БОЪОР§ЫЕУїШчКЮЪЙгУГЄЖЬЦкМЧвфЃЈLSTMЃЉЭјТчЖдађСаЪ§ОнНјааЗжРрЁЃ
вЊбЕСЗЩюЖШЩёОЭјТчЖдађСаЪ§ОнНјааЗжРрЃЌПЩвдЪЙгУLSTMЭјТчЁЃLSTMЭјТчЪЙФњПЩвдНЋађСаЪ§ОнЪфШыЭјТчЃЌВЂИљОнађСаЪ§ОнЕФИїИіЪБМфВННјаадЄВтЁЃ
БОЪОР§ЪЙгУШегядЊвєЪ§ОнМЏЁЃДЫЪОР§бЕСЗLSTMЭјТчРДЪЖБ№ИјЖЈЪБМфађСаЪ§ОнЕФЫЕЛАепЃЌИУЪБМфађСаЪ§ОнБэЪОСЌајНВЛАЕФСНИіШегядЊвєЁЃбЕСЗЪ§ОнАќКЌОХЮЛЗЂбдШЫЕФЪБМфађСаЪ§ОнЁЃУПИіађСаОпга12ИіЬиеїЃЌВЂЧвГЄЖШВЛЭЌЁЃЪ§ОнМЏАќКЌ270ИібЕСЗЙлВьКЭ370ИіВтЪдЙлВьЁЃ
МгдиађСаЪ§Он
МгдиШегядЊвєбЕСЗЪ§ОнЁЃ XTrain ЪЧАќКЌГЄЖШПЩБфЕФЮЌЖШ12ЕФ270ИіађСаЕФЕЅдЊеѓСаЁЃ Y ЪЧБъЧЉЁА 1ЁБЃЌЁА 2ЁБЃЌ...ЃЌЁА 9ЁБЕФЗжРрЯђСПЃЌЗжБ№ЖдгІгкОХИібяЩљЦїЁЃжаЕФЬѕФП XTrain ЪЧОпга12ааЃЈУПИівЊЫивЛааЃЉКЭВЛЭЌСаЪ§ЃЈУПИіЪБМфВНГЄвЛСаЃЉЕФОиеѓЁЃ
XTrain(1:5) ans=5ЁС1 cell array {12x20 double} {12x26 double} {12x22 double} {12x20 double} {12x21 double}
ПЩЪгЛЏЭМжаЕФЕквЛИіЪБМфађСаЁЃУПааЖдгІвЛИіЬиеїЁЃ
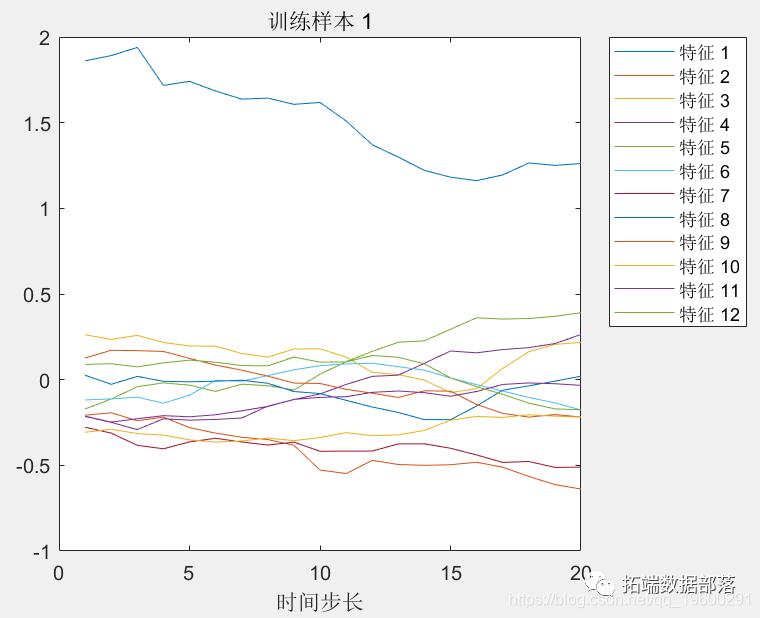
figure plot(Train') xlabel("ЪБМфВНГЄ") title("бЕСЗбљБО 1") numFeatures = size(XTrain{1},1); legend("Ьиеї "
зМБИЬюГфЪ§Он
дкбЕСЗЙ§ГЬжаЃЌФЌШЯЧщПіЯТЃЌИУШэМўФЌШЯНЋбЕСЗЪ§ОнЗжГЩаЁХњВЂЬюГфађСаЃЌвдЪЙЫќУЧОпгаЯрЭЌЕФГЄЖШЁЃЬЋЖрЕФЬюГфПЩФмЛсЖдЭјТчадФмВњЩњИКУцгАЯьЁЃ
ЮЊЗРжЙбЕСЗЙ§ГЬдіМгЬЋЖрЬюГфЃЌФњПЩвдАДађСаГЄЖШЖдбЕСЗЪ§ОнНјааХХађЃЌВЂбЁдёаЁХњСПЕФДѓаЁЃЌвдЪЙаЁХњСПжаЕФађСаОпгаЯрЫЦЕФГЄЖШЁЃЯТЭМЯдЪОСЫЖдЪ§ОнНјааХХађжЎЧАКЭжЎКѓЕФЬюГфађСаЕФаЇЙћЁЃ

