БОЮФНЋVQ-VAEзїЮЊЙьМЃЩњГЩЕФЛљДЁФЃаЭЃЌзюжеЕУЕНСЫвЛИіФмИпаЇВЩбљКЭЙцЛЎЃЌВЂЧвдкИпЮЌЖШПижЦШЮЮёЩЯБэЯждЖГЌЦфЫќЛљгкФЃаЭЗНЗЈЕФаТЫуЗЈTAPЃЈTrajectory Autoencoding PlannerЃЉЁЃ
ЩЯЦЊЮФеТЮвУЧНщЩмСЫЛљгк Transformer КЭРЉЩЂФЃаЭЃЈDiffussion ModelЃЉЕФађСаНЈФЃЃЈsequence modellingЃЉЗНЗЈдкЧПЛЏбЇЯАЃЌЬиБ№ЪЧРыЯпСЌајПижЦСьгђЕФгІгУЁЃетЦфжа Trajectory TransformerЃЈTTЃЉКЭ Diffusser ЪєгкЛљгкФЃаЭЕФЙцЛЎаЭЫуЗЈЃЌЫќУЧеЙЯжГіСЫЗЧГЃИпОЋЖШЕФЙьМЃдЄВтвбОКмКУЕФСщЛюадЃЌЕЋЪЧЯрЖдРДЫЕОіВпбгГйвВБШНЯИпЁЃгШЦфЪЧ TT НЋУПИіЮЌЖШЖРСЂРыЩЂЛЏзїЮЊађСажаЕФЗћКХЃЌетЪЙЕУећИіађСаБфЕУЗЧГЃГЄЃЌЖјЧвађСаЩњГЩЕФКФЪБЛсЫцзХзДЬЌКЭЖЏзїЕФЮЌЖШЬсЩ§ПьЫйЩ§ИпЁЃ
ЮЊСЫШУЙьМЃЩњГЩФЃаЭФмБЛДяЕНЪЕгУМЖБ№ЕФОіВпЫйЖШЃЌЮвУЧдкКЭ Diffusser ЦНааЃЈгажиЕўЕЋЪЧгІИУЩдЭэЃЉЕФЪБКђПЊЪМСЫИпаЇЙьМЃЩњГЩгыОіВпЕФЯюФПЁЃЮвУЧЪзЯШЯыЕНЕФЪЧгУСЌајПеМфФкЕФ Transformer+Mixture of Gaussian ЖјЗЧРыЩЂЗжВМРДФтКЯећИіЙьМЃЗжВМЁЃЫфШЛВЛХХГ§ЪЕЯжЩЯЕФЮЪЬтЃЌЕЋЪЧетжжЫМТЗЯТЮвУЧУЛФмЛёЕУвЛИіБШНЯЮШЖЈЕФЩњГЩФЃаЭЁЃЫцКѓЮвУЧГЂЪдСЫ Variational Autoencoder(VAE)ЃЌВЂЧвШЁЕУСЫвЛЖЈЕФЭЛЦЦЁЃВЛЙ§ VAE ЕФжиНЈЃЈreconstructionЃЉОЋЖШВЛЪЧЬиБ№РэЯыЃЌЪЙЕУЯТгЮЕФПижЦБэЯжКЭ TT ЯрВюБШНЯДѓЁЃдкМИТжЕќДњжЎКѓЃЌЮвУЧзюжебЁЖЈСЫ VQ-VAE зїЮЊЙьМЃЩњГЩЕФЛљДЁФЃаЭЃЌзюжеЕУЕНСЫвЛИіФмИпаЇВЩбљКЭЙцЛЎЃЌВЂЧвдкИпЮЌЖШПижЦШЮЮёЩЯБэЯждЖГЌЦфЫќЛљгкФЃаЭЗНЗЈЕФаТЫуЗЈЃЌЮвУЧГЦЮЊ Trajectory Autoencoding PlannerЃЈTAPЃЉЁЃ

- ЯюФПжївГЃКhttps://sites.google.com/view/latentplan
- ТлЮФжївГЃКhttps://arxiv.org/abs/2208.10291
ЙцЛЎаЇТЪгыИпЮЌЯТЕФБэЯж
дкЕЅИі GPU ЯТЃЌTAP ФмЧсЫЩвд 20Hz ЕФОіВпаЇТЪНјаадкЯпОіВпЃЌдкЕЭЮЌЖШЕФ D4RL ШЮЮёжаЯТОіВпбгГйжЛга TT ЕФ 1% зѓгвЁЃИќживЊЕФЪЧЫцзХШЮЮёзДЬЌКЭЖЏзїЮЌЖШ D ЕФдіМгЃЌTT ЕФРэТлОіВпбгГйЛсвдШ§ДЮЗНдіГЄ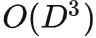 ЃЌDiffusser РэТлЩЯЛсЯпаддіГЄ
ЃЌDiffusser РэТлЩЯЛсЯпаддіГЄ ЃЌЖј TAP ЕФОіВпЫйЖШдђВЛЪмЮЌЖШгАЯь
ЃЌЖј TAP ЕФОіВпЫйЖШдђВЛЪмЮЌЖШгАЯь  ЁЃЖјдкжЧФмЬхЕФОіВпБэЯжЗНУцЃЌЫцзХЖЏзїЮЌЖШдіИпЃЌTAP ЯрЖдгкЦфЫќЗНЗЈЕФБэЯжГіЯжСЫЬсЩ§ЃЌЯрЖдгкЛљгкФЃаЭЗНЗЈЃЈШч TTЃЉЕФЬсЩ§гШЮЊУїЯдЁЃ
ЁЃЖјдкжЧФмЬхЕФОіВпБэЯжЗНУцЃЌЫцзХЖЏзїЮЌЖШдіИпЃЌTAP ЯрЖдгкЦфЫќЗНЗЈЕФБэЯжГіЯжСЫЬсЩ§ЃЌЯрЖдгкЛљгкФЃаЭЗНЗЈЃЈШч TTЃЉЕФЬсЩ§гШЮЊУїЯдЁЃ
ОіВпбгГйЖдОіВпКЭПижЦШЮЮёЕФживЊадЪЧЗЧГЃУїЯдЕФЃЌЯё MuZero етбљЕФЫуЗЈЫфШЛдкФЃФтЛЗОГжаБэЯжгХвьЃЌЕЋЪЧУцЖдЯжЪЕЪРНчжаашвЊЪЕЪБПьЫйЯьгІЕФШЮЮёЃЌЙ§ИпЕФОіВпбгГйОЭЛсГЩЮЊЫќВПЪ№ЕФвЛДѓРЇФбЁЃДЫЭтЃЌдкгЕгаФЃФтЛЗОГЕФЧАЬсЯТЃЌОіВпЫйЖШТ§вВЛсЕМжТРрЫЦЕФЫуЗЈЕФВтЪдГЩБОЦЋИпЃЌЭЌЪББЛдЫгУдкдкЯпЧПЛЏбЇЯАжаЕФГЩБОвВЛсБШНЯИпЁЃ
