зюНќЃЌЮвУЧЪЙгУвўТэЖћПЩЗђФЃаЭПЊЗЂСЫвЛжжНтОіЗНАИЃЌВЂБЛвЊЧѓНтЪЭетИіЗНАИЁЃ
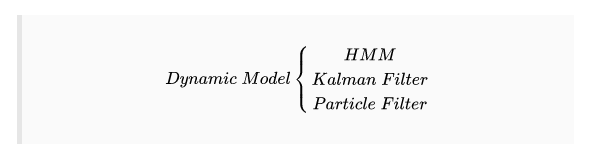
HMMгУгкНЈФЃЪ§ОнађСаЃЌЮоТлЪЧДгСЌајИХТЪЗжВМЛЙЪЧДгРыЩЂИХТЪЗжВМЕУГіЕФЁЃЫќУЧгызДЬЌПеМфКЭИпЫЙЛьКЯФЃаЭЯрЙиЃЌвђЮЊЫќУЧжМдкЙРМЦв§Ц№ЙлВтЕФзДЬЌЁЃзДЬЌЪЧЮДжЊЛђЁАвўВиЁБЕФЃЌВЂЧвHMMЪдЭМЙРМЦзДЬЌЃЌРрЫЦгкЮоМрЖНОлРрЙ§ГЬЁЃ
Р§зг
дкНщЩмHMMБГКѓЕФЛљБОРэТлжЎЧАЃЌетРягавЛИіЪОР§ЃЌЫќНЋАяжњФњРэНтКЫаФИХФюЁЃгаСНИіїЛзгКЭвЛЙоШэЬЧЁЃBжРїЛзгЃЌШчЙћзмЪ§Дѓгк4ЃЌЫћЛсФУМИПХШэЬЧдйжРвЛДЮЁЃШчЙћзмЪ§ЕШгк2ЃЌдђЫћФУМИАбШэЬЧЃЌШЛКѓНЋїЛзгНЛИјAЁЃЯждкИУТжЕНAжРїЛзгСЫЁЃШчЙћЫ§ЕФжРїЛДѓгк4ЃЌЫ§ЛсГдвЛаЉШэЬЧЃЌЕЋЪЧЫ§ВЛЯВЛЖКкЩЋЕФЦфЫћбеЩЋЃЈСНМЋЗжЛЏЕФПДЗЈЃЉЃЌвђДЫЮвУЧЯЃЭћBЛсБШAЖрЁЃЫћУЧетбљзіжБЕНЙозгПеСЫЁЃ
ЯждкМйЩшAКЭBдкВЛЭЌЕФЗПМфРяЃЌЮвУЧПДВЛЕНЫдкжРїЛзгЁЃШЁЖјДњжЎЕФЪЧЃЌЮвУЧжЛжЊЕРКѓРДГдСЫЖрЩйШэЬЧЁЃЮвУЧВЛжЊЕРбеЩЋЃЌНіЪЧДгЙозгжаШЁГіЕФШэЬЧЕФзюжеЪ§СПЁЃЮвУЧдѕУДжЊЕРЫжРїЛзгЃПHMMЁЃ
дкДЫЪОР§жаЃЌзДЬЌЪЧжРїЛзгЕФШЫЃЌAЛђBЁЃЙлВьНсЙћЪЧИУЛиКЯжаГдСЫЖрЩйШэЬЧЁЃШчЙћИУжЕаЁгк4ЃЌїЛзгЕФжРїЛКЭЭЈЙ§їЛзгЕФЬѕМўОЭЪЧзЊвЦИХТЪЁЃгЩгкЮвУЧзщГЩСЫетИіЪОР§ЃЌЮвУЧПЩвдзМШЗЕиМЦЫуГізЊвЦИХТЪЃЌМД1/12ЁЃУЛгаЬѕМўЫЕзЊвЦИХТЪБиаыЯрЭЌЃЌР§ШчAжРїЛзг2ЪБПЩвдНЋїЛзгвЦНЛИјЫћЃЌР§ШчЃЌИХТЪЮЊ1/36ЁЃ
ФЃФт
ЪзЯШЃЌЮвУЧНЋФЃФтИУЪОР§ЁЃBЦНОљвЊГд12ПХШэЬЧЃЌЖјAдђашвЊ4ПХЁЃ
# ЩшжУ simulate <- function(N, dice.val = 6, jbns, switch.val = 4){ ЃЃФЃФтБфСП ЃЃПЩвджЛЪЙгУвЛИіїЛзгбљБО ЃЃВЛЭЌЕФЛњжЦЃЌР§ШчжЛЖЊ1ИіїЛзгЃЌЛђШЮКЮЦфЫћИХТЪЗжВМ b<- sample(1:dice.val, N, replace = T) + sample(1:dice.val, N, replace = T) a <- sample(1:dice.val, N, replace = T) + sample(1:dice.val, N, replace = T) bob.jbns <- rpois(N, jbns[1]) alice.jbns <- rpois(N, jbns[2]) # зДЬЌ draws <- data.frame(state = rep(NA, N), obs = rep(NA, N), # ЗЕЛиНсЙћ return(cbind(roll = 1:N, draws)) # ФЃФтГЁОА draws <- simulate(N, jbns = c(12, 4), switch.val = 4) # ЙлВьНсЙћ ggplot(draws, aes(x = roll, y = obs)) + geom_line()
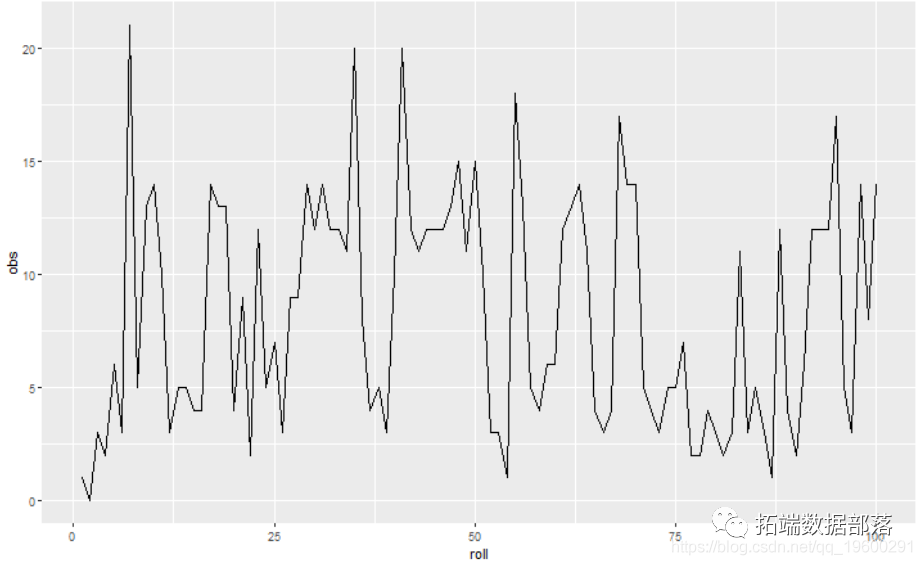 ШчФњЫљМћЃЌНіМьВщвЛЯЕСаМЦЪ§РДШЗЖЈЫжРїЛзгЪЧРЇФбЕФЁЃЮвУЧНЋФтКЯHMMЁЃгЩгкЮвУЧе§дкДІРэМЦЪ§Ъ§ОнЃЌвђДЫЙлВьжЕЪЧДгВДЫЩЗжВМжаЕУГіЕФЁЃ
ШчФњЫљМћЃЌНіМьВщвЛЯЕСаМЦЪ§РДШЗЖЈЫжРїЛзгЪЧРЇФбЕФЁЃЮвУЧНЋФтКЯHMMЁЃгЩгкЮвУЧе§дкДІРэМЦЪ§Ъ§ОнЃЌвђДЫЙлВьжЕЪЧДгВДЫЩЗжВМжаЕУГіЕФЁЃ
fit.hmm <- function(draws){ # HMM mod <- fit(obs ~ 1, data = draws, nstates = 2, family = poisson() # ЭЈЙ§ЙРМЦКѓбщРДдЄВтзДЬЌ est.states <- posterior(fit.mod) head(est.states) # НсЙћ hmm.post.df <- melt(est.states, measure.vars = # ЪфГіБэИё print(table(draws[,c("state", "est.state.labels")])) ## iteration 0 logLik: -346.2084 ## iteration 5 logLik: -274.2033 ## converged at iteration 7 with logLik: -274.2033 ## est.state.labels ## state alice bob ## a 49 2 ## b 3 46
ФЃаЭбИЫйЪеСВЁЃЪЙгУКѓбщИХТЪЃЌЮвУЧЙРМЦЙ§ГЬДІгкФФИізДЬЌЃЌМДЫгЕгаїЛзгЃЌAЛђBЁЃвЊОпЬхЛиД№ИУЮЪЬтЃЌЮвУЧашвЊИќЖрЕиСЫНтИУЙ§ГЬЁЃдкетжжЧщПіЯТЃЌЮвУЧжЊЕРAжЛЯВЛЖКкШэЬЧЁЃЗёдђЃЌЮвУЧжЛФмЫЕИУЙ§ГЬДІгкзДЬЌ1Лђ2ЁЃЯТЭМЯдЪОСЫHMMКмКУЕиФтКЯСЫЪ§ОнВЂЙРМЦСЫвўВизДЬЌЁЃ
# ЛцЭМЪфГі g0 <- (ggplot(model.output$draws, aes(x = roll, y = obs)) + geom_line() + theme(axis.ticks = element_blank(), axis.title.y = element_blank())) %>% ggplotGrob g1 <- (ggplot(model.output$draws, aes(x = roll, y = state, fill = state, col = state)) + g0$widths <- g1$widths return(grid.arrange(g0, g1 plot.hmm.output(hmm1)

СюШЫгЁЯѓЩюПЬЕФЪЧЃЌИУФЃаЭФтКЯЪ§ОнКЭТЫГ§дыЩљвдЙРМЦзДЬЌЕФСМКУГЬЖШЁЃЙЋЦНЕиЫЕЃЌПЩвдЭЈЙ§КіТдЪБМфЗжСПВЂЪЙгУEMЫуЗЈРДЙРМЦзДЬЌЁЃЕЋЪЧЃЌгЩгкЮвУЧжЊЕРЪ§ОнаЮГЩвЛИіађСаЃЌвђЮЊЙлВьЯТвЛДЮЗЂЩњЕФИХТЪШЁОігкЧАвЛИіМД\ЃЈPЃЈX_t | X_ {t-1}ЃЉ\ЃЉЃЌЦфжа\ЃЈX_t \ ЃЉЪЧШэЬЧЕФЪ§СПЁЃ
ПМТЧЕНЮвУЧЙЙдьЕФЮЪЬтЃЌетПЩФмЪЧвЛИіЯрЖдМђЕЅЕФАИР§ЁЃШчЙћзЊвЦИХТЪДѓЕУЖрдѕУДАьЃП
simulate(100, jbns = c(12, 4), switch.val = 7) ## iteration 0 logLik: -354.2707 ## iteration 5 logLik: -282.4679 ## iteration 10 logLik: -282.3879 ## iteration 15 logLik: -282.3764 ## iteration 20 logLik: -282.3748 ## iteration 25 logLik: -282.3745 ## converged at iteration 30 with logLik: -282.3745 ## est.state.labels ## state alice bob ## alice 54 2 ## bob 5 39 plot(hmm2)
 етгаКмЖрдывєЪ§ОнЃЌЕЋЪЧHMMШдШЛзіЕУКмКУЁЃадФмЕФЬсИпВПЗжЙщвђгкЮвУЧЖдДгЙожаШЁГіЕФШэЬЧЪ§СПЕФбЁдёЁЃЗжВМдНУїЯдЃЌФЃаЭОЭдНШнвзЪАШЁзЊвЦЁЃЙЋЦНЕиНВЃЌЮвУЧПЩвдМЦЫужаЮЛЪ§ЃЌВЂНЋЫљгаЕЭгкжаЮЛЪ§ЕФжЕЖМЙщЮЊвЛИізДЬЌЃЌЖјНЋЫљгаИпгкжаЮЛЪ§ЕФжЕЙщЮЊСэвЛзДЬЌЃЌФњПЩвдДгНсЙћжаПДЕНЫќУЧзіЕУКмКУЁЃетЪЧвђЮЊзЊвЦИХТЪЗЧГЃИпЃЌВЂЧвдЄМЦЮвУЧЛсДгУПИізДЬЌЙлВьЕНЯрЫЦЪ§СПЕФЙлВьНсЙћЁЃЕБзЊвЦИХТЪВЛЭЌЪБЃЌЮвУЧЛсПДЕНHMMБэЯжИќКУЁЃ