ЛёШЁУПИіЙлВьЕФађСаГЄЖШЁЃ
АДађСаГЄЖШЖдЪ§ОнНјааХХађЁЃ
дкЬѕаЮЭМжаВщПДХХађЕФађСаГЄЖШЁЃ
figure bar(sequenceLengths) ylim([0 30]) xlabel("ађСа") ylabel("ГЄЖШ") title("ХХађКѓЪ§Он")

бЁдёДѓаЁЮЊ27ЕФаЁХњСППЩОљдШЛЎЗжбЕСЗЪ§ОнВЂМѕЩйаЁХњСПжаЕФЪ§СПЁЃЯТЭМЫЕУїСЫЬэМгЕНађСажаЕФЬюГфСПЁЃ

ЖЈвхLSTMЭјТчМмЙЙ
ЖЈвхLSTMЭјТчЬхЯЕНсЙЙЁЃНЋЪфШыДѓаЁжИЖЈЮЊДѓаЁЮЊ12ЕФађСаЃЈЪфШыЪ§ОнЕФДѓаЁЃЉЁЃжИЖЈОпга100ИівўВиЕЅдЊЕФЫЋЯђLSTMВуЃЌВЂЪфГіађСаЕФзюКѓвЛИідЊЫиЁЃзюКѓЃЌЭЈЙ§АќРЈДѓаЁЮЊ9ЕФЭъШЋСЌНгВуЃЌЦфКѓЪЧsoftmaxВуКЭЗжРрВуЃЌРДжИЖЈОХИіРрЁЃ
ШчЙћПЩвддкдЄВтЪБЪЙгУЭъећађСаЃЌдђПЩвддкЭјТчжаЪЙгУЫЋЯђLSTMВуЁЃЫЋЯђLSTMВудкУПИіЪБМфВНЖМДгЭъећађСажабЇЯАЁЃР§ШчЃЌШчЙћФњЮоЗЈдкдЄВтЪБЪЙгУећИіађСаЃЌБШШчвЛДЮдЄВтвЛИіЪБМфВНГЄЪБЃЌЧыИФгУLSTMВуЁЃ
layers = 5x1 Layer array with layers: 1 '' Sequence Input Sequence input with 12 dimensions 2 '' BiLSTM BiLSTM with 100 hidden units 3 '' Fully Connected 9 fully connected layer 4 '' Softmax softmax 5 '' Classification Output crossentropyex
ЯждкЃЌжИЖЈбЕСЗбЁЯюЁЃНЋгХЛЏЦїжИЖЈЮЊ 'adam'ЃЌНЋЬнЖШуажЕжИЖЈЮЊ1ЃЌНЋзюДѓРњдЊЪ§жИЖЈЮЊ100ЁЃвЊМѕЩйаЁХњСПжаЕФЬюГфСПЃЌЧыбЁдё27ЕФаЁХњСПДѓаЁЁЃгызюГЄађСаЕФГЄЖШЯрЭЌЃЌЧыНЋађСаГЄЖШжИЖЈЮЊ 'longest'ЁЃЮЊШЗБЃЪ§ОнШдАДађСаГЄЖШХХађЃЌЧыжИЖЈДгВЛЖдЪ§ОнНјааЫцЛњХХађЁЃ
гЩгкХњДІРэЕФађСаЖЬЃЌвђДЫбЕСЗИќЪЪКЯгкCPUЁЃжИЖЈ 'ExecutionEnvironment' ЮЊ 'cpu'ЁЃвЊдкGPUЩЯНјаабЕСЗЃЈШчЙћгаЃЉЃЌЧыНЋЩшжУ 'ExecutionEnvironment' ЮЊ 'auto' ЃЈетЪЧФЌШЯжЕЃЉЁЃ
бЕСЗLSTMЭјТч
ЪЙгУжИЖЈЕФбЕСЗбЁЯюРДбЕСЗLSTMЭјТч trainNetworkЁЃ

ВтЪдLSTMЭјТч
МгдиВтЪдМЏВЂНЋађСаЗжРрЮЊбяЩљЦїЁЃ
МгдиШегядЊвєВтЪдЪ§ОнЁЃ XTest ЪЧАќКЌ370ИіГЄЖШПЩБфЕФЮЌЖШ12ЕФађСаЕФЕЅдЊеѓСаЁЃ YTest ЪЧБъЧЉЁА 1ЁБЃЌЁА 2ЁБЃЌ...ЁА 9ЁБЕФЗжРрЯђСПЃЌЗжБ№ЖдгІгкОХИібяЩљЦїЁЃ
XTest(1:3) ans=3ЁС1 cell array {12x19 double} {12x17 double} {12x19 double}
LSTMЭјТч net ЪЧЪЙгУЯрЫЦГЄЖШЕФађСаНјаабЕСЗЕФЁЃШЗБЃВтЪдЪ§ОнЕФзщжЏЗНЪНЯрЭЌЁЃАДађСаГЄЖШЖдВтЪдЪ§ОнНјааХХађЁЃ
ЗжРрВтЪдЪ§ОнЁЃвЊМѕЩйЗжРрЙ§ГЬв§ШыЕФЪ§ОнСПЃЌЧыНЋХњСПДѓаЁЩшжУЮЊ27ЁЃвЊгІгУгыбЕСЗЪ§ОнЯрЭЌЕФЬюГфЃЌЧыНЋађСаГЄЖШжИЖЈЮЊ 'longest'ЁЃ
МЦЫудЄВтЕФЗжРрзМШЗадЁЃ
acc = sum(YPred == YTest)./numel(YTest) acc = 0.9730

