在人工智能领域,处理极长输入序列的能力对于构建高效的大型语言模型至关重要。然而,由于单个GPU的内存限制,传统的序列并行(Sequence Parallelism, SP)方法在处理超长序列时面临着效率和可用性的挑战。为了克服这一限制,研究者们提出了一种新的线性注意力序列并行(Linear Attention Sequence Parallel, LASP)方法,旨在为线性注意力机制的语言模型提供高效的序列并行策略。
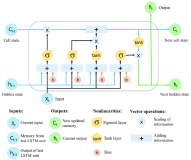
LASP的核心优势在于其针对线性注意力机制的优化设计。通过精心设计的点对点(Point-to-Point, P2P)通信机制,LASP能够充分利用线性注意力的右乘核技巧(right-product kernel trick),显著降低了序列并行的通信开销。此外,LASP通过内核融合(kernel fusion)和中间状态缓存(intermediate state caching)等系统工程优化,提高了在GPU集群上的执行效率。LASP还与各种批处理级别的数据并行(Data Parallel, DDP)方法兼容,这对于在大型集群上进行分布式训练至关重要。
LASP的提出,不仅为线性注意力模型提供了一种新的序列并行策略,而且在保持或提升模型性能的同时,显著提高了处理极长序列的能力。实验结果表明,LASP能够在128个A100 80G GPU上将序列长度扩展至4096K,比现有SP方法长8倍,同时在相同的硬件约束下速度更快。这一成果不仅对学术界具有重要意义,也为工业界在实际应用中如何平衡计算效率和模型性能提供了宝贵的参考。
然而,LASP也面临着一些挑战和局限性。首先,LASP的设计依赖于高效的P2P通信机制,这可能会在GPU集群的通信带宽和延迟上提出更高要求。其次,尽管LASP在系统工程方面进行了优化,但在实际部署时,如何确保这些优化措施能够在不同的硬件和软件环境中发挥出预期的效果,仍然是一个需要进一步研究的问题。此外,LASP的实现依赖于特定的线性注意力机制,这意味着它可能不适用于所有类型的语言模型。