本文整理自曹操出行基础研发部负责人史何富,在 Flink Forward Asia 2023 主会场的分享。本次分享将为大家介绍实时数仓在曹操出行(互联网网约车出行企业)的实时数仓应用场景,以及通过离线场景向实时场景下加速升级而获得的业务价值。内容主要分为以下六部分:
- 业务简介
- 实时数仓解决业务痛点
- 曹操出行实时数仓
- 运营落地及收益
- 未来规划
- 用户对话环节
一、业务简介

曹操出行创立于 2015 年 5 月 21 日,是吉利控股集团布局「新能源汽车共享生态」的战略性投资业务,以「科技重塑绿色共享出行」为使命,将全球领先的互联网、车联网、自动驾驶技术以及新能源科技创新应用于共享出行领域,以「用心服务国民出行」为品牌主张,致力于打造服务口碑最好的出行品牌。
曹操出行目前为止已经在全国 62 个城市落地运营,投放了超过 10 万辆新能源纯电车,累计注册司机超过 350 万,服务乘客超过 1.5 亿。另外一块非常重要的业务是企业用户,目前为止服务企业用户超过 1500 万家。
二、实时数仓解决业务痛点

介绍三类主要的实时数据相关需求。
- 首先是管理层, 管理者需要随时随地看到公司运营状况,从概念性数据到每个城市不同维度的实时数据,需要一个方便使用的掌上工具随时发现运营中的问题,能够快速定位到什么环节出现了问题,同时也可以发现一些潜在的业务机会。
- 第二是一线运营,团队在每个城市或者总部的运营官需要一个能够聚焦自己负责范围的工具。
- 第三是算法团队,互联网的出行业务与过去不同,它不是一个放养的简单模式,把车放在路上去跑,乘客打车,就实时把乘客和司机按照最短距离进行匹配。现在团队有自己的交易引擎和调度引擎,这些都是依赖于实时数据的,数据越新鲜算法效果越好。
三、曹操出行实时数仓

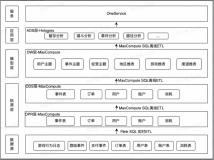
团队设计的实时数仓层次主要讲三点,对应三类需求。通过 Flink 一整套实时计算引擎产生团队指标体系,OLAP 引擎将数据做实时分析给运营人员,把实时数据反馈给算法模型从而更好地进行决策。数据来自不同数据源,手机端 APP 包括乘客端和车机端,车机的数据会实时流到团队后台 Flink,业务日志通过消息队列到 Flink 的集群,最后生成数据到 OLAP 引擎、数据库等。
四、运营落地及收益

介绍一些基于实时数据开发的数据产品。
观星台:
团队开发了一个叫做观星台的掌上工具,基本上包含了全公司实时和历史的各维度运营数据,包括目前乘客的需求、毛利达成情况、补贴发放、甚至哪个区域的需求比较多等。
天机镜:
针对运营类团队做的一个基于时空可视化的运营工具。团队人员及城市负责人可以随时随地查看当前负责城市任何区域的运营状况。把一个城市在 H3 网格分割成很多角度,每个 H3 网格都有自己的运营状态,包括目前里面有多少车或是未来 10 分钟、20 分钟后会有多少车。甚至也做了一些预测的功能衡量需求是否溢出,可以回放整个需求和运力供需关系的变化。因为有时候不可能一天 24 小时每时每刻都盯着盘,工具可以设定一些告警的策略以便团队的使用。这些策略都可以主动感知异常,然后通过各种方式,比如钉钉短信甚至电话通知到用户,目前他所负责的区域或城市有哪些需要关注的变化。
实时看板:
CBD看板, C 指的是团队的乘客,B 指的是司机,D 指的是城市区域。包括给到团队一线运营人员的数据产品和工具,以便更好地做出人工决策,采取干预措施。
- 算法:
实时数据很好地反哺了团队的算法模块,因为目前整个交易引擎和调度引擎不再像以前那么简单直接,已经全部算法化。比如从一个学校出发,可能分配直线距离最近的一辆空闲车辆。这种派单模式效率非常低,已经不能适应现在网约车的业务状态。当前,团队需要用算法的角色,比如需要根据乘客的对车型的需求和目的地;以及司机的荣耀分,是否疲劳,是否开启回家模式;出发地和目的地的供需状况等多重特征,纳入算法决策的考量。团队需要非常新鲜的数据给到算法团队,才能使整个交易的收益,包括平台和司机,达到最优。通过实时的基于 Flink 一整套流计算,再产生各类指标、实时特征给到团队算法引擎。网约车行业不可能再像过去一样不考虑运营成本给乘客、司机大量发补贴。团队需要想尽办法提升运营的效率,做到不伤害任何一方,当然也能够保证平台健康运营。
五、未来规划

未来规划在云原生云 Flink 上做一些尝试。目前自建的 Flink 集群大概有 2000 核,每天有 500 多亿消息。团队期待上云之后可以降低应用成本,各方面的弹性会更好。因为网约车有非常强的潮汐效应,一天 24 小时需求的波动都会非常大。团队如果还采用传统的专属 Flink 集群成本会比较高,所以要充分利用云的弹性来进一步降低成本。
在算法实时指标方面,团队正在探索更多场景,将生产更多的实时特征给到算法引擎。举个例子,比如说目前算法决策是目标最优,未来肯定要做到多目标的动态最优。目标的最优是团队选择一个城市,比如杭州,设定 xx 业务目标,我们的交易撮合和补贴都能够通过算法来进行,不需要人工干预;达成设定目标的同时,追求全天实付 GTV 的最大化。
六、用户对话环节
■ 对话嘉宾
王 峰|阿里云智能开源大数据平台负责人
史何富|曹操出行基础研发部负责人
双方基于曹操出行如何利用开源 Flink 的技术赋能业务、实时化升级大数据等问题进行了探讨。
史何富老师表示团队只有实时才能提升效率,如果团队在实时方面投入带来的价值增量超过团队在基础设施方面的增量,实时就是值得做的,而且曹操在过去两年也确实证明实时是有价值与效果的,让团队看到了如何通过实时化的数据分析对业务产生更大的收益等。此外,曹操出行的数据分析架构也在做 lakehouse 选型,数据湖是一个比较明确的趋势,团队也会继续探索。
【用户对话环节 - 视频回放】
https://cloud.video.taobao.com/play/u/null/p/1/e/6/t/1/443159041360.mp4
Flink Forward Asia 2023
本届 Flink Forward Asia 更多精彩内容,可微信扫描图片二维码观看全部议题的视频回放及 FFA 2023 峰会资料!

更多内容

活动推荐
阿里云基于 Apache Flink 构建的企业级产品-实时计算 Flink 版现开启活动:
0 元试用 实时计算 Flink 版(5000CU*小时,3 个月内)
了解活动详情:https://free.aliyun.com/?pipCode=sc