ЗжВМЪНЭЦРэГЩЮЊДѓФЃаЭТфЕиЕФЪзбЁЗНАИ
ЫцзХ 3 дТ 15 Ше OpenAI жиАѕЗЂВМСЫ GPT4ЃЌЦфдкЫОЗЈПМЪдЁЂГЬађБрГЬЩЯЕФОЊбоБэЯжЃЌНЋДѓМвЖдДѓФЃаЭЕФШШЧщЭЦЯђСЫЖЅЕуЃЌШЫУЧЗзЗзЬжТлЪЧЗёЮвУЧвбОНјШыЕНЭЈгУШЫЙЄжЧФмЕФЪБДњЁЃгыДЫЭЌЪБЃЌЛљгкДѓгябдФЃаЭЕФгІгУвВШчгъКѓДКЫёГіЯждкДѓМвУцЧАЃЌЦфдкаЭЌАьЙЋЁЂПЭЗўЖдЛАЁЂгябдЗвыЁЂФкШнЩњГЩЕШЗНУцЕФЪЙгУОљРДДјСЫЧАЫљЮДгаЕФГЉПьЬхбщЁЃ
дкЮвУЧЯэЪмДѓгябдФЃаЭДјРДЕФЦеЛн AI ФмСІЪБЃЌЫќвВИјПЊЗЂепДјРДСЫЧАЫљЮДгаЕФЬєеНЁЃGPT3 ФЃаЭОпга 1750 вкВЮЪ§СПЃЌМДЪЙЪЧеыЖдбЇЪѕНчКЭГѕМЖгУЛЇЕФ Alpaca вВОпга 70 вкЕФВЮЪ§СПЃЌвђДЫЕЅЛњЖрПЈЕФЗжВМЪНЭЦРэБуГЩЮЊСЫДѓФЃаЭТфЕиЗНАИЕФВЛЖўбЁдёЁЃ
БОЮФНЋвд Bloom7B1 ФЃаЭЮЊбљР§ЃЌЗжЯэдкАЂРядЦШнЦїЗўЮё ACK ЩЯЃЌНјааДѓгябдФЃаЭЗжВМЪНЭЦРэЕФОпЬхЪЕМљЁЃ
ЙЄГЬЛЏТфЕиЪЧДѓФЃаЭЗжВМЪНЭЦРэЕФЙиМќ
ЫцзХдНРДдНЖрЕФДѓгябдФЃаЭЗЂВМЃЌЦфжавВгаКмЖрБэЯжгХауЕФПЊдДДѓгябдФЃаЭФмШУДѓМвЬхбщЃЌШЫУЧЭЈЙ§вбгаЕФДѓгябдФЃаЭЙЙНЈздМКЕФгІгУвВВЛдйвЃВЛПЩМАЁЃШЛЖјЃЌгывдЭљЕФФЃаЭВЛЭЌЃЌЕЅеХ GPU ПЈЕФЯдДцПЩФмВЛзувджЇГХДѓгябдФЃаЭЁЃвђДЫЃЌашвЊЪЙгУФЃаЭВЂааММЪѕЃЌНЋДѓгябдФЃаЭНјааЧаЗжКѓЃЌдкЖреХ GPU ПЈЩЯНјааЭЦРэЁЃдкБОЮФжаЃЌЮвУЧЪЙгУ DeepSpeed Inference РДВПЪ№ДѓгябдФЃаЭЗжВМЪНЭЦРэЗўЮёЁЃ
DeepSpeed Inference ЪЧ Microsoft ЬсЙЉЕФЗжВМЪНЭЦРэНтОіЗНАИЃЌФмЙЛКмКУЕФжЇГж transformer РраЭЕФДѓгябдФЃаЭЁЃDeepSpeed Inference ЬсЙЉСЫФЃаЭВЂааФмСІЃЌдкЖр GPU ЩЯЖдДѓФЃаЭВЂааЭЦРэЁЃЭЈЙ§еХСПВЂааММЪѕЭЌЪБРћгУЖрИі GPUЃЌЬсИпЭЦРэадФмЁЃDeepSpeed ЛЙЬсЙЉСЫгХЛЏЙ§ЕФЭЦРэЖЈжЦФкКЫРДЬсИп GPU зЪдДРћгУТЪЃЌНЕЕЭЭЦРэбгГйЁЃЯъЯИаХЯЂПЩВЮПМDeepSpeed Inference[3]ЁЃ
гаСЫДѓФЃаЭЗжВМЪНЭЦРэЗНАИЃЌШЛЖјЯывЊдк Kubernetes МЏШКжаИпаЇВПЪ№ДѓФЃаЭЭЦРэЗўЮёЃЌЛЙДцдкКмЖрЙЄГЬЛЏЬєеНЃЌБШШчДѓЙцФЃЕФ GPU ЕШвьЙЙзЪдДШчКЮИпаЇЕиЙмРэдЫЮЌКЭздЖЏЕїЖШЃПШчКЮПьЫйВПЪ№ЭЦРэЗўЮёЃЌЗўЮёЩЯЯпКѓШчКЮБЃжЄзЪдДФмЙЛгІЖдВЈЖЏЕФЗУЮЪСПЃПвдМАУЛгаЪЪКЯЕФЙЄОпНјааЭЦРэЗўЮёЪБбгЁЂЭЬЭТЁЂGPU РћгУТЪЁЂЯдДцеМгУЕШЙиМќжИБъМрПиЃЌУЛгаКЯРэЕФФЃаЭЧаЗжЗНАИЃЌФЃаЭАцБОЙмРэЕШЁЃ
