3.17.1 Зжзщ
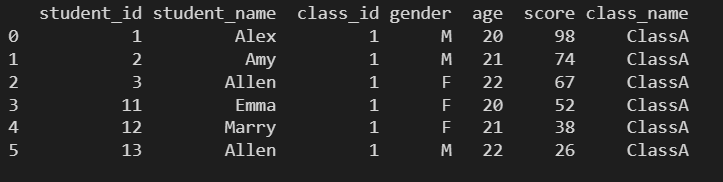
# ИљОн class_id НјааЗжзщ grouped = data.groupby(by='class_id') # ЛёШЁ class_id ЮЊ1ЕФзщ print(grouped.get_group(1))
# ИљОн class_id гы gender НјааЗжзщ grouped = data.groupby(by=['class_id', 'gender']) # # ЛёШЁ class_id gender ЮЊ(1, 'M')ЕФзщ print(grouped.get_group((1, 'M')))

print(grouped.size())

3.17.1 ОлКЯ

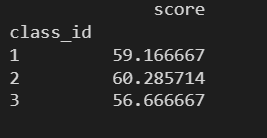
# ИљОн class_id НјааЗжзщ grouped = data.groupby(by='class_id') # ЭГМЦУПИіАрМЖЕФЦНОљЗж # ДЋШыЕФзжЕфЖдгІЕФжЕЮЊДІРэЕФЗНЪН print(grouped.agg({'score': np.mean}))
# ЭГМЦУПИіАрМЖЕФЦНОљЗж, вдМАУДУПИіАрМЖЕФФъСфзюДѓжЕ print(grouped.agg({'score':np.mean, 'age':np.max}))

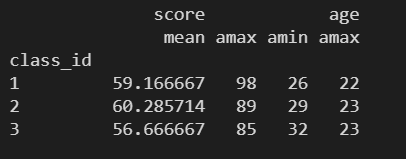
print(grouped.agg({'score':[np.mean, np.max, np.min], 'age':np.max}))
3.18 pivot_table() ---- ЩњГЩDataFrameЖдЯѓЕФЭИЪгБэ
ВЮЪ§ЃК
- indexЃКЗжзщЫљвРОнЕФСа
- valuesЃКжИЖЈашвЊОлКЯЭГМЦЕФСа
- columnsЃКжИЖЈСаЃЌвРОнИУСаЕФУПИіжЕНјааЗжСаЭГМЦ
- marginsЃКЪЧЗёЖдЭИЪгБэЕФУПааУПСаНјааЛузмЭГМЦ
- aggfuncЃКОлКЯвЊжДааЕФВйзї
# ИљОн class_id НјааЗжзщ # ФЌШЯЧѓЗжзщКѓФмНјааОљжЕМЦЫуЕФСаЕФОљжЕ print(data.pivot_table(index='class_id') )

# ИљОн class_id НјааЗжзщ # ЖдЗжзщКѓЕФЪ§Он score ЕФОлКЯВйзїЃЌФЌШЯЧѓОљжЕ print(data.pivot_table(index='class_id', values='score') )
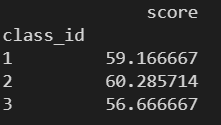
# ИљОн class_id gender НјааЗжзщ # ЖдЗжзщКѓЕФЪ§Он score ЕФОлКЯВйзїЃЌФЌШЯЧѓОљжЕ # вРОн age СаЕФУПИіжЕНјааЗжСаЭГМЦ print( data.pivot_table( index=['class_id', 'gender'], values='score', columns=['age'] ) )

# ИљОн class_id gender НјааЗжзщ # ЖдЗжзщКѓЕФЪ§Он score ЕФОлКЯВйзїЃЌФЌШЯЧѓОљжЕ # вРОн age СаЕФУПИіжЕНјааЗжСаЭГМЦ # ЖдЭИЪгБэЕФУПааУПСаНјааЛузмЭГ print( data.pivot_table( index=['class_id', 'gender'], values='score', columns=['age'], margins=True ) )
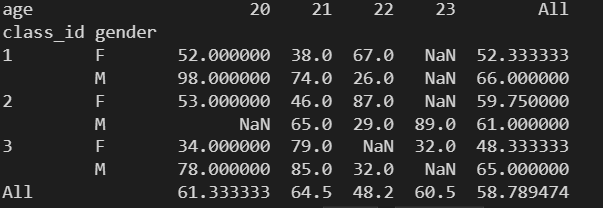
print( data.pivot_table( index=['class_id', 'gender'], values='score', columns=['age'], margins=True, aggfunc='max' ) )

3.19 drop_duplicates ---- ДІРэжиИДжЕ
ЪєадЃК
- subsetЃКНгЪе string Лђ ађСа ЮЊВЮЪ§ЃЌБэЪОвЊНјааШЅжиЕФСаЃЌФЌШЯЮЊNoneЃЌБэЪОШЋВПЕФСа(жЛгаЕБвЛаажаЫљгаЕФСавЛбљЃЌВХЛсЖдИУааНјааШЅжи)
- keepЃКНгЪе string ЮЊВЮЪ§ЃЌБэЪОжиИДЪББЃСєЕкМИИіЪ§ОнЁЃfirstЃКБЃСєЕквЛИіЁЃlastЃКБЃСєзюКѓвЛИіЁЃfalseЃКжЛвЊгажиИДЖМВЛБЃСєЁЃФЌШЯЮЊfirstЁЃ
- inplaceЃКБэЪОЪЧЗёдкдБэЩЯНјаааоИФЁЃФЌШЯЮЊFalseЁЃ
ФЌШЯЧщПіЯТЃЌЖдЫљгаЕФСаНјааШЅжиЃЌВЛдкдБэЩЯНјаааоИФЃЌгажиИДжЕЪБФЌШЯБЃСєжиИДжЕЕФЕквЛИіЁЃ
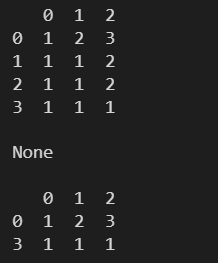
l = [ np.array([1,2,3]), np.array([1,1,2]), np.array([1,1,2]), np.array([1,1,1]) ] df = pd.DataFrame(l) print(df) print() print(df.drop_duplicates()) print() print(df)

l = [ np.array([1,2,3]), np.array([1,1,2]), np.array([1,1,2]), np.array([1,1,1]) ] df = pd.DataFrame(l) print(df) print() # дкдБэЩЯНјаааоИФЃЌЮоЗЕЛижЕ # ВЛдкдБэЩЯНјаааоИФЃЌЛсЗЕЛиаоИФКѓЕФаТБэ print(df.drop_duplicates(subset=[0,1], inplace=True, keep='last')) print() print(df)
3.20 isnull() ---- ХаЖЯЪЧЗёЮЊШБЪЇжЕ
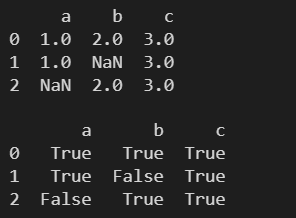
l = [ pd.Series([1,2,3], index=['a', 'b', 'c']), pd.Series([1,3], index=['a', 'c']), pd.Series([2,3], index=['b', 'c']) ] df = pd.DataFrame(l) print(df) print() print(df.isnull())

3.21 notnull() ---- ХаЖЯЪЧЗёВЛЮЊШБЪЇжЕ
l = [ pd.Series([1,2,3], index=['a', 'b', 'c']), pd.Series([1,3], index=['a', 'c']), pd.Series([2,3], index=['b', 'c']) ] df = pd.DataFrame(l) print(df) print() print(df.notnull())