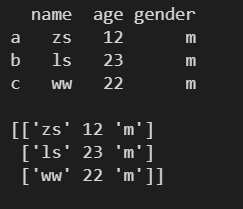
1.8 ДДНЈ DataFrame ЖдЯѓЪБжИЖЈааЫїв§
- indexЃКжИЖЈааЫїв§
l = [ ['zs', 12, 'm'], ['ls', 23, 'm'], ['ww', 22, 'm'] ] df1 = pd.DataFrame( l, columns=['name', 'age', 'gender'], index=['a', 'b', 'c'] ) print(df1) print() print(type(df1)) print()
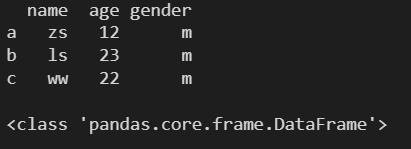
1.9 ДДНЈ DataFrame ЖдЯѓЪБжИЖЈдЊЫиЕФЪ§ОнРраЭ
- dtypeЃКжИЖЈдЊЫиЕФЪ§ОнРраЭ
зжЗћДЎЪ§ОнРраЭЕФЪ§ОндЊЫиЛсБЛКіТд
l = [ ['zs', 12, 'm'], ['ls', 23, 'm'], ['ww', 22, 'm'] ] df1 = pd.DataFrame( l, columns=['name', 'age', 'gender'], index=['a', 'b', 'c'], dtype='float64' ) print(df1) print() print(type(df1)) print()
1.10 ДДНЈ DataFrame ЖдЯѓЕФзЂвтЕу
ЪЙгУСаБэДДНЈ DataFrame ЖдЯѓЪБЃЌВЛЭЌСаБэЕФГЄЖШВЛЭЌЛсБЈДэЁЃ
data = { 'one': [1,2,3], 'two': [1,2,3,4], } df = pd.DataFrame(data)
ValueError: All arrays must be of the same length
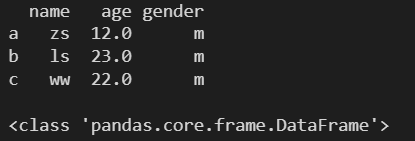
ЪЙгУ Series ЖдЯѓДДНЈ DataFrame ЖдЯѓЃЌВЛЭЌГЄЖШВЛЭЌЛсБЈДэЁЃ
data = { 'one': pd.Series([1,2,3]), 'two': pd.Series([1,2,3,4]), } df = pd.DataFrame(data) print(df)
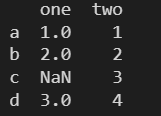
Series ПЩвдБЃжЄСаЪ§ОнИіЪ§ВЛвЛбљЕФВЛЭЌСаЕФИїааЪ§ОндЊЫиЮЛжУЯрЖдгІ
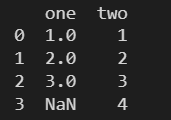
data = { 'one': pd.Series([1, 2, 3], index=['a', 'b', 'd']), 'two': pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd']), } df = pd.DataFrame(data) print(df)
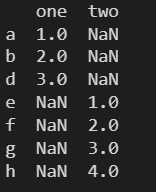
data = { 'one': pd.Series([1, 2, 3], index=['a', 'b', 'd']), 'two': pd.Series([1, 2, 3, 4], index=['e', 'f', 'g', 'h']), } df = pd.DataFrame(data) print(df)
2. DataFrame ЕФЪєад
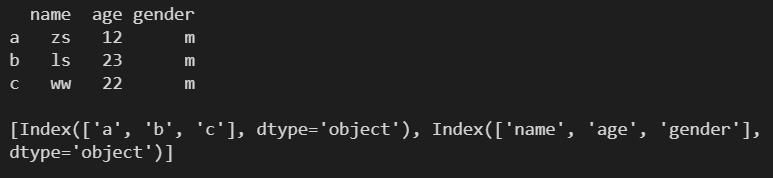
2.1 axes ---- ЗЕЛиаа/СаБъЧЉСаБэ
l = [ ['zs', 12, 'm'], ['ls', 23, 'm'], ['ww', 22, 'm'] ] df1 = pd.DataFrame( l, columns=['name', 'age', 'gender'], index=['a', 'b', 'c'] ) print(df1) print() print(df1.axes)
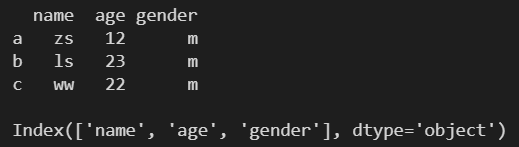
2.2 columns ---- ЗЕЛиСаБъЧЉСаБэ
l = [ ['zs', 12, 'm'], ['ls', 23, 'm'], ['ww', 22, 'm'] ] df1 = pd.DataFrame( l, columns=['name', 'age', 'gender'], index=['a', 'b', 'c'] ) print(df1) print() print(df1.columns)
2.3 index ---- ЗЕЛиааБъЧЉСаБэ
l = [ ['zs', 12, 'm'], ['ls', 23, 'm'], ['ww', 22, 'm'] ] df1 = pd.DataFrame( l, columns=['name', 'age', 'gender'], index=['a', 'b', 'c'] ) print(df1) print() print(df1.index)

2.4 dtypes ---- ЗЕЛиЪ§ОнРраЭ
l = [ ['zs', 12, 'm'], ['ls', 23, 'm'], ['ww', 22, 'm'] ] df1 = pd.DataFrame( l, columns=['name', 'age', 'gender'], index=['a', 'b', 'c'] ) print(df1) print() print(df1.dtypes)
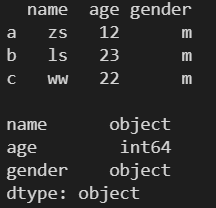
2.5 empty ---- ЗЕЛи DataFrame ЖдЯѓЪЧЗёЮЊПе
l = [ ['zs', 12, 'm'], ['ls', 23, 'm'], ['ww', 22, 'm'] ] df1 = pd.DataFrame( l, columns=['name', 'age', 'gender'], index=['a', 'b', 'c'] ) print(df1) print() print(df1.empty) print() df2 = pd.DataFrame() print(df2) print() print(df2.empty)
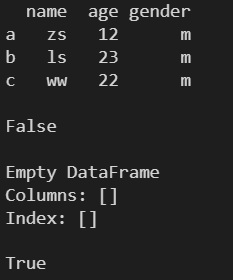
2.6 ndim ---- ЗЕЛи DateFrame ЖдЯѓЕФЮЌЪ§
l = [ ['zs', 12, 'm'], ['ls', 23, 'm'], ['ww', 22, 'm'] ] df1 = pd.DataFrame( l, columns=['name', 'age', 'gender'], index=['a', 'b', 'c'] ) print(df1) print() print(df1.ndim)
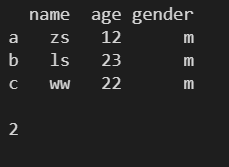
2.7 size ---- ЗЕЛиDateFrame ЖдЯѓжаЕФЪ§ОндЊЫиИіЪ§
l = [ ['zs', 12, 'm'], ['ls', 23, 'm'], ['ww', 22, 'm'] ] df1 = pd.DataFrame( l, columns=['name', 'age', 'gender'], index=['a', 'b', 'c'] ) print(df1) print() print(df1.size)
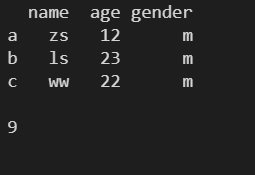
2.8 values ---- ЗЕЛиЪ§ОндЊЫизщГЩЕФ ndarray Ъ§зщ
l = [ ['zs', 12, 'm'], ['ls', 23, 'm'], ['ww', 22, 'm'] ] df1 = pd.DataFrame( l, columns=['name', 'age', 'gender'], index=['a', 'b', 'c'] ) print(df1) print() print(df1.values)