ТлЮФЃКBERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
зїепЃКJacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova
ЪБМфЃК2018
ЕижЗЃКgoogle-research/bert: TensorFlow code and pre-trained models for BERT (github.com)
вЛЁЂЭъећДњТы
ЭъећДњТыШчЯТЃК
# ЭъећДњТыдкетРя import tensorflow as tf import keras_nlp dataset = tf.data.TextLineDataset( ['./data/CoLA_train.tsv'] ) def process_data(x): x = tf.strings.split(x, '\t') return x[3], x[1] dataset = dataset.map(process_data).batch(64, drop_remainder=True) vocabulary = keras_nlp.tokenizers.compute_word_piece_vocabulary( dataset.map(lambda x, y: x), vocabulary_size=4000, lowercase=True, strip_accents=True, ) tokenizer = keras_nlp.tokenizers.WordPieceTokenizer( vocabulary=vocabulary, sequence_length=None, lowercase=True, strip_accents=True, ) cls = tokenizer.vocabulary.index('[CLS]') sep = tokenizer.vocabulary.index('[SEP]') pad = tokenizer.vocabulary.index('[PAD]') segment_packer = keras_nlp.layers.MultiSegmentPacker( sequence_length=128, start_value=cls, end_value=sep, sep_value=sep, pad_value=pad, ) def process_data_(x, y): x = tokenizer(x) input_token, segment_token = segment_packer(x) padding_token = tf.cast(input_token != 0, dtype=tf.int32) x = { 'token_ids': input_token, 'segment_ids': segment_token, 'padding_mask': padding_token, } y = tf.strings.to_number(y, tf.int32) return x, y dataset = dataset.map(process