ЮвУЧЬжТлСЫгаЙиБЃЗбТЪжЦЖЈЕФгыЫїХтЦЕТЪФЃаЭгаЙиЕФЙлЕуЁЃгЩгкФПБъЪЧдЄВтРэХтЦЕТЪЃЈвдЦРЙРБЃЯеЗбЫЎЦНЃЉЃЌвђДЫвЛАуНЈвщЪЙгУОЩЪ§ОнРДбЕСЗИУФЃаЭЃЌВЂЪЙгУзюаТЪ§ОнЖдЦфНјааВтЪдЁЃЮЪЬтдкгкИУФЃаЭУЛгаАќКЌШЮКЮЪБМфФЃЪНЁЃ
етРяПМТЧвЛИіМђЕЅЕФЪ§ОнМЏЃЌ
> set.seed(1) > n=50000 > X1=runif(n) > T=sample(2000:2015,size=n,replace=TRUE) > L=exp(-3+X1-(T-2000)/20) > E=rbeta(n,5,1) > Y=rpois(n,L*E) > B=data.frame(Y,X1,L,T,E)
ЦЕТЪгЩВДЫЩЙ§ГЬЩњГЩЃЌОпгавЛИіаБфСПX1ЃЌВЂЧвЮвУЧМйЩшГЪжИЪ§ЫйТЪЁЃдкДЫПМТЧБъзМЯпадЛиЙщЃЌУЛгаШЮКЮЪБМфвђЫигАЯь
> reg=glm(Y~X1+offset(log(E)),data=B, + family=poisson)
ЮвУЧЛЙПЩвдМЦЫуФъЖШОбщЫїХтЦЕТЪ
> u=seq(0,1,by=.01) > v=predict(re > vp=Vectorize(p)(seq(.05,.95,by=.1))
ВЂдкЭЌвЛеХЭМЩЯЛцжЦСНЬѕЧњЯпЃЌ
> plot(seq(.05,.95,by=.1),vp,type="b") > lines(u,exp(v),lty=2,col="red")
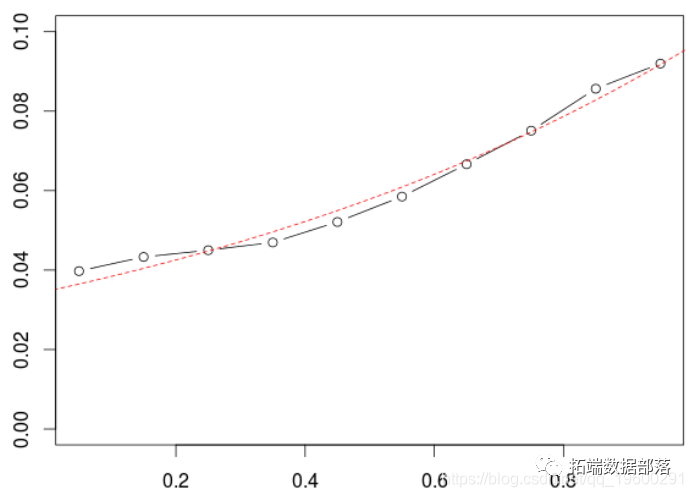
етОЭЪЧЮвУЧЭЈГЃдкМЦСПОМУбЇжаЫљзіЕФЁЃдкЛњЦїбЇЯАжаЃЌИќОпЬхЕиЫЕЃЌЪЧЦРЙРФЃаЭЕФжЪСПвдМАНјааФЃаЭбЁдёЃЌЭЈГЃНЋЪ§ОнМЏЗжЮЊСНВПЗжЁЃбЕСЗбљБОКЭбщжЄбљБОЁЃПМТЧвЛаЉЫцЛњЕФбЕСЗ/бщжЄбљБОЃЌШЛКѓдкбЕСЗбљБОЩЯФтКЯФЃаЭЃЌзюКѓЪЙгУЫќРДНјаадЄВтЃЌ
> idx=sample(1:nrow(B > reg=glm(Y~X1+offset(log(E)),data=B_a, + family=poisson) > u=seq(0,1,by=.01) > v=predict(reg,new $E) + } > vp_a=Vectorize(p)(seq(.05,.95,by=.1)) > plot(seq(.05,.95,by=.1),vp_a,col="blue") > lines(u,exp(v),l X1-x)<.1,] + sum(B$Y)/sum(B$E) + } )(seq(.05,.95,by=.1)) > lines(seq(.05,.95,by=.1),vp_t,col="red")

