гХЛЏдРэ
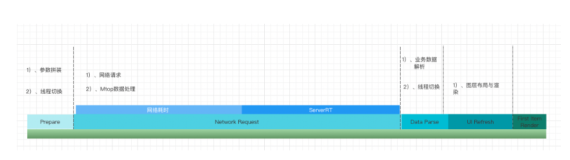
LTOЃЌЙЫУћЫМвхЃЌОЭЪЧдкСДНгЕФЪБКђЃЌМЬајзівЛЯЕСаЕФгХЛЏЁЃгжгЩгкБрвыЦїЕФгХЛЏЦїЪЧвдIRЮЊЪфШыЃЌвђДЫБрвыЦїдкСДНгЪБгХЛЏЕФБрвыЙ§ГЬжаНЋУПИідДЮФМўЩњГЩЕФВЛдйЪЧеце§ЕФЖўНјжЦЮФМўЃЌЖјЪЧ"LTOЖдЯѓЮФМў"ЁЃетаЉЮФМўжаДцДЂЕФВЛЪЧЖўНјжЦДњТыЃЌЖјЪЧБрвыЦїЩњГЩЕФIRЁЃ СДНгЪБЃЌБрвыЦїЛсНЋЫљга"LTOЖдЯѓЮФМў"КЯВЂЕНвЛЦ№ЃЌКЯВЂКѓЩњГЩЕФОоДѓIRЮФМўАќКЌСЫЫљгадДДњТыаХЯЂЃЌетбљОЭФмПчЮФМўЖдЫљгадДДњТыЃЈКЯВЂКѓЕФIRЮФМўЃЉНјааМЏжаЕФЗжЮіКЭгХЛЏЃЌВЂЩњГЩвЛИіеце§ЕФЖўНјжЦЮФМўЃЌСДНгВЂЕУЕНПЩжДааЮФМўЁЃвђЮЊБрвыЦїФмЙЛвЛДЮадПДЕНЫљгадДДњТыЕФаХЯЂЃЌЫљвдЫќзіЕФЗжЮіОпгаИќИпЕФШЗЖЈадКЭзМШЗадЃЌФмЙЛЪЕЪЉЕФгХЛЏвВвЊЖрЕУЖрЁЃ ЕЋдкЪЙгУLTOгХЛЏДѓаЭЕФгІгУГЬађЕФЪБКђЃЌЁАСДНгЁБНзЖЮНЋЫљга"LTOЖдЯѓЮФМў"КЯВЂГЩвЛИіIRЮФМўВЂЩњГЩЕФЕЅИіЖўНјжЦЮФМўПЩФмЗЧГЃХгДѓЃЌетИјЯЕЭГащФтФкДцдьГЩКмДѓбЙСІЃЌЕМжТЦЕЗБФкДцЛЛвГЃЌзюжегАЯьБрвыЁЂСДНгЕФаЇТЪЃЌЩѕжСГіЯжout of memoryДэЮѓЁЃ ЪЕМЪЩЯЃЌGCCБрвыЦїдкLTOНзЖЮЪзЯШЛсНЋЫљгаЮФМўжаЕФЗћКХБэЃЈsymbol tableЃЉаХЯЂКЭЕїгУЭМЃЈcall graphЃЉаХЯЂКЯВЂЕНвЛЦ№ЃЌетбљВЛНіФмПчЮФМўЖдЫљгаЕФКЏЪ§НјааШЋОжЕФЗжЮіЃЌЖјЧвФкДцбЙСІвВНЯаЁЁЃWPAЃЈwhole program analysis, ШЋОжЗжЮіЃЉНзЖЮЛсШЗЖЈОпЬхЕФгХЛЏВпТдЃЌВЂвРОнгХЛЏВпТдНЋЫљгаЕФ"LTOЖдЯѓЮФМў"КЯВЂГЩвЛЛђЖрИіIRЮФМўЁЃ  етаЉIRЮФМўдйДЮВЂЗЂОЙ§гХЛЏЦїгХЛЏКѓЃЌЩњГЩеце§ЕФЖўНјжЦЖдЯѓЮФМўВЂДЋЕнИјеце§ЕФСДНгЦїНјааСДНгЃЌзюКѓЕУЕНПЩжДааЮФМўЁЃ
етаЉIRЮФМўдйДЮВЂЗЂОЙ§гХЛЏЦїгХЛЏКѓЃЌЩњГЩеце§ЕФЖўНјжЦЖдЯѓЮФМўВЂДЋЕнИјеце§ЕФСДНгЦїНјааСДНгЃЌзюКѓЕУЕНПЩжДааЮФМўЁЃ 
ЪЙгУЗНЗЈ
ОйР§ЫЕУїШчКЮЪЙгУLTOРДНјааБрвыгХЛЏЃК
- БраДСЫвЛИіАќКЌСНИідДЮФМўЃЈsource1.c КЭ source2.cЃЉКЭвЛИіЭЗЮФМўЃЈsource2.hЃЉЕФГЬађЁЃгЩгкЭЗЮФМўжаЗЧГЃМђЕЅЕиАќКЌСЫsource2.cжаЕФКЏЪ§даЭЃЌ ЫљвдВЂУЛгаСаГіЁЃ