ДЫЭтЃЌЮвУЧШЯЮЊШУађСаЩњГЩНЈФЃЗНЗЈФмЫГРћРЉеЙЕНЮЌЖШНЯИпЕФШЮЮёЩЯвВЪЧ TAP вЛИіКмживЊЕФЙБЯзЁЃЯжЪЕЪРНчжаЮвУЧЯЃЭћЧПЛЏбЇЯАФмзюжеНтОіЕФЮЪЬтЦфЪЕДѓЖМгаНЯИпЕФзДЬЌКЭЖЏзїЮЌЖШЁЃБШШчЖдгкздЖЏМнЪЛРДЫЕЃЌИїТЗДЋИаЦїЕФЪфШыФФХТОЙ§ИїжжИажЊВуУцЕФдЄДІРэвВВЛЬЋПЩФмаЁгк 100ЁЃИДдгЕФЛњЦїШЫПижЦЭљЭљвВгаКмИпЕФЖЏзїПеМфЃЌШЫРрЕФЫљгаЙиНкздгЩЖШДѓИХЪЧ 240 зѓгвЃЌвВОЭЖдгІСЫжСЩй 240 ЮЌЕФЖЏзїПеМфЃЌвЛИіКЭШЫвЛбљСщЛюЕФЛњЦїШЫвВашвЊЭЌбљИпЮЌЕФЖЏзїПеМфЁЃ

ЫФзщЮЌЖШж№НЅЩ§ИпЕФШЮЮё
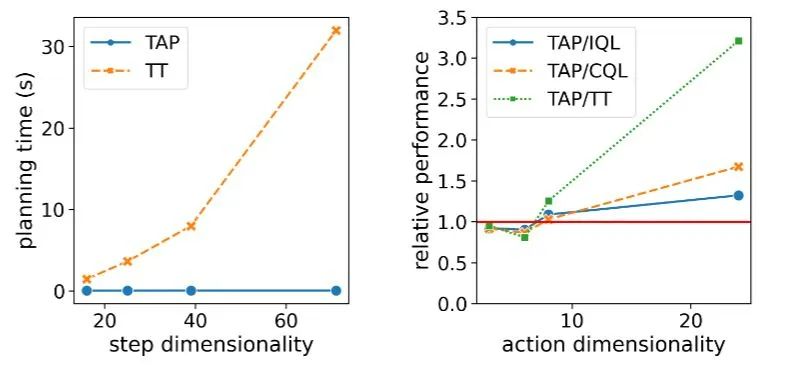
ОіВпбгГйКЭЯрЖдФЃаЭБэЯжЫцзХШЮЮёЮЌЖШдіГЄЕФБфЛЏ
ЗНЗЈИХЪі
ЪзЯШЃЌбЕСЗ VQ-VAE ЕФздБрТыЦї (autoencoders) ВПЗжЃЌетРяКЭдБО VQ-VAE гаСНИіВЛЭЌЁЃЕквЛИіВЛЭЌЪЧБрТыЦїКЭНтТыЦїЖМЪЧЛљгк Causal TransformerЃЌЖјВЛЪЧ CNNЁЃЕкЖўИіВЛЭЌдђЪЧЮвУЧбЇЯАСЫвЛИіЬѕМўИХТЪЗжВМЃЌБЛНЈФЃЕФПЩФмЕФЙьМЃЖМБиаыДгЕБЧАзДЬЌ  ГіЗЂЁЃздБрТыЦїбЇЯАвЛИіДгЕБЧАзДЬЌ
ГіЗЂЁЃздБрТыЦїбЇЯАвЛИіДгЕБЧАзДЬЌ  ПЊЪМЕФЙьМЃКЭвўБрТыЃЈlatent codesЃЉжЎМфЕФЫЋЯђгГЩфЁЃетаЉвўБрТыКЭдБОЙьМЃвЛбљАДЪБМфЫГађХХСаЃЌУПИівўБрТыЛсБЛЖдгІЕНЪЕМЪ
