iLogtailЪЧАЂРядЦШежОЗўЮёЃЈSLSЃЉЭХЖгздбаЕФПЩЙлВтЪ§ОнВЩМЏAgentЃЌгЕгаЕФЧсСПМЖЁЂИпадФмЁЂздЖЏЛЏХфжУЕШжюЖрЩњВњМЖБ№ЬиадЃЌПЩвдЪ№гкЮяРэЛњЁЂащФтЛњЁЂKubernetesЕШЖржжЛЗОГжаРДВЩМЏвЃВтЪ§ОнЁЃiLogtailдкАЂРядЦЩЯЗўЮёСЫЪ§ЭђМвПЭЛЇжїЛњКЭШнЦїЕФПЩЙлВтадВЩМЏЙЄзїЃЌдкАЂРяАЭАЭМЏЭХЕФКЫаФВњЦЗЯпЃЌШчЬдБІЁЂЬьУЈЁЂжЇИЖБІЁЂВЫФёЁЂИпЕТЕиЭМЕШвВЪЧФЌШЯЕФШежОЁЂМрПиЁЂTraceЕШЖржжПЩЙлВтЪ§ОнЕФВЩМЏЙЄОпЁЃФПЧАiLogtailвбгаЧЇЭђМЖЕФАВзАСПЃЌУПЬьВЩМЏЪ§ЪЎPBЕФПЩЙлВтЪ§ОнЃЌЙуЗКгІгУгкЯпЩЯМрПиЁЂЮЪЬтЗжЮі/ЖЈЮЛЁЂдЫгЊЗжЮіЁЂАВШЋЗжЮіЕШЖржжГЁОАЃЌдкЪЕеНжабщжЄСЫЦфЧПДѓЕФадФмКЭЮШЖЈадЁЃ
дкЕБНёдЦдЩњЕФЪБДњЃЌЮвУЧМсаХПЊдДВХЪЧiLogtailзюгХЕФЗЂеЙВпТдЃЌвВЪЧЪЭЗХЦфзюДѓМлжЕЕФЗНЗЈЁЃвђДЫЃЌЮвУЧОіЖЈНЋiLogtailПЊдДЃЌЦкЭћЭЌжкЖрПЊЗЂепвЛЦ№НЋiLogtailДђдьГЩЪРНчвЛСїЕФПЩЙлВтЪ§ОнВЩМЏЦїЁЃ
БГОА
ШежОзїЮЊПЩЙлВтадНЈЩшжаЕФживЊвЛЛЗЃЌПЩвдМЧТМЯъЯИЕФЗУЮЪЧыЧѓвдМАДэЮѓаХЯЂЃЌдквЕЮёЗжЮіЁЂЮЪЬтЖЈЮЛЕШЗНУцЭљЭљЛсЗЂЛгКмДѓЕФзїгУЁЃвЛАуПЊЗЂГЁОАЯТЃЌЕБашвЊНјааШежОЗжЮіЪБЃЌЭљЭљЪЧжБНгдкШежОЮФМўжаНјааgrepЫбЫїЖдгІЕФЙиМќзжЃЛЕЋдкДѓЙцФЃЗжВМЪНЩњВњЛЗОГЯТЃЌДЫЗНЗЈаЇТЪЕЭЯТЃЌГЃМћНтОіЫМТЗЪЧНЈСЂМЏжаЪНШежОЪеМЏЯЕЭГЃЌНЋЫљгаНкЕуЩЯЕФШежОЭГвЛЪеМЏЁЂЙмРэЁЂЗжЮіЁЃФПЧАЪаУцЩЯБШНЯжїСїЕФПЊдДЗНАИЪЧЛљгкELKЙЙНЈвЛЬзШежОВЩМЏЗжЮіЯЕЭГЁЃ

ИУМмЙЙжаЃЌFilebeatзїЮЊШежОдДЕФВЩМЏAgentВПЪ№дквЕЮёМЏШКЩЯНјаадЪМШежОВЩМЏЃЌВЂВЩМЏЕНЕФШежОЗЂЫЭЕНЯћЯЂЖгСаKafkaМЏШКЁЃжЎКѓЃЌгЩLogstashДгKafkaЯћЗбЪ§ОнЃЌВЂОЙ§Й§ТЫЁЂДІРэКѓЃЌНЋБъзМЛЏКѓЕФШежОаДШыElasticsearchМЏШКНјааДцДЂЁЃзюКѓЃЌгЩKibanaГЪЯжИјгУЛЇВщбЏЁЃЫфШЛИУМмЙЙПЩвдЬсЙЉБШНЯЭъећЕФШежОВЩМЏЁЂЗжЮіЙІФмЃЌЕЋЪЧећЬхЩцМАЕФзщМўЗЧГЃЖрЃЌДѓЙцФЃЩњВњЛЗОГВПЪ№ИДдгЖШИпЃЌЧвДѓСїСПЯТESПЩФмВЛЮШЖЈЃЌдЫЮЌГЩБОЖМЛсКмИпЁЃ
АЂРядЦЬсЙЉЕФSLSЗўЮёЪЧвЛИіДПЖЈЮЛдкШежО/ЪБађРрПЩЙлВтЪ§ОнЗжЮіГЁОАЕФдЦЩЯЭаЙмЗўЮёЃЌЯрЖдгкELKдкШежОСьгђФкзіСЫКмЖрЖЈжЦЛЏПЊЗЂЃЌдквзгУадЁЂЙІФмЭъБИадЁЂадФмЁЂГЩБОЕШЗНБуЃЌЖМгаВЛДэБэЯжЁЃiLogtailзїЮЊSLSЙйЗНБъХфЕФПЩЙлВтЪ§ОнВЩМЏЦїЃЌдкШежОВЩМЏадФмМАK8sжЇГжЩЯЖМгаВЛДэЕФЬхбщЃЛiLogtailгаУїЯдЕФадФмгХЪЦЃЌПЩвдНЋВПЗжЪ§ОнДІРэЧАжУЃЌгааЇНЕЕЭДцДЂГЩБОЁЃ
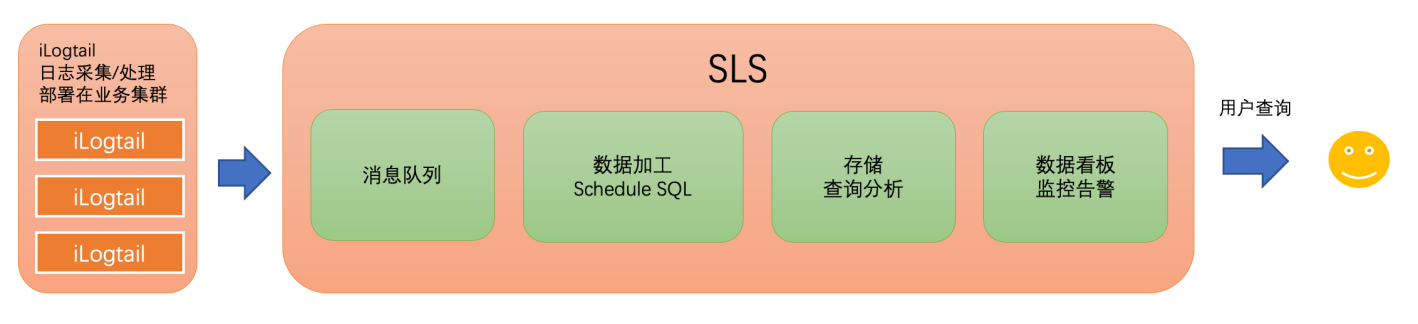