/* source1.c */ #include <stdio.h> // scanf_s and printf. #include "source2.h" int square(int x) { return x*x; } int main() { int n = 5, m; scanf("%d", &m); printf("The square of %d is %d.\n", n, square(n)); printf("The square of %d is %d.\n", m, square(m)); printf("The cube of %d is %d.\n", n, cube(n)); printf("The sum of %d is %d.\n", n, sum(n)); printf("The sum of cubes of %d is %d.\n", n, sumOfCubes(n)); printf("The %dth prime number is %d.\n", n, getPrime(n)); }
/* source2.c */ #include <math.h> // sqrt. #include <stdbool.h> // bool, true and false. #include "source2.h" int cube(int x) { return x*x*x; } int sum(int x) { int result = 0; for (int i = 1; i <= x; ++i) result += i; return result; } int sumOfCubes(int x) { int result = 0; for (int i = 1; i <= x; ++i) result += cube(i); return result; } static bool isPrime(int x) { for (int i = 2; i <= (int)sqrt(x); ++i) { if (x % i == 0) return false; } return true; } int getPrime(int x) { int count = 0; int candidate = 2; while (count != x) { if (isPrime(candidate)) ++count; } return candidate; }
source1.cЮФМўАќКЌСНИіКЏЪ§ЃЌгавЛИіВЮЪ§ВЂЗЕЛиетИіВЮЪ§ЕФЦНЗНЕФsquareКЏЪ§ЃЌвдМАГЬађЕФmainКЏЪ§ЁЃmainКЏЪ§ЕїгУsource2.cжаГ§СЫisPrimeжЎЭтЕФЫљгаКЏЪ§ЁЃsource2.cга5ИіКЏЪ§ЁЃcubeЗЕЛивЛИіЪ§ЕФШ§ДЮЗНЃЛsumКЏЪ§ЗЕЛиДг1ЕНИјЖЈЪ§ЕФКЭЃЛsumOfCubesЗЕЛи1ЕНИјЖЈЪ§ЕФШ§ДЮЗНЕФКЭЃЛisPrimeгУгкХаЖЯвЛИіЪ§ЪЧЗёЪЧжЪЪ§ЃЛgetPrimeКЏЪ§ЗЕЛиЕкxИіжЪЪ§ЁЃБЪепЪЁТдЕєСЫШнДэДІРэвђЮЊФЧВЂЗЧБОЮФЕФжиЕуЁЃ етаЉДњТыМђЕЅЕЋЪЧКмгагУЁЃЦфжавЛаЉКЏЪ§жЛНјааМђЕЅЕФдЫЫуЃЌвЛаЉашвЊМђЕЅЕФбЛЗЁЃgetPrimeЪЧЕБжазюИДдгЕФКЏЪ§ЃЌАќКЌвЛИіwhileбЛЗЧвдкбЛЗФкВПЕїгУСЫвВАќКЌвЛИібЛЗЕФisPrimeКЏЪ§ЁЃЭЈЙ§етаЉКЏЪ§ЃЌЮвУЧНЋдкLTOЯТПДЕНКЏЪ§ФкСЊЃЌГЃСПелЕўЕШБрвыЦїзюживЊЃЌзюГЃМћЕФгХЛЏЁЃ
