ЩёОЭјТчвЛжБЪЧУдШЫЕФЛњЦїбЇЯАФЃаЭжЎвЛЃЌВЛНівђЮЊЛЈЩкЕФЗДЯђДЋВЅЫуЗЈЃЌЖјЧвЛЙвђЮЊЫќУЧЕФИДдгадЃЈПМТЧЕНаэЖрвўВиВуЕФЩюЖШбЇЯАЃЉКЭЪмДѓФдЦєЗЂЕФНсЙЙЁЃ
ЩёОЭјТчВЂВЛзмЪЧСїааЃЌВПЗждвђЪЧЫќУЧдкФГаЉЧщПіЯТШдШЛДцдкМЦЫуГЩБОИпАКЃЌВПЗждвђЪЧгыжЇГжЯђСПЛњЃЈSVMЃЉЕШМђЕЅЗНЗЈЯрБШЃЌЫќУЧЫЦКѕУЛгаВњЩњИќКУЕФНсЙћЁЃШЛЖјЃЌЩёОЭјТчдйвЛДЮв§Ц№СЫШЫУЧЕФзЂвтВЂБфЕУСїааЦ№РДЁЃ
дкетЦЊЮФеТжаЃЌЮвУЧНЋФтКЯЩёОЭјТчЃЌВЂНЋЯпадФЃаЭзїЮЊБШНЯЁЃ
Ъ§ОнМЏ
ВЈЪПЖйЪ§ОнМЏЪЧВЈЪПЖйНМЧјЗПЮнМлжЕЪ§ОнЕФМЏКЯЁЃЮвУЧЕФФПБъЪЧЪЙгУЫљгаЦфЫћПЩгУЕФСЌајБфСПРДдЄВтздзЁЗПЮнЃЈmedvЃЉЕФжажЕЁЃ
ЪзЯШЃЌЮвУЧашвЊМьВщЪЧЗёШБЩйЪ§ОнЕуЃЌЗёдђЮвУЧашвЊаоИДЪ§ОнМЏЁЃ
applyЃЈdataЃЌ2ЃЌfunctionЃЈxЃЉsumЃЈis.naЃЈxЃЉЃЉЃЉ
ШЛКѓЮвУЧФтКЯЯпадЛиЙщФЃаЭВЂдкВтЪдМЏЩЯНјааВтЪдЁЃ
index < - sampleЃЈ1ЃКnrowЃЈdataЃЉЃЌroundЃЈ0.75 * nrowЃЈdataЃЉЃЉЃЉ MSE.lm < - sumЃЈЃЈpr.lm - test $ medvЃЉ^ 2ЃЉ/ nrowЃЈtestЃЉ
ИУsample(x,size)КЏЪ§МђЕЅЕиДгЯђСПЪфГіжИЖЈДѓаЁЕФЫцЛњбЁдёбљБОЕФЯђСПxЁЃ
зМБИЪЪгІЩёОЭјТч
дкФтКЯЩёОЭјТчжЎЧАЃЌашвЊзівЛаЉзМБИЙЄзїЁЃЩёОЭјТчВЛШнвзбЕСЗКЭЕїећЁЃ
зїЮЊЕквЛВНЃЌЮвУЧНЋНтОіЪ§ОндЄДІРэЮЪЬтЁЃ
вђДЫЃЌЮвУЧдкМЬајжЎЧАЗжИюЪ§ОнЃК
maxs < - applyЃЈdataЃЌ2ЃЌmaxЃЉ scaled < - as.data.frameЃЈscaleЃЈdataЃЌcenter = minsЃЌscale = maxs - minsЃЉЃЉ train_ < - scaled [indexЃЌ] test_ < - scaled [-indexЃЌ]