РЖЩЋЧњЯпЪЧЖдбЕСЗбљБОЕФдЄВтЃЈОЭЯёдкМЦСПОМУбЇжаЫљзіЕФФЧбљЃЉЃЌКьЩЋЧњЯпЪЧЖдВтЪдбљБОЕФдЄВтЁЃ
ЯждкЃЌШчЙћЮвУЧЪЙгУФъЗнзїЮЊЛЎЗжБъзМЃЌЮвУЧНЋОЩЪ§ОнФтКЯЮЊФЃаЭЃЌВЂдкзюНќМИФъЖдЦфНјааВтЪдЃЌ
> B_a=subset( T>=2014) > reg=glm(Y~X1+offset(l + B=B_a[abs(B_a$X1-x)<.1,] + sum(B$Y)/sum(B$E) + } > vp_a=Vectorize(p)( y=.1),vp_a,col="blue") > lines(u,exp(v),lty=2) > p=function(x){ -x)<.1,] + sum(B$Y)/sum(B$E) + } eq(.05,.95,by=.1)) > lines(seq(.05,.95,b=.1),vp_t,

ЯдШЛЃЌНсЙћВЛРэЯыЁЃ
ЮвЛЈСЫвЛаЉЪБМфРДСЫНтбЕСЗКЭбщжЄбљБОЕФЩшМЦЗНЪНЖдНсЙћВњЩњЕФгАЯьЁЃ
ЮвЪЙгУЛиЙщФЃаЭЃК
glm(Y~X1+T+offset(log(E)),data=B, + family=poisson) > u=seq(1999,2016,by=

дкетРяЃЌЮвУЧЪЙгУЯпадФЃаЭЃЌЕЋЪЧЭЈГЃУЛгаРэгЩМйЩшЯпадЁЃЫљвдЮвУЧПЩвдПМТЧбљЬѕ
> reg=glm(Y~X1+bs(T)+offse > u=seq(1999,2016,by=. > v2=predict(reg,newdata= > plot(2000:2015,exp(v2),ty

Г§СЫМйЩшДцдквЛИіЛљБОЕФЦНЛЌКЏЪ§ЃЌЮвУЧПЩвдПМТЧвђзгЕФЛиЙщ
as.factor(T)+ + data=B,family=p g) > u=seq(1999,2016,by=.1) > v=exp(-(u-2000)/20 [2:17]),type="b")

СэвЛжжбЁдёЪЧПМТЧвЛаЉИќЭЈгУЕФФЃаЭЃЌР§ШчЛиЙщЪї
> reg=rpart(Y~X1+T+offset(log(E)),dat > p=function(t){ + B=B[B$T==t,] + mean(predict(reg,newdata=B)) + } 2000:2015) > u=seq(1999,2016,by=.1) > plot(2000:2015,y_m,ylim=c(

дкФъЛЏЦЕТЪЩЯПМТЧгыЗчЯеГЈПкЯрЙиЕФШЈжи
> reg=rpart(Y/E~X1+T,data weights=B$E,cp=1 + B=B[B$T==t,] + B$E=1 + } > y_m=Vectorize(function(t) p(t))( > v=exp(-(u-2000)/20-3+.5) > plot(2000:2015,y_m,ylim=c(.02,.08

ДгЛњЦїбЇЯАЕФНЧЖШРДПДЃЌПМТЧбЕСЗбљБОЃЈЛљгкОЩЪ§ОнЃЉКЭбщжЄбљБОЃЈЛљгкНЯаТЕФбљБОЃЉ
> B_a=subset(B,T<2014) > B_t=subset(B,T>=2014)
ШчЙћЮвУЧПМТЧЪЙгУЙувхЯпадФЃаЭЃЌФЧУДвВКмШнвзЛёЕУНќФъРДЕФдЄВтЃЌ
> reg_a=glm(Y~X1+T+offset(l > C=coefficients(reg_a) > u=seq(1999,20 /20-3) +C[3]*c(2000:2013, + NA,NA)),type="b") ) > points(2014:2015,exp(C

ЕЋЪЧЃЌШчЙћЮвУЧвдФъЗнЮЊвђзгЃЌЮвУЧашвЊЖдбЕСЗбљБОжаУЛгаЕФЫЎЦННјаадЄВтЃЌНсЙћИќМгИДдгЁЃ
> reg_a=glm(Y~0+X1+as.factor(T)+offse > C=coefficients(reg_a) 2014) + A[2]*(B_t$T==2015)) + Y_t=L*B_t$E > i=optim(c(.4,.4),RMSE)$par > plot(2000:2015,c(exp(C[2:15] > lines(u,v,lty=2,col="red") lue")

ЮвУЧНЋRMSEСПЛЏНќФъРДЕФдЄВтЫЎЦНЃЌЪфГіЛЙВЛДэЁЃ
ЛёЕУОЩЪ§ОнЕФбЕСЗЪ§ОнМЏЃЌВЂдкзюНќМИФъЖдЦфНјааВтЪдгІИУНїЩїЪЪЕБЕиПМТЧЪБМфФЃаЭЁЃ