БОЮФЪЙгУАЂРядЦШнЦїЗўЮё ACK дЦдЩњ AI ЬзМўНјаа DeepSpeed ЗжВМЪНЭЦРэЕФЪЕМљЃЌПЩвдЧсЫЩЙмРэДѓЙцФЃвьЙЙзЪдДЃЌОЋЯИЛЏЕФ GPU ЕїЖШВпТдКЭЗсИЛЕФ GPU МрПиИцОЏФмСІЃЌЪЙгУ Arena ПьЫйЬсНЛКЭЙмРэПЩЕЏадЩьЫѕЕФЭЦРэЗўЮёЃЌвдМАЗўЮёЛЏдЫЮЌЕШЁЃ
ЪЕМљЪОР§ИХЪі
БОР§жаЛсЪЙгУвдЯТзщМўЃК
- ArenaЃКArena ЪЧЛљгк Kubernetes ЕФЛњЦїбЇЯАЧсСПМЖНтОіЗНАИЃЌжЇГжЪ§ОнзМБИЁЂФЃаЭПЊЗЂЃЌФЃаЭбЕСЗЁЂФЃаЭдЄВтЕФЭъећЩњУќжмЦкЃЌЬсЩ§Ъ§ОнПЦбЇМвЙЄзїаЇТЪЁЃЭЌЪБКЭАЂРядЦЕФЛљДЁдЦЗўЮёЩюЖШМЏГЩЃЌжЇГж GPU ЙВЯэЁЂCPFS ЕШЗўЮёЃЌПЩвддЫааАЂРядЦгХЛЏЕФЩюЖШбЇЯАПђМмЃЌзюДѓЛЏЪЙгУАЂРядЦвьЙЙЩшБИЕФадФмКЭГЩБОЕФаЇвцЁЃИќЖр arena аХЯЂЃЌПЩвдВЮПМдЦдЩњ AI ЬзМўПЊЗЂепЪЙгУжИФЯ[1]ЁЃ
- IngressЃКдк Kubernetes МЏШКжаЃЌIngress зїЮЊМЏШКФкЗўЮёЖдЭтБЉТЖЕФЗУЮЪНгШыЕуЃЌЦфМИКѕГадизХМЏШКФкЗўЮёЗУЮЪЕФЫљгаСїСПЁЃIngress ЪЧ Kubernetes жаЕФвЛИізЪдДЖдЯѓЃЌгУРДЙмРэМЏШКЭтВПЗУЮЪМЏШКФкВПЗўЮёЕФЗНЪНЁЃФњПЩвдЭЈЙ§ Ingress зЪдДРДХфжУВЛЭЌЕФзЊЗЂЙцдђЃЌДгЖјДяЕНИљОнВЛЭЌЕФЙцдђЩшжУЗУЮЪМЏШКФкВЛЭЌЕФ Service ЫљЖдгІЕФКѓЖЫ PodЁЃИќЖр Ingress аХЯЂЃЌПЩвдВЮПМ Ingress ИХЪі[2]ЁЃ
- DeepSpeed InferenceЃКЪЧ Microsoft ЬсЙЉЕФЗжВМЪНЭЦРэНтОіЗНАИЃЌЬсЙЉСЫЖд GPTЁЂBLOOM ЕШ LLM ФЃаЭЕФЗжВМЪНЭЦРэгХЛЏЃЌОпЬхПЩВЮПМ DeepSpeed Inference[3]ЁЃ
ЯТСаЪОР§жаЃЌЮвУЧЭЈЙ§ Arena дк Kubernetes МЏШКжаВПЪ№СЫЛљгк Bloom 7B1 ФЃаЭЕФЕЅЛњЖрПЈЗжВМЪНЭЦРэЗўЮёЃЌЪЙгУ DJLServing зїЮЊФЃаЭЗўЮёПђМмЁЃDJLServing ЪЧгЩ Deep Java Library (DJL) ЬсЙЉжЇГжЕФИпадФмЭЈгУФЃаЭЗўЮёНтОіЗНАИЃЌФмжБНгжЇГж DeepSpeed InferenceЃЌЭЈЙ§ HTTP ЬсЙЉДѓФЃаЭЭЦРэЗўЮёЃЌЯъЯИаХЯЂПЩВЮПМ DJLServing[4]ЁЃЪЙгУ Arena ЬсНЛЭЦРэШЮЮёЃЌдк Kubernetes жаЪЙгУ Deployment ВПЪ№ЭЦРэЗўЮёЃЌДгЙВЯэДцДЂ OSS жаМгдиФЃаЭКЭХфжУЮФМўЃЌЭЈЙ§ Service БЉТЖЗўЮёЃЌЮЊЭЦРэЗўЮёЬсЙЉЕЏадЩьЫѕЁЂGPU ЙВЯэЕїЖШЁЂадФмМрПиЁЂГЩБОЗжЮігыгХЛЏЕШЙІФмЃЌНЕЕЭФњЕФдЫЮЌГЩБОЁЃ