ЧызЂвтЃЌscaleЗЕЛиашвЊЧПжЦзЊЛЛЮЊdata.frameЕФОиеѓЁЃ
ВЮЪ§
ОнЮвЫљжЊЃЌЫфШЛгаМИИіЛђЖрЛђЩйПЩНгЪмЕФОбщЗЈдђЃЌЕЋУЛгаЙЬЖЈЕФЙцдђПЩвдЪЙгУЖрЩйВуКЭЩёОдЊЁЃЭЈГЃЃЌШчЙћгаБивЊЃЌвЛИівўВиВузувдТњзуДѓСПгІгУГЬађЕФашвЊЁЃОЭЩёОдЊЕФЪ§СПЖјбдЃЌЫќгІИУдкЪфШыВуДѓаЁКЭЪфГіВуДѓаЁжЎМфЃЌЭЈГЃЪЧЪфШыДѓаЁЕФ2/3
- ИУ
hiddenВЮЪ§НгЪмвЛИіАќКЌУПИівўВиВуЕФЩёОдЊЪ§СПЕФЯђСПЃЌЖјИУВЮЪ§linear.outputгУгкжИЖЈЮвУЧЪЧЗёвЊНјааЛиЙщlinear.output=TRUEЛђЗжРрlinear.output=FALSE
NeuralnetАќЬсЙЉСЫЛцжЦФЃаЭЕФКУЙЄОпЃК
plotЃЈnnЃЉ
етЪЧФЃаЭЕФЭМаЮБэЪОЃЌУПИіСЌНгЖМгаШЈжиЃК
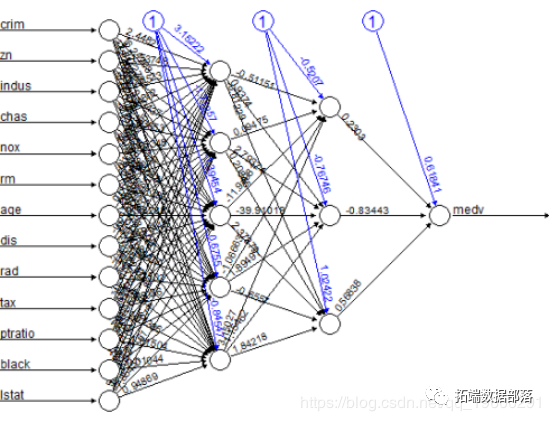
КкЩЋЯпЬѕЯдЪОУПИіВугыУПИіСЌНгЩЯЕФШЈжижЎМфЕФСЌНгЃЌЖјРЖЯпЯдЪОУПИіВНжшжаЬэМгЕФЦЋВюЯюЁЃЦЋВюПЩвдБЛШЯЮЊЪЧЯпадФЃаЭЕФНиОрЁЃ
ЪЙгУЩёОЭјТчдЄВтmedv
ЯждкЮвУЧПЩвдГЂЪддЄВтВтЪдМЏЕФжЕВЂМЦЫуMSEЁЃ
pr.nn < - computeЃЈnnЃЌtest _ [ЃЌ1ЃК13]ЃЉ
ШЛКѓЮвУЧБШНЯСНИіMSE
ЯдШЛЃЌдкдЄВтmedvЪБЃЌЭјТчБШЯпадФЃаЭзіЕУИќКУЁЃдйвЛДЮЃЌвЊаЁаФЃЌвђЮЊетИіНсЙћШЁОігкЩЯУцжДааЕФСаГЕВтЪдЗжИюЁЃЯТУцЃЌдкЪгОѕЭМжЎКѓЃЌЮвУЧНЋНјааПьЫйНЛВцбщжЄЃЌвдБуЖдНсЙћИќгааХаФЁЃ
ЯТУцЛцжЦСЫЭјТчадФмКЭВтЪдМЏЩЯЕФЯпадФЃаЭЕФЕквЛжжПЩЪгЗНЗЈ
ЪфГіЭМ

ЭЈЙ§ФПЪгМьВщЭМЃЌЮвУЧПЩвдПДЕНЩёОЭјТчЕФдЄВтЃЈЭЈГЃЃЉдкЯпжмЮЇИќМгМЏжаЃЈгыЯпЕФЭъУРЖдЦыНЋБэУїMSEЮЊ0ЃЌвђДЫЪЧРэЯыЕФЭъУРдЄВтЃЉЃЌЖјВЛЪЧгЩЯпадФЃаЭЁЃ
ЯТУцЛцжЦСЫвЛИіПЩФмИќгагУЕФЪгОѕБШНЯЃК