ПЊЪМЕФЙьМЃКЭвўБрТыЃЈlatent codesЃЉжЎМфЕФЫЋЯђгГЩфЁЃетаЉвўБрТыКЭдБОЙьМЃвЛбљАДЪБМфЫГађХХСаЃЌУПИівўБрТыЛсБЛЖдгІЕНЪЕМЪ 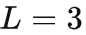 ВНЙьМЃЁЃвђЮЊЮвУЧЪЙгУСЫ Causal TransformerЃЌЪБМфХХЮЛППКѓЕФвўБрТы (Шч
ВНЙьМЃЁЃвђЮЊЮвУЧЪЙгУСЫ Causal TransformerЃЌЪБМфХХЮЛППКѓЕФвўБрТы (Шч  ) ВЛЛсНЋаХЯЂДЋЕНХХЮЛППЧАЕФађСа(Шч
) ВЛЛсНЋаХЯЂДЋЕНХХЮЛППЧАЕФађСа(Шч  )ЃЌетЪЙЕУ TAP ПЩвдЭЈЙ§ЧА N ИівўБрТыВПЗжНтТыГіГЄЖШЮЊ NL ЕФЙьМЃЃЌетдкКѓајгУЫќНјааЙцЛЎЪБЪЧЗЧГЃгагУЕФЁЃ
)ЃЌетЪЙЕУ TAP ПЩвдЭЈЙ§ЧА N ИівўБрТыВПЗжНтТыГіГЄЖШЮЊ NL ЕФЙьМЃЃЌетдкКѓајгУЫќНјааЙцЛЎЪБЪЧЗЧГЃгагУЕФЁЃ
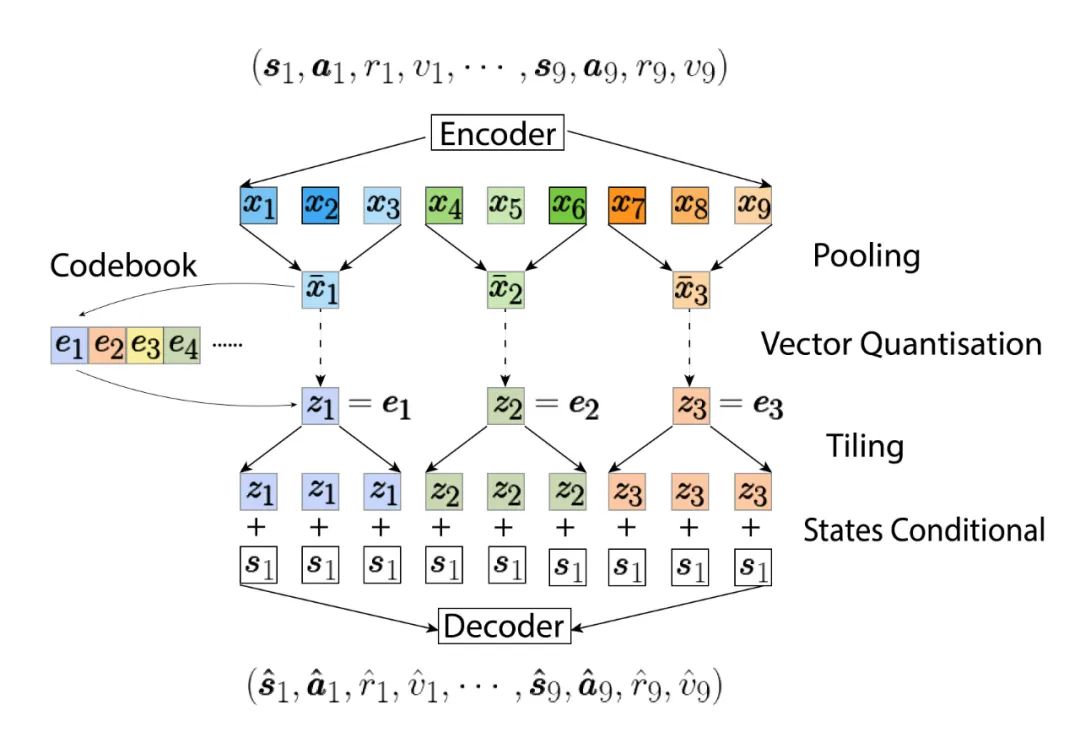
ЫцКѓЮвУЧЛсгУСэвЛИі GPT-2 ЪНЕФ Transformer РДНЈФЃетаЉвўБрТыЕФЬѕМўИХТЪЗжВМ  ЃК
ЃК

дкОіВпЪБЃЌЮвУЧПЩвдЭЈЙ§дквўБфСППеМфФкНјаагХЛЏбАевзюКУЕФЮДРДЙьМЃЃЌЖјВЛЪЧдкдЖЏзїПеМфНјаагХЛЏЁЃвЛИіЗЧГЃМђЕЅЕЋвВФмЦ№аЇЕФЗНЗЈОЭЪЧжБНгДгвўБрТыЕФЗжВМжаНјааВЩбљЃЌШЛКѓбЁШЁБэЯжзюКУЕФЙьМЃЃЌШчЯТЭМЃК
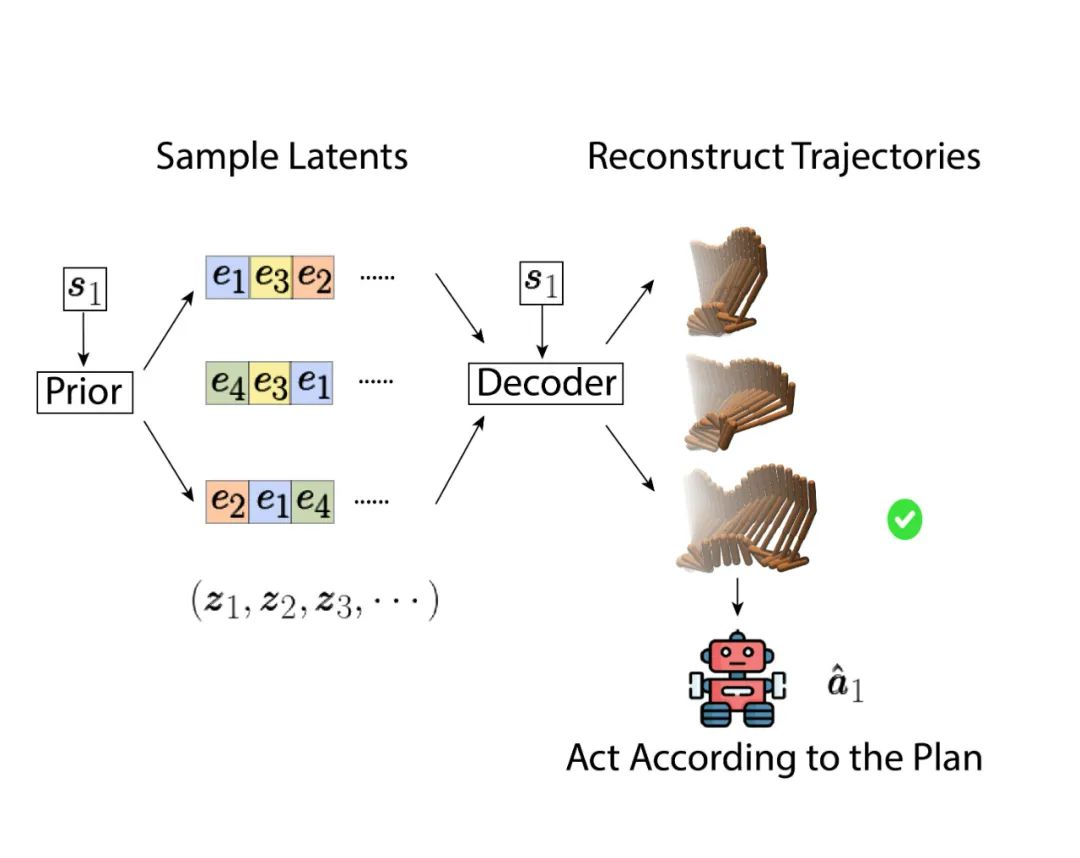
дкбЁдёзюгХЙьМЃЕФЪБКђВЮПМЕФФПБъЗжЪ§ (objective score) ЛсЭЌЪБПМТЧЙьМЃЕФдЄЦкЪевцЃЈНБРјМгзюКѓвЛВНЕФЙРжЕЃЉКЭетЬѕЙьМЃБОЩэЕФПЩааадЛђепЫЕИХТЪЁЃШчЯТУцетИіЙЋЪНЃЌЦфжа  ЪЧвЛИідЖДѓгкзюИп return ЕФЪ§ЃЌЕБЙьМЃЕФИХТЪИпгквЛИіуажЕ