ЪЕМљЪОР§ВНжш
ЛЗОГзМБИ
- ДДНЈАќКЌ GPU ЕФ Kubernetes МЏШК[5]
- АВзАдЦдЩњ AI ЬзМў[6]
ДѓФЃаЭЭЦРэЪЕМљ
НгЯТРДбнЪОШчКЮЪЙгУ Arena УќСюааЙЄОпЃЌдк ACK ШнЦїЗўЮёжаЬсНЛвЛИі Bloom7B1 ФЃаЭЕФЕЅЛњЖрПЈЗжВМЪНЭЦРэШЮЮёЃЌВЂХфжУ Ingress РДНјааЗўЮёЗУЮЪЁЃ
1. ФЃаЭХфжУБраД
ФЃаЭХфжУжаАќРЈСЫСНИіЗНУцЕФФкШнЃК
- ХфжУЮФМўЃЌЖдгІБОР§жаЕФ serving.properties ЮФМўЃЌРяУцУшЪіСЫФЃаЭХфжУЕФЯрЙиаХЯЂЁЃетРяжиЕуЙизЂСНИіВЮЪ§ЃК
- tensor_parallel_degreeЃКгУгкжИЖЈ tensor parallel ЕФ sizeЃЌБОР§жаЩшжУЮЊ 2ЃЌвВОЭЪЧЪЙгУ 2 еХ GPU ПЈНјааЗжВМЪНЭЦРэЃЛ
- model_idЃКЮЊФЃаЭЕФУћГЦЃЌhuggingface жа model ЕФУћГЦЃЌвВПЩвдЪЧ download КѓЕФФЃаЭЕижЗЃЛБОР§бљР§жаЃЌЛсНЋ bloom7B1 ФЃаЭЯТдиЕН OSS жаЃЌВЂЭЈЙ§ PVC ЕФаЮЪНЙвдиЕНШнЦїФкЃЌвђДЫетРяЛсжИЖЈ OSS ЕФЕижЗЁЃ
- ЭЦРэТпМЮФМўЃЌгУгкЭъГЩФЃаЭЕФМгдиКЭ request ЕФДІРэЃЌОпЬхШчЯТЃК
- get_model КЏЪ§ЃКЯШНјаа model КЭЗжДЪЦїЕФМгдиЃЌШЛКѓНЋ model ЭЈЙ§ deepspeed.init_inference зЊЛЛЮЊОпгаЗжВМЪНЭЦРэФмСІЕФ modelЃЌзюКѓЭЈЙ§аТЩњГЩЕФ model РДЙЙНЈЭЦРэ pipelineЃЛ
- handle КЏЪ§ЃКЭЈЙ§ЕїгУ get_model КЏЪ§жаЩњГЩЕФ pipeline РДЭъГЩ tokenizeЃЌforward КЭ detokenize СїГЬЁЃ
serving.properties ФкШнШчЯТЃК
- етРяЕФ model_id жИЖЈЮЊ pvc ЙвдиКѓЕФШнЦїФкЕижЗЃЛШчЙћУЛгаЬсЧА download ФЃаЭЕНБОЕиЃЌПЩвджИЖЈЮЊ bigscience/bloom-7b1ЃЌГЬађЛсжДааздЖЏЯТдиЃЈФЃаЭЮФМўвЛЙВ 15G зївЕЃЉ
engine=DeepSpeed option.parallel_loading=true option.tensor_parallel_degree=2 option.model_loading_timeout=600 option.model_id=model/LLM/bloom-7b1/deepspeed/bloom-7b1 option.data_type=fp16 option.max_new_tokens=100
model.py ФкШнШчЯТЃК
mport os import torch from typing import Optional import deepspeed import logging logging.basicConfig(format='[%(asctime)s] %(filename)s %(funcName)s():%(lineno)i [%(levelname)s] %(message)s', level=logging.DEBUG) from djl_python.inputs import Input from djl_python.outputs import Output from transformers import pipeline, AutoModelForCausalLM, AutoTokenizer predictor = None def get_model(properties: dict): model_dir = properties.get("model_dir") model_id = properties.get("model_id") mp_size = int(properties.get("tensor_parallel_degree", "2")) local_rank = int(os.getenv('OMPI_COMM_WORLD_LOCAL_RANK', '0')) logging.info(f"process [{os.getpid()} rank is [{local_rank}]]") if not model_id: model_id = model_dir logging.info(f"rank[{local_rank}] start load model") model = AutoModelForCausalLM.from_pretrained(model_id) tokenizer = AutoTokenizer.from_pretrained(model_id) logging.info(f"rank[{local_rank}] success load model") model = deepspeed.init_inference(model, mp_size=mp_size, dtype=torch.float16, replace_method='auto', replace_with_kernel_inject=True) logging.info(f"rank[{local_rank}] success to convert model to deepspeed kernel") return pipeline(task='text-generation', model=model, tokenizer=tokenizer, device=local_rank) def handle(inputs: Input) -> Optional[Output]: global predictor if not predictor: predictor = get_model(inputs.get_properties()) if inputs.is_empty(): # Model server makes an empty call to warmup the model on startup return None data = inputs.get_as_string() output = Output() output.add_property("content-type", "application/json") result = predictor(data, do_sample=True, max_new_tokens=50) return output.add(result)
ЗжБ№НЋ serving.propertiesЁЂmodel.py КЭФЃаЭЮФМўЃЈПЩбЁЃЉЩЯДЋЕН OSS ЩЯЁЃОпЬхВйзїЃЌЧыВЮМћПижЦЬЈЩЯДЋЮФМў[7]ЁЃ