НЛВцбщжЄ
НЛВцбщжЄЪЧЙЙНЈдЄВтФЃаЭЕФСэвЛИіЗЧГЃживЊЕФВНжшЁЃЫфШЛгаВЛЭЌРраЭЕФНЛВцбщжЄЗНЗЈ
ШЛКѓЭЈЙ§МЦЫуЦНОљЮѓВюЃЌЮвУЧПЩвдеЦЮеФЃаЭЕФдЫзїЗНЪНЁЃ
ЮвУЧНЋЪЙгУЩёОЭјТчЕФforбЛЗКЭЯпадФЃаЭcv.glm()ЕФbootАќжаЕФКЏЪ§РДЪЕЯжПьЫйНЛВцбщжЄЁЃ
ОнЮвЫљжЊЃЌRжаУЛгаФкжУКЏЪ§дкетжжЩёОЭјТчЩЯНјааНЛВцбщжЄЃЌШчЙћФужЊЕРетбљЕФКЏЪ§ЃЌЧыдкЦРТлжаИцЫпЮвЁЃвдЯТЪЧЯпадФЃаЭЕФ10БЖНЛВцбщжЄMSEЃК
lm.fit < - glmЃЈmedv~ЁЃЃЌdata = dataЃЉ
ЧызЂвтЃЌЮве§дквдетжжЗНЪНЗжИюЪ§ОнЃК90ЃЅЕФбЕСЗМЏКЭ10ЃЅЕФВтЪдМЏвдЫцЛњЗНЪННјаа10ДЮЁЃЮввВе§дкЪЙгУplyrПтГѕЪМЛЏНјЖШЬѕЃЌвђЮЊЮвЯывЊУмЧаЙизЂЙ§ГЬЕФзДЬЌЃЌвђЮЊЩёОЭјТчЕФФтКЯПЩФмашвЊвЛЖЮЪБМфЁЃ
Й§СЫвЛЛсЖљЃЌЙ§ГЬЭъГЩЃЌЮвУЧМЦЫуЦНОљMSEВЂНЋНсЙћЛцжЦГЩЯфЯпЭМ
cv.error 10.3269799517.640652805 6.310575067 15.769518577 5.730130820 10.520947119 6.1211608406.389967211 8.004786424 17.369282494 9.412778105
ЩЯУцЕФДњТыЪфГівдЯТboxplotЃК

ЩёОЭјТчЕФЦНОљMSEЃЈ10.33ЃЉЕЭгкЯпадФЃаЭЕФMSEЃЌОЁЙмНЛВцбщжЄЕФMSEЫЦКѕДцдквЛЖЈГЬЖШЕФБфЛЏЁЃетПЩФмШЁОігкЪ§ОнЕФЗжИюЛђЭјТчжаШЈжиЕФЫцЛњГѕЪМЛЏЁЃ
ЙигкФЃаЭПЩНтЪЭадЕФзюКѓЫЕУї
ЩёОЭјТчКмЯёКкКазгЃКНтЪЭЫќУЧЕФНсЙћвЊБШНтЪЭМђЕЅФЃаЭЃЈШчЯпадФЃаЭЃЉЕФНсЙћвЊРЇФбЕУЖрЁЃвђДЫЃЌИљОнФњашвЊЕФгІгУГЬађРраЭЃЌФњПЩФмвВЯыПМТЧетИівђЫиЁЃДЫЭтЃЌе§ШчФњдкЩЯУцЫљПДЕНЕФЃЌашвЊИёЭтаЁаФвдЪЪгІЩёОЭјТчЃЌаЁЕФБфЛЏПЩФмЕМжТВЛЭЌЕФНсЙћЁЃ