етгаКмЖрдывєЪ§ОнЃЌЕЋЪЧHMMШдШЛзіЕУКмКУЁЃадФмЕФЬсИпВПЗжЙщвђгкЮвУЧЖдДгЙожаШЁГіЕФШэЬЧЪ§СПЕФбЁдёЁЃЗжВМдНУїЯдЃЌФЃаЭОЭдНШнвзЪАШЁзЊвЦЁЃЙЋЦНЕиНВЃЌЮвУЧПЩвдМЦЫужаЮЛЪ§ЃЌВЂНЋЫљгаЕЭгкжаЮЛЪ§ЕФжЕЖМЙщЮЊвЛИізДЬЌЃЌЖјНЋЫљгаИпгкжаЮЛЪ§ЕФжЕЙщЮЊСэвЛзДЬЌЃЌФњПЩвдДгНсЙћжаПДЕНЫќУЧзіЕУКмКУЁЃетЪЧвђЮЊзЊвЦИХТЪЗЧГЃИпЃЌВЂЧвдЄМЦЮвУЧЛсДгУПИізДЬЌЙлВьЕНЯрЫЦЪ§СПЕФЙлВьНсЙћЁЃЕБзЊвЦИХТЪВЛЭЌЪБЃЌЮвУЧЛсПДЕНHMMБэЯжИќКУЁЃ
ШчЙћЙлВьНсЙћРДздЯрЭЌЕФЗжВМЃЌМДAКЭBГдСЫЯрЭЌЪ§СПЕФШэЬЧдѕУДАьЃП
hmm3 <- fit.hmm(draws) plot(hmm3)
 ВЛЬЋКУЃЌЕЋетЪЧПЩвддЄЦкЕФЁЃШчЙћДгжаЕУГіЙлВьНсЙћЕФЗжВМжЎМфУЛгаВювьЃЌдђПЩФмвВжЛга1ИізДЬЌЁЃ
ВЛЬЋКУЃЌЕЋетЪЧПЩвддЄЦкЕФЁЃШчЙћДгжаЕУГіЙлВьНсЙћЕФЗжВМжЎМфУЛгаВювьЃЌдђПЩФмвВжЛга1ИізДЬЌЁЃ
ЪЕМЪШчКЮЙРЫузДЬЌЃП
ЪзЯШЃЌзДЬЌЪ§СПМАЦфЗжВМЗНЪНБОжЪЩЯЪЧЮДжЊЕФЁЃРћгУЖдЯЕЭГНЈФЃЕФжЊЪЖЃЌгУЛЇПЩвдбЁдёКЯРэЪ§СПЕФзДЬЌЁЃдкЮвУЧЕФЪОР§жаЃЌЮвУЧжЊЕРгаСНжжзДЬЌЪЙЪТЧщБфЕУШнвзЁЃПЩФмжЊЕРШЗЧаЕФзДЬЌЪ§ЃЌЕЋетВЂВЛГЃМћЁЃдйДЮЭЈЙ§ЯЕЭГжЊЪЖРДМйЩшЙлВьНсЙћЭЈГЃЪЧКЯРэЕФЃЌетЭЈГЃЪЧКЯРэЕФЁЃ
ДгетРяПЊЪМЃЌЪЙгУ Baum-WelchЫуЗЈ РДЙРМЦВЮЪ§ЃЌетЪЧEMЫуЗЈЕФвЛжжБфЬхЃЌЫќРћгУСЫЙлВтађСаКЭMarkovЪєадЁЃГ§СЫЙРМЦзДЬЌЕФВЮЪ§ЭтЃЌЛЙашвЊЙРМЦзЊвЦИХТЪЁЃBaum-WelchЫуЗЈЪзЯШЖдЪ§ОнНјаае§ЯђДЋЕнЃЌШЛКѓНјааЗДЯђДЋЕнЁЃШЛКѓИќаТзДЬЌзЊвЦИХТЪЁЃШЛКѓжиИДДЫЙ§ГЬЃЌжБЕНЪеСВЮЊжЙЁЃ
дкЯжЪЕЪРНч
дкЯжЪЕЪРНчжаЃЌHMMЭЈГЃгУгк
- ЙЩЦБЪаГЁдЄВтЃЌЮоТлЪаГЁДІгкХЃЪаЛЙЪЧамЪа
- ЙРМЦNLPжаЕФДЪад
- ЩњЮяВтађ
- ађСаЗжРр
НіОйМИР§ЁЃжЛвЊгаЙлВьађСаЃЌОЭПЩвдЪЙгУHMMЃЌетЖдгкРыЩЂЧщПівВЪЪгУЁЃ