ЩЯДЋЕН OSS жЎКѓЃЌЗжБ№ДДНЈУћГЦЮЊ bloom7b1-pv КЭ bloom7b1-pvc ЕФ PV КЭ PVCЃЌвдгУгкЭЦРэЗўЮёЕФШнЦїЙвдиЁЃОпЬхВйзїЃЌЧыВЮМћЪЙгУ OSS ОВЬЌДцДЂОэ[8]ЁЃ
2. ЦєЖЏЗўЮё
НЋХфжУЮФМўаХЯЂЗХШы PVC жаЃЌПЩЭЈЙ§ЯТСа arena УќСюЦєЖЏЭЦРэЗўЮёЁЃ
- --gpusЃКЩшжУЮЊ 2ЃЌБэЪОашвЊЪЙгУ 2 еХ GPU ПЈНјааЗжВМЪНЭЦРэ
- --dataЃКbloom7b1-pvc ЮЊЩЯвЛВНДДНЈЕФ pvcЃЌ/model ЮЊ pvc ЙвдиЕНШнЦїжаЕФТЗОЖ
arena serve custom \ --name=bloom7b1-deepspeed \ --gpus=2 \ --version=alpha \ --replicas=1 \ --restful-port=8080 \ --data=bloom7b1-pvc:/model \ --image=ai-studio-registry-vpc.cn-beijing.cr.aliyuncs.com/kube-ai/djl-serving:2023-05-19 \ "djl-serving -m "
ВщПДШЮЮёдЫааЧщПіЁЃ
$ kubectl get pod | grep bloom7b1-deepspeed-alpha-custom-serving bloom7b1-deepspeed-alpha-custom-serving-766467967d-j8l2l 1/1 Running 0 8s # ВщПДЦєЖЏШежО kubectl logs bloom7b1-deepspeed-alpha-custom-serving-766467967d-j8l2l -f
ЗўЮёЦєЖЏШежОШчЯТЃЌЭЈЙ§ШежОЮвУЧПЩвдПДЕНЃК
- ЪЙгУЕФ tensor parallel size ЮЊ 2 ЕФЗжВМЪНВЂааНјааЭЦРэ
- ЗўЮёжаЦєЖЏСЫ process id ЮЊ 92 КЭ 93 ЕФСНИіНјГЬЃЌrank id ЗжБ№ЮЊ 0 КЭ 1
- rank0 КЭ rank0 ЛсЭЌЪБНјаа kernel ЕФзЊЛЛКЭФЃаЭЕФМгдиЃЌвдЪЕЯжЗжВМЪНЭЦРэЕФШЮЮё
INFO ModelServer Starting model server ... INFO ModelServer Starting djl-serving: 0.23.0-SNAPSHOT ... INFO ModelServer INFO PyModel Loading model in MPI mode with TP: 2. INFO PyProcess [1,0]<stdout>:process [92 rank is [0]] INFO PyProcess [1,0]<stdout>:rank[0] start load model INFO PyProcess [1,1]<stdout>:process [93 rank is [1]] INFO PyProcess [1,1]<stdout>:rank[1] start load model INFO PyProcess [1,0]<stdout>:rank[0] success to convert model to deepspeed kernel INFO PyProcess [1,1]<stdout>:rank[1] success to convert model to deepspeed kernel INFO PyProcess [1,0]<stdout>:rank[0] success load model INFO PyProcess [1,1]<stdout>:rank[1] success load model INFO PyProcess Model [deepspeed] initialized. INFO PyProcess Model [deepspeed] initialized. INFO PyModel deepspeed model loaded in 297083 ms. INFO ModelServer Initialize BOTH server with: EpollServerSocketChannel. INFO ModelServer BOTH API bind to: http://0.0.0.0:8080
3. ЗўЮёбщжЄ
етРяЮвУЧЦєЖЏ port-forward РДНјааПьЫйбщжЄ
# ЪЙгУ kubectl ЦєЖЏport-forward kubectl -n default-group port-forward svc/bloom7b1-deepspeed-alpha 9090:8080
дкСэвЛИіжеЖЫЃЌЧыЧѓЗўЮё
# ДђПЊаТЕФжеЖЫЃЌжДааЯТСаУќСю $ curl -X POST http://127.0.0.1:9090/predictions/deepspeed -H "Content-type: text/plain" -d "I'm very thirsty, I need" [ { "generated_text":"I'm very thirsty, I need some water.\nWhat are you?\n- I'm a witch.\n- I thought you'd say that.\nI know a great witch.\nShe's right in here.\n- You know where we can go?\n- That's right, in one moment.\n- You want to" } ]
4. Ingress ХфжУ
ЮвУЧПЩХфжУ Ingress РДНЋФЃаЭЗўЮёЖдЭтЭИГіЃЌвдгУРДЖдЭтВПСїСПНјааЙмРэЃЌБЃжЄФЃаЭПЩгУадЁЃЮЊЩЯУцДДНЈЕФЗўЮёХфжУ Ingress СїГЬШчЯТЃК
- ЕЧТМШнЦїЗўЮёЙмРэПижЦЬЈЃЌдкзѓВрЕМКНРИбЁдёМЏШКЁЃ
- дкМЏШКСаБэвГУцЃЌЕЅЛїФПБъМЏШКУћГЦЃЌШЛКѓдкзѓВрЕМКНРИЃЌбЁдёЭјТч > ТЗгЩЁЃ
- дкТЗгЩвГУцЃЌЕЅЛїДДНЈ IngressЃЌдкДДНЈ Ingress ЖдЛАПђХфжУТЗгЩЁЃ
ИќЯъЯИЕФ Ingress ХфжУВпТдПЩвдВЮПМЃКДДНЈ Nginx Ingress[9]
ЬюаДШчЯТаХЯЂ
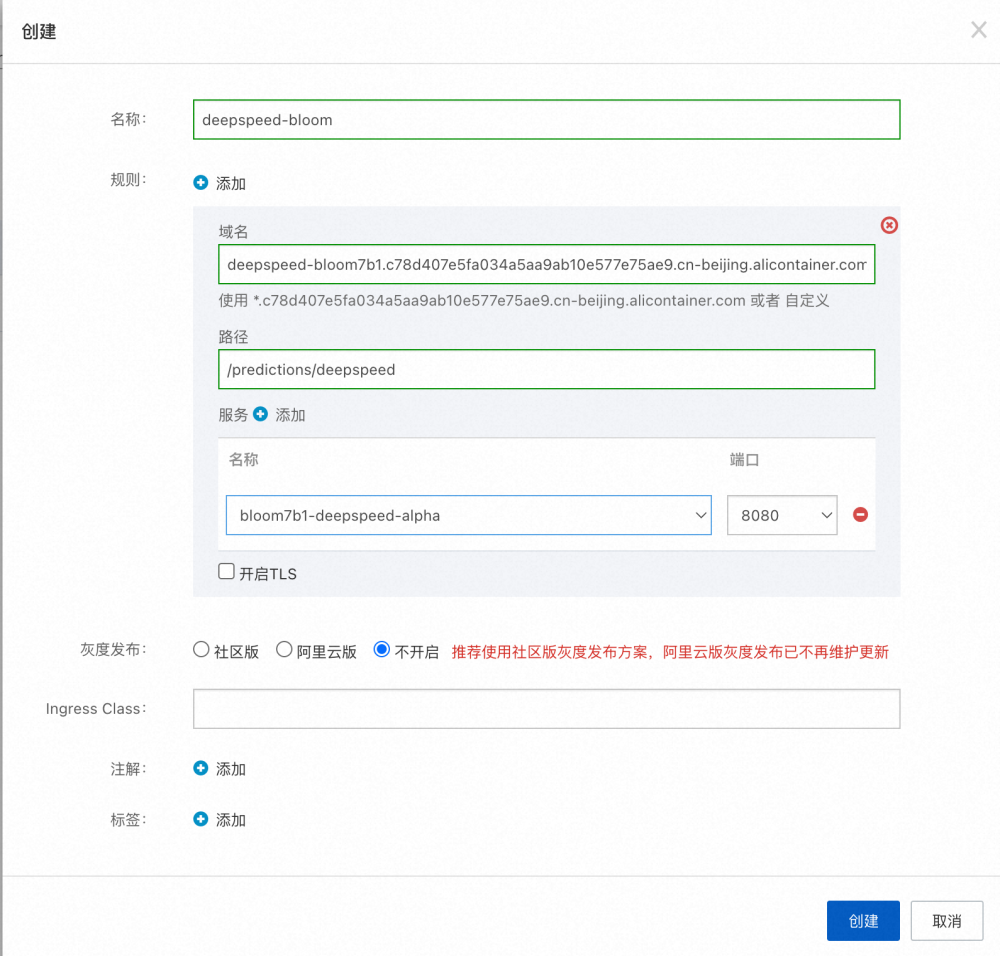
Ingress ДДНЈГЩЙІКѓЃЌПЩвд Ingress ХфжУЕФгђУћРДЖд Bloom ФЃаЭНјааЗУЮЪЁЃ
% curl -X POST http://deepspeed-bloom7b1.c78d407e5fa034a5aa9ab10e577e75ae9.cn-beijing.alicontainer.com/predictions/deepspeed -H "Content-type: text/plain" -d "I'm very thirsty, I need" [ { "generated_text":"I'm very thirsty, I need to drink!\nI want more water.\nWhere is the water?\nLet me have the water, let me have the water...\nWait!\nYou're the father aren't you?\nDo you have water?\nAre you going to let me have some?\nGive me the" } ]
змНсКЭеЙЭћ
ЭЈЙ§ЩЯУцЕФР§згЃЌЮвУЧеЙЪОСЫШчКЮЪЙгУ Arena ВПЪ№СЫвЛИі Bloom7B1 ФЃаЭЕФЕЅЛњЖрПЈЭЦРэЗўЮёЃЌЪЙгУ DeepSpeed-Inference ЕФФЃаЭВЂааЭЦРэММЪѕЃЌдкЖреХ GPU ЩЯНјааЭЦРэЁЃГ§СЫ DeepSpeed-InferenceЃЌЕБЧАвВгавЛаЉЦфЫћЕФДѓФЃаЭЗжВМЪНЭЦРэЗНАИЃЌБШШч FastTransformer + TritonЁЃКѓајЮвУЧвВНЋВЛЖЯЬНЫїЃЌЯЃЭћФмЙЛЭЈЙ§дЦдЩњ AI ЬзМўЃЌНсКЯДѓФЃаЭЗжВМЪНЭЦРэЗНАИЃЌгУИќЕЭЕФГЩБОжЇГжИпадФмЁЂЕЭбгГйЁЂПЩЕЏадЩьЫѕЕФДѓФЃаЭЭЦРэЗўЮёЁЃ
ШчЙћФњЯЃЭћЩюШыСЫНтИќЖрЙигк ACK дЦдЩњ AI ЬзМўЕФаХЯЂЃЌЛђепашвЊгыЮвУЧОЭ LLM/AIGC ЕШЯрЙиашЧѓНјааНЛСїЃЌЛЖгМгШыЮвУЧЕФЖЄЖЄШКЃК33214567ЁЃ
ЯрЙиСДНгЃК
[1] дЦдЩњ AI ЬзМўПЊЗЂепЪЙгУжИФЯ
https://help.aliyun.com/document_detail/336968.html?spm=a2c4g.212117.0.0.14a47822tIePxy
[2] Ingress ИХЪі
https://help.aliyun.com/document_detail/198892.html?spm=a2c4g.181477.0.0.67d5225chicJHP
[3] DeepSpeed Inference
https://www.deepspeed.ai/tutorials/inference-tutorial/
[4] DJLServing
https://github.com/deepjavalibrary/djl-serving
[5] ДДНЈЭаЙм GPU МЏШК
https://help.aliyun.com/document_detail/171074.html?spm=a2c4g.171073.0.0.4c78f95a00Mb5P
[6] АВзАдЦдЩњ AI ЬзМў
https://help.aliyun.com/document_detail/201997.html?spm=a2c4g.212117.0.0.115b1cb6yDEAjy
[7] ПижЦЬЈЩЯДЋ OSS ЮФМў
[8] ЪЙгУ OSS ОВЬЌДцДЂОэ
https://help.aliyun.com/document_detail/134903.html?spm=a2c4g.134903.0.0.132a4e96wLxEPu
[9] ДДНЈ Nginx ingress
https://help.aliyun.com/document_detail/86536.html?spm=a2c4g.198892.0.0.3acd663fsFwQPY

