвддкЯюФПЕФХфжУЮФМўжажИЖЈЪЙгУЬиЖЈЕФSLF4JЪЕЯжЁЃР§ШчЃЌШчЙћФуЪЙгУЕФЪЧMavenЃЌПЩвддкpom.xmlЮФМўжаЬэМгвдЯТХфжУЃК
<dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>1.7.30</version> </dependency>
ШЛКѓЃЌдкФуЕФДњТыжаЪЙгУSLF4J APIЪБЃЌШЗБЃЪЙгУе§ШЗЕФШежОМЧТМЦїЙЄГЇЁЃР§ШчЃЌШчЙћФуЪЙгУЕФЪЧLog4jзїЮЊSLF4JЕФЪЕЯжЃЌПЩвдЪЙгУвдЯТДњТыЃК
import org.slf4j.Logger; import org.slf4j.LoggerFactory; public class MyClass { private static final Logger logger = LoggerFactory.getLogger(MyClass.class); public void myMethod() { logger.info("This is an info message"); } }
- ШчЙћЮЪЬтШдШЛДцдкЃЌПЩвдГЂЪдЧхРэЯюФПВЂжиаТЙЙНЈЁЃетПЩвдШЗБЃЫљгаЕФвРРЕЙиЯЕЖМБЛе§ШЗНтЮіЃЌВЂЧвУЛгаГхЭЛЕФАѓЖЈЁЃ
ЙигкБОЮЪЬтЕФИќЖрЛиД№ПЩЕуЛїдЮФВщПДЃК/ask/570895
ЮЪЬтЮхЃКDataWorksетЪЧЪВУДдвђбНЃП
DataWorksетЪЧЪВУДдвђбНЃП 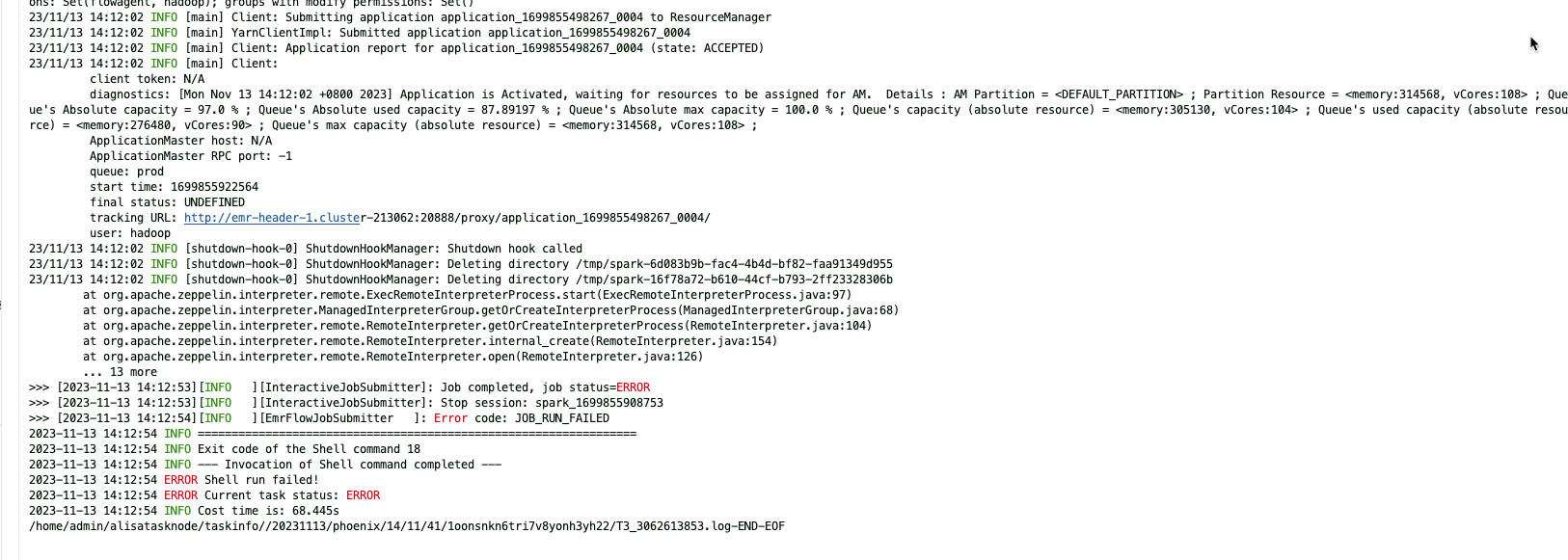
ВЮПМЛиД№ЃК
ЗНБужБНгдкМЏШКЩЯжДаавЛЯТ ЬсНЛетИіsparkШЮЮё ЛГвЩашвЊemrЭЌбЇАяУІПДЯТ
ЙигкБОЮЪЬтЕФИќЖрЛиД№ПЩЕуЛїдЮФВщПДЃК/ask/570888