ЪЧвЛИідЖДѓгкзюИп return ЕФЪ§ЃЌЕБЙьМЃЕФИХТЪИпгквЛИіуажЕ ЃЌЦРХаетЬѕЙьМЃЕФБъзМЛсЪЧЫќЕФдЄЦкЪевцЃЈКьЩЋИпССЃЉЃЌЗёдђетЬѕЙьМЃЕФИХТЪБОЩэНЋЛсЪЧжїЕМВПЗжЃЈРЖЩЋИпССЃЉЁЃвВОЭЪЧЫЕ TAP ЛсдкДѓгкуажЕЕФЙьМЃжабЁдёвЛЬѕдЄЦкЪевцзюИпЕФЁЃ
ЃЌЦРХаетЬѕЙьМЃЕФБъзМЛсЪЧЫќЕФдЄЦкЪевцЃЈКьЩЋИпССЃЉЃЌЗёдђетЬѕЙьМЃЕФИХТЪБОЩэНЋЛсЪЧжїЕМВПЗжЃЈРЖЩЋИпССЃЉЁЃвВОЭЪЧЫЕ TAP ЛсдкДѓгкуажЕЕФЙьМЃжабЁдёвЛЬѕдЄЦкЪевцзюИпЕФЁЃ

ЫфШЛВЩбљЪ§СПзуЙЛДѓСЫвдКѓжБНгВЩбљдкдЄВтађСаНЯЖЬЕФЪБКђаЇЙћвВПЩвдКмКУЃЌдкЯожЦВЩбљЪ§СПКЭЙцЛЎЫљашЕФзмЪБМфЕФЧАЬсЯТЃЌгУИќКУЕФгХЛЏЦїЛЙЪЧЛсДјРДИќКУЕФБэЯжЁЃвдЯТСНИіЖЏЭМеЙЪОСЫЕБвЊдЄВтЮДРД 144 ВНвдКѓгУжБНгВЩбљКЭ beam search ВњЩњЕФЙьМЃЕФЧјБ№ЁЃетаЉЙьМЃБЛАДзюКѓЕФФПБъЗжЪ§ХХађЃЌдкзюЩЯВузюЧАУцЕФЙьМЃЗжЪ§дНИпЃЌдкБЛЕўдкКѓУцЕФЙьМЃЗжЪ§дНЕЭЁЃСэЭтЗжЪ§ЕЭЕФЙьМЃЭЌЪБЭИУїЖШвВЛсдНЕЭЁЃдкЭМжаЮвУЧПЩвдПДЕНжБНгВЩбљВњЩњЕФЙьМЃКмЖрЖЏЬЌЖМВЛЬЋЮШЖЈвВВЛЬЋЗћКЯЮяРэЙцТЩЃЌгШЦфЪЧБГОАРяБШНЯЕЕФЙьМЃМИКѕЖМЪЧЦЎзХзпЕФЁЃетаЉЖМЪЧИХТЪБШНЯЕЭЕФЙьМЃЃЌдкзюжебЁдёЗНАИЕФЪБКђЛсБЛЬоГ§ЁЃдкзюЧАХХЕФЙьМЃПДЦ№РДЖЏЬЌвЊИќецЪЕвЛаЉЃЌЕЋЪЧЯрЖдгІЕФБэЯжОЭБШНЯВюЃЌЫЦКѕвЊЫЄЕЙСЫЁЃЖјЯрБШжЎЯТЃЌbeam search дкеЙПЊЯТвЛИівўБфСПЕФЪБКђОЭЛсЖЏЬЌПМТЧЙьМЃЕФИХТЪЃЌЪЙЕУИХТЪКмЕЭЕФЗжжЇЛсБЛЬсЧАжеНсЃЌетбљВњЩњЕФКђбЁЙьМЃОЭЖММЏжадкБэЯжНЯКУЖјЧвПЩФмадБШНЯДѓЕФЙьМЃжмЮЇСЫЁЃ

жБНгВЩбљ

Beam search
ЪЕбщНсЙћ
дкУЛгаИќИпМЖЕФЙРжЕвдМАВпТдЬсЩ§ЕФЧщПіЯТЃЌНіНівРППдЄВтОЋЖШЕФгХЪЦЃЌдкЕЭЮЌЖШЕФШЮЮёЩЯ TAP ОЭШЁЕУСЫКЭЦфЫќРыЯпЧПЛЏбЇЯАЯрЕБЕФБэЯжЃК

gym locomotion control
дкИпЮЌЕФШЮЮёЩЯЃЌTAP ШЁЕУСЫдЖГЌЦфЫќЛљгкФЃаЭЕФЗНЗЈЕФБэЯжЃЌЭЌЪБвВЪЄЙ§СЫГЃМћЕФЮоФЃаЭЗНЗЈЁЃетРяЦфЪЕгаСНИіЛЙЮДгаНтД№ЕФПЊЗХадЮЪЬтЁЃЪзЯШЪЧЮЊЪВУДДЫЧАЛљгкФЃаЭЕФЗНЗЈдкетаЉИпЮЌЖШЕФРыЯпЧПЛЏбЇЯАШЮЮёжаБэЯжНЯВюЃЌЦфДЮЪЧЮЊЪВУД TAP дкетаЉШЮЮёЩЯБэЯжгжФмЗДГЌКмЖрЮоФЃаЭЗНЗЈЁЃЮвУЧЕФвЛИіМйЩшЪЧвђЮЊдкИпЮЌЮЪЬтЩЯНјааВпТдгХЛЏгжвЊПМТЧЗРжЙВпТдЦЋРыааЮЊВпТдЬЋЖрЪЧЗЧГЃРЇФбЕФЁЃЕБбЇЯАСЫвЛИіФЃаЭЃЌФЃаЭБОЩэЕФЮѓВюПЩФмЛЙЛсЗХДѓетжжРЇФбЁЃЖј TAP НЋгХЛЏПеМфАсЕНСЫвЛИіКмаЁЕФРыЩЂвўБфСППеМфЃЌетЪЙЕУећИігХЛЏЙ§ГЬЕФТГАєадИќЧПСЫЁЃ

adroit robotic hand control
вЛаЉЧаЦЌбаОП
Ждгк TAP РяУцЕФжюЖрЩшМЦЃЌЮвУЧвВдк gym locomotion control ЕФШЮЮёЩЯзіСЫвЛЯЕСаЧаЦЌбаОПЁЃЪзЯШЪЧУПИівўБрТыЪЕМЪЖдгІЕФЙьМЃЕФВНЪ§ ЃЈЛЦЩЋжљзДЭМЃЉЃЌЪТЪЕжЄУїШУвЛИівўБфСПЖдгІЖрВНзДЬЌзЊвЦВЛЙтгаМЦЫуЩЯЕФгХЪЦЃЌдкзюКѓФЃаЭБэЯжЩЯвВгаЬсЩ§ЁЃЭЈЙ§ЕїНкЫбЫїЕФФПБъКЏЪ§жаДЅЗЂЕЭИХТЪЙьМЃГЭЗЃЕФуажЕ
ЃЈЛЦЩЋжљзДЭМЃЉЃЌЪТЪЕжЄУїШУвЛИівўБфСПЖдгІЖрВНзДЬЌзЊвЦВЛЙтгаМЦЫуЩЯЕФгХЪЦЃЌдкзюКѓФЃаЭБэЯжЩЯвВгаЬсЩ§ЁЃЭЈЙ§ЕїНкЫбЫїЕФФПБъКЏЪ§жаДЅЗЂЕЭИХТЪЙьМЃГЭЗЃЕФуажЕ  ЃЈКьЩЋжљзДЭМЃЉЃЌЮвУЧвВШЗШЯСЫФПБъКЏЪ§жаСНИіВПЗжШЗЪЕЖМЖдФЃаЭзюКѓБэЯжЪЧгаАяжњЕФЁЃСэЭтвЛЕуОЭЪЧЯђЮДРДЙцЛЎЕФВНЪ§ЃЈplanning horizonЃЌРЖЩЋжљзДЭМЃЉЖдФЃаЭБэЯжЕФгАЯьЗДЖјВЛДѓЃЌдкВПЪ№КѓЕФЫбЫїжаФФХТжЛеЙПЊвЛИівўБфСПзюКѓжЧФмЬхЕФБэЯжвВжЛЛсНЕЕЭ 10% зѓгвЁЃ
ЃЈКьЩЋжљзДЭМЃЉЃЌЮвУЧвВШЗШЯСЫФПБъКЏЪ§жаСНИіВПЗжШЗЪЕЖМЖдФЃаЭзюКѓБэЯжЪЧгаАяжњЕФЁЃСэЭтвЛЕуОЭЪЧЯђЮДРДЙцЛЎЕФВНЪ§ЃЈplanning horizonЃЌРЖЩЋжљзДЭМЃЉЖдФЃаЭБэЯжЕФгАЯьЗДЖјВЛДѓЃЌдкВПЪ№КѓЕФЫбЫїжаФФХТжЛеЙПЊвЛИівўБфСПзюКѓжЧФмЬхЕФБэЯжвВжЛЛсНЕЕЭ 10% зѓгвЁЃ
зюКѓЮвУЧГЂЪдСЫжБНгВЩбљЕФЧщПіЯТ TAP ЕФБэЯжЃЈТЬЩЋжљзДЭМЃЉЁЃзЂвтетРяЕФВЩбљЕФбљБОЪ§СПЪЧ 2048 ЖјЩЯУцЕФЖЏЭМРяжЛга 256ЃЌЖјЧвЩЯУцЕФЖЏЭМЪЧЩњГЩСЫЮДРД 144 ВНЕФЙцЛЎЃЌЕЋЪЧЪЕМЪЮвУЧЕФЛљДЁФЃаЭжИЛгЙцЛЎ 15 ВНЁЃНсТлЪЧжБНгВЩбљдкбљБОЪ§СПзуЙЛЕФЧщПіЯТЃЌЧвЙцЛЎТЗОЖВЛГЄЃЌФЧУДжБНгВЩбљвВФмЛёЕУКЭ beam search ЯрНќЕФБэЯжЁЃЕЋЪЧетЪЧДгбЇЕНЕФвўБфСПЬѕМўЗжВМжаВЩбљЕФЧщПіЃЌШчЙћжБНгДгвўБрТыжажБНгЕШИХТЪВЩбљЃЌФЧзюКѓЛЙЪЧЛсБШЭъећЕФ TAP ФЃаЭВюКмЖрЁЃ

ЧаЦЌбаОПЕФНсЙћ