ФПЧАЩчЧјАцiLogtailвВЖдSLSЬсЙЉСЫКмКУЕФжЇГжЃЌБОЮФНЋЛсЯъЯИНщЩмШчКЮЪЙгУЩчЧјАцiLogtailЃЌВЂНсКЯSLSдЦЗўЮёПьЫйЙЙНЈГівЛЬзИпПЩгУЁЂИпадФмЕФШежОВЩМЏЗжЮіЯЕЭГЁЃ
БИзЂЃКiLogtailЩчЧјАцЯрЖдгкiLogtailЦѓвЕАцЃЌКЫаФВЩМЏФмСІЩЯЛљБОЪЧвЛжТЕФЃЌЕЋЪЧЙмПиЁЂПЩЙлВтФмСІЩЯЛсгаЫљШѕЛЏЃЌетаЉФмСІашвЊХфКЯSLSЗўЮёЖЫВХФмЗЂЛгГіРДЁЃЛЖгЪЙгУiLogtailЦѓвЕАцЬхбщЃЌСНИіАцБОВювьЯъМћСДНгЁЃ
SLSМђНщ
ШежОЗўЮёSLSЪЧдЦдЩњЙлВтгыЗжЮіЦНЬЈЃЌЮЊLogЁЂMetricЁЂTraceЕШЪ§ОнЬсЙЉДѓЙцФЃЁЂЕЭГЩБОЁЂЪЕЪБЕФЦНЬЈЛЏЗўЮёЁЃШежОЗўЮёвЛеОЪНЬсЙЉЪ§ОнВЩМЏЁЂМгЙЄЁЂВщбЏгыЗжЮіЁЂПЩЪгЛЏЁЂИцОЏЁЂЯћЗбгыЭЖЕнЕШЙІФмЃЌШЋУцЬсЩ§ФњдкбаЗЂЁЂдЫЮЌЁЂдЫгЊЁЂАВШЋЕШГЁОАЕФЪ§зжЛЏФмСІЁЃ
ЭЈЙ§SLSПЩвдПьЫйЕФДюНЈЪєгкздМКЕФПЩЙлВтЗжЮіЦНЬЈЃЌПЩвдПьЫйЯэЪмЕНSLSЬсЙЉЕФИїжжЪ§ОнЗўЮёЃЌАќРЈВЛЯогкЃКВщбЏгыЗжЮіЁЂПЩЪгЛЏЁЂИцОЏЕШЁЃ
- ВщбЏЗжЮі
- жЇГжОЋШЗВщбЏЁЂФЃК§ВщбЏЁЂШЋЮФВщбЏЁЂзжЖЮВщбЏЁЃ
- вдSQLзїЮЊВщбЏКЭЗжЮіПђМмЃЌЭЌЪБдкПђМмжаШкШыPromQLгяЗЈКЭЛњЦїбЇЯАКЏЪ§ЁЃ

- ПЩЪгЛЏ
- ЛљгкSLSЭГвЛЕФВщбЏЗжЮів§ЧцЃЌвдЭМБэЕФаЮЪННЋВщбЏгыЗжЮіНсЙћГЪЯжГіРДЃЌЧхЮњГЪЯжШЋОжЬЌЪЦЁЃ
- жЇГжгыЕкШ§ЗНПЩЪгЛЏЙЄОпЖдНгЁЃ
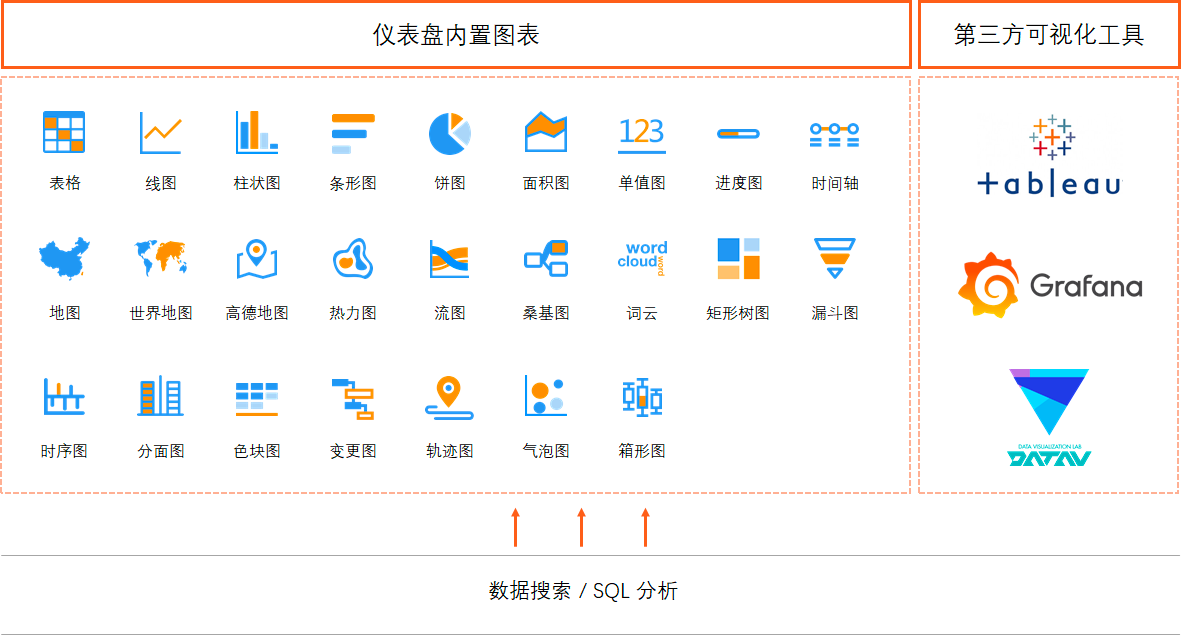
- МрПиИцОЏЃКЬсЙЉвЛеОЪНЕФИцОЏМрПиЁЂНЕдыЁЂЪТЮёЙмРэЁЂЭЈжЊЗжХЩЕФжЧФмдЫЮЌЦНЬЈЁЃ
ВйзїЪЕеН
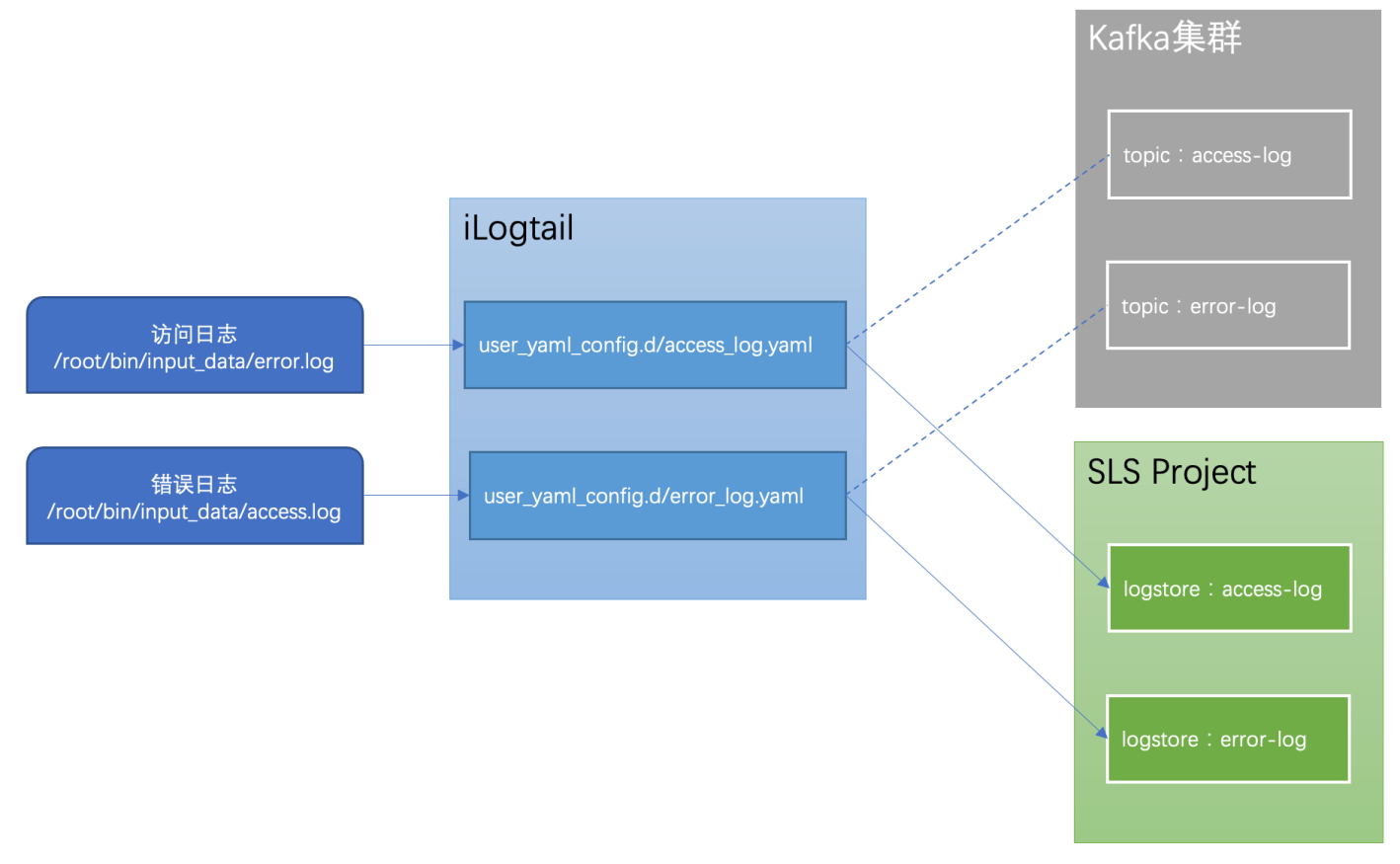
вдЯТНщЩмШчКЮЪЙгУiLogtailЩчЧјАцВЩМЏжїЛњЛЗОГвЕЮёШежОЕНSLSЁЃ
ГЁОА
ВЩМЏ/root/bin/input_data/access.logЁЂ/root/bin/input_data/error.logЃЌВЂНЋВЩМЏЕНЕФШежОаДШыSLSжаЁЃ
ЦфжаЃЌaccess.logашвЊе§дђНтЮіЃЛerror.logЮЊЕЅааЮФБОДђгЁЁЃ
ШчЙћжЎЧАвбОЪЙгУiLogtailНЋШежОВЩМЏЕНKafkaЃЌдкЧЈвЦНзЖЮПЩвдБЃГжЫЋаДЃЌЕШЮШЖЈКѓЩОГ§Kafka FlusherХфжУМДПЩЁЃ
ЧАЬсЬѕМў
- ЕЧТНАЂРядЦSLSПижЦЬЈЃЌПЊЭЈSLSЗўЮёЁЃ
- вбДДНЈвЛИіProjectЃЛСНИіlogstoreЃЌЗжБ№ЮЊaccess-logЁЂerror-logЁЃИќЖраХЯЂЃЌЧыВЮМћДДНЈProjectКЭДДНЈLogstoreЁЃ


АВзАiLogtail
- ЯТди
tar -xzvf ilogtail-1.1.0.linux-amd64.tar.gz
$ cd ilogtail-1.1.0
$ ll
drwxrwxr-x 5 505 505 4096 7дТ 10 18:00 example_config
-rwxr-xr-x 1 505 505 84242040 7дТ 11 00:00 ilogtail
-rwxr-xr-x 1 505 505 16400 7дТ 11 00:00 libPluginAdapter.so
-rw-r--r-- 1 505 505 115963144 7дТ 11 00:00 libPluginBase.so
-rw-rw-r-- 1 505 505 11356 7дТ 11 00:00 LICENSE
-rw-rw-r-- 1 505 505 5810 7дТ 11 00:00 README-cn.md
-rw-rw-r-- 1 505 505 4834 7дТ 11 00:00 README.md
-rw-rw-r-- 1 505 505 118 7дТ 14 11:22 ilogtail_config.json
drwxr-xr-x 2 root root 4096 7дТ 12 09:55 user_yaml_config.d
- ЛёШЁАЂРядЦAKЃЌВЂНјааХфжУЁЃ
$ cat ilogtail_config.json
{
"default_access_key_id": "xxxxxx",
"default_access_key": "yyyyy"
}
- ВЩМЏХфжУ
дкuser_yaml_config.dДДНЈеыЖдaccess_logЁЂerror_logЗжБ№ДДНЈСНИіВЩМЏХфжУЃЌСНИіВЩМЏХфжУЗжБ№НЋШежОВЩМЏЕНSLSВЛЭЌlogstore МАKafkaВЛЭЌЕФTopicжаЁЃЫЋаДЪЪгУгкДгKafkaЧЈвЦЕНSLSЕФГЁОАЃЌШчЙћЧЈвЦЭъГЩЮШЖЈКѓЃЌПЩвдЩОГ§flusher_kafkaЃЌжЛБЃСєflusher_slsМДПЩЁЃ
# ЗУЮЪШежОВЩМЏХфжУ
$ cat user_yaml_config.d/access_log.yaml
enable: true
inputs:
- Type: file_log
LogPath: /root/bin/input_data/
FilePattern: access.log
processors:
- Type: processor_regex
SourceKey: content
Regex: ([\d\.]+) \S+ \S+ \[(\S+) \S+\] \"(\w+) ([^\\"]*)\" ([\d\.]+) (\d+) (\d+) (\d+|-) \"([^\\"]*)\" \"([^\\"]*)\"
Keys:
- ip
- time
- method
- url
- request_time
- request_length
- status
- length
- ref_url
- browser
flushers:
- Type: flusher_sls
Endpoint: cn-hangzhou.log.aliyuncs.com
ProjectName: test-ilogtail
LogstoreName: access-log
- Type: flusher_kafka
Brokers:
- localhost:9092
Topic: access-log
# ДэЮѓШежОВЩМЏХфжУ
$ cat user_yaml_config.d/error_log.yaml
enable: true
inputs:
- Type: file_log
LogPath: /root/bin/input_data/
FilePattern: error.log
flushers:
- Type: flusher_sls
Endpoint: cn-hangzhou.log.aliyuncs.com
ProjectName: test-ilogtail
LogstoreName: access-log
- Type: flusher_kafka
Brokers:
- localhost:9092
Topic: error-log
$ tree user_yaml_config.d/
user_yaml_config.d/
ЉРЉЄЉЄ access_log.yaml
ЉИЉЄЉЄ error_log.yaml
- ЦєЖЏ
$ nohup ./ilogtail > stdout.log 2> stderr.log &
бщжЄ
- ЗУЮЪШежОбщжЄЃЌВщПДlogstoreЪ§Оне§ГЃЁЃ
# аДШыЗУЮЪШежО
$ echo '127.0.0.1 - - [10/Aug/2017:14:57:51 +0800] "POST /PutData?Category=YunOsAccountOpLog HTTP/1.1" 0.024 18204 200 37 "-" "aliyun-sdk-java"' >> /root/bin/input_data/access.log
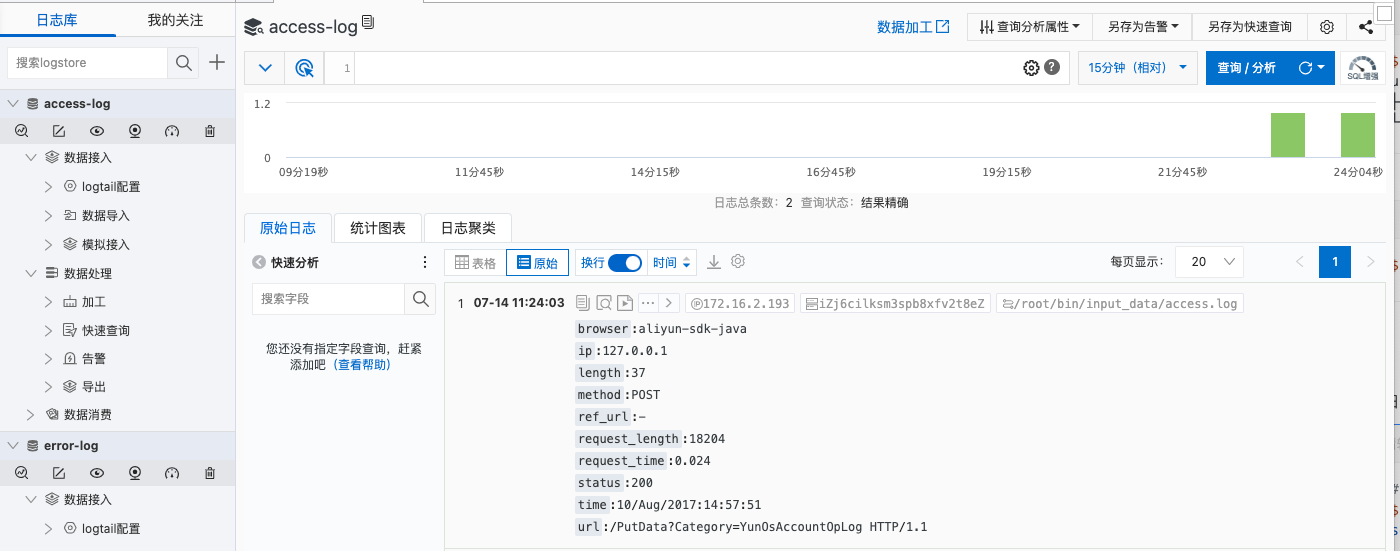
- ДэЮѓШежОбщжЄЃЌВщПДlogstoreЪ§Оне§ГЃЁЃ
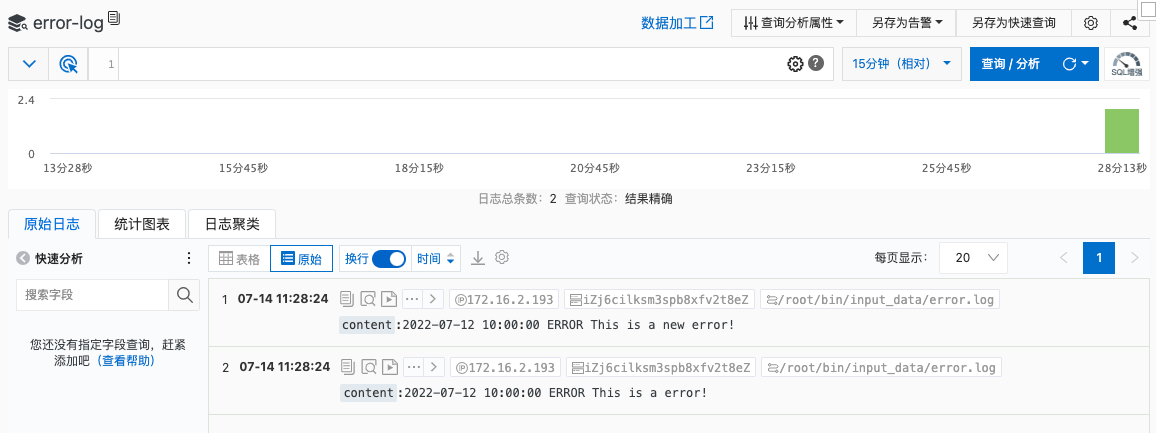
# аДШыДэЮѓШежО
$ echo -e '2022-07-12 10:00:00 ERROR This is a error!\n2022-07-12 10:00:00 ERROR This is a new error!' >> /root/bin/input_data/error.log
змНс
вдЩЯЃЌЮвУЧНщЩмСЫЪЙгУiLogtailЩчЧјАцНЋШежОВЩМЏЕНSLSЕФЗНЗЈЁЃШчЙћЯыЬхбщЦѓвЕАцiLogtailгыSLSИќЩюЖШЕФМЏГЩФмСІЃЌЛЖгЪЙгУiLogtailЦѓвЕАцЃЌВЂХфКЯSLSЙЙНЈПЩЙлВтЦНЬЈЁЃ
ЙигкiLogtail
iLogtailзїЮЊАЂРядЦSLSЬсЙЉЕФПЩЙлВтЪ§ОнВЩМЏЦїЃЌПЩвддЫаадкЗўЮёЦїЁЂШнЦїЁЂK8sЁЂЧЖШыЪНЕШЖржжЛЗОГЃЌжЇГжВЩМЏЪ§АйжжПЩЙлВтЪ§ОнЃЈШежОЁЂМрПиЁЂTraceЁЂЪТМўЕШЃЉЃЌвбОгаЧЇЭђМЖЕФАВзАСПЁЃФПЧАЃЌiLogtailвбе§ЪНПЊдДЃЌЛЖгЪЙгУМАВЮгыЙВНЈЁЃ
GitHub:https://github.com/alibaba/ilogtail
ЩчЧјАцЮФЕЕЃКhttps://ilogtail.gitbook.io/ilogtail-docs/about/readme
ЦѓвЕАцЙйЭјЃКhttps://help.aliyun.com/document_detail/65018.html
ЖЄЖЄШКЃКiLogtailЩчЧј