- БрвыУќСюЃЈgccАцБОЪЧ9.0.1ЃЉ
# Non-LTO: gcc source1.c source2.c -O2 -o source-nolto # LTO: gcc source1.c source2.c -flto -O2 -o source-lto
- МьВщsource-noltoЕФЛуБр
1. ПЩвдЗЂЯжsquareБЛmainКЏЪ§inlineСЫЃЌЖдгкЕквЛДЮsquare(n)ЕФЕїгУЃЌгЩгкnдкБрвыЪБПЬПЩжЊЃЌЫљвдДњТы БЛГЃЪ§25ЬцДњЃЌЖдгкsquareЕФЕкЖўДЮЕїгУsquareЃЈmЃЉЃЌгЩгкmЕФжЕдкБрвыЪБЪЧЮДжЊЕФЃЌЫљвдБрвыЦїВЛФмЖд МЦЫуЙРжЕЁЃ 2. ПЩвдЗЂЯжisPrimeБЛgetPrimeКЏЪ§inlineСЫЃЌетЪЧгЩгкcandidateгаГѕЪМжЕЃЌinlineКѓПЩвдзіГЃСПелЕўЃЛ СэЭтвЛЗНУцЃЌisPrimeЪЧstaticКЏЪ§ЃЌЧвжЛгаgetPrimeЕїгУСЫЫќЃЌinlineжЎКѓЃЌПЩвдНЋетИіКЏЪ§ЕБзїdead codeЩОГ§ЃЌМѕаЁДњТыЬхЛ§ЁЃ
- МьВщsource-ltoЕФЛуБр
1. ПЩвдПДЕНГ§СЫscanfжЎЭтЕФЫљгаКЏЪ§ЖМБЛзїЮЊСЫФкСЊКЏЪ§ЃЌвђЮЊдкGCC LTOЕФWPAНзЖЮ, етаЉКЏЪ§ЕФЖЈвхЖМЪЧ ПЩМћЕФЁЃВЂЧвЃЌгЩnБрвыЪБПЬвбжЊЃЌБрвыЦїдкБрвыЪБПЬОЭЛсЭъГЩКЏЪ§square(n), cube(n)ЃЌsum(n)КЭ sumOfCubes(n)ЕФМЦЫуЁЃ 2. LTOЛёЕУСЫ30%вдЩЯЕФадФмЬсЩ§
- НсТл
1. ФГаЉгХЛЏЃЌЕБЦфзїгУгкећИіГЬађМЖБ№ЪБЃЌЭљЭљБШЦфзїгУгкОжВПЪБИќМггааЇЃЌКЏЪ§ФкСЊОЭЪЧетжжРраЭЕФгХЛЏжЎвЛЁЃ 2. ЪТЪЕЩЯЃЌДѓЖрЪ§гХЛЏЖМдкШЋОжЗЖЮЇФкЖМИќМггааЇЃЌетвВОЭЪЧЮвУЧБрвыДѓаЭгІгУГЬађЪБЃЌЭЦМіЪЙгУLTOЕФдвђКЭРэгЩЁЃ 3. FireFoxЁЂChromeЁЂ MysqlЕШДѓаЭгІгУЪЙгУLTO buildЖМЛёЕУСЫ5%-15%ВЛЕШЕФадФмЬсЩ§
---------------------------------------------------------------------------------------
ИќЖрЕїгХаХЯЂЃЌЧыВЮПМЃК
СњђсЩчЧјЃКhttps://openanolis.cn/
KeenTune SIGЃКhttps://openanolis.cn/sig/KeenTune
АЂРядЦСњђсВйзїЯЕЭГзЈЧјЃК/group/aliyun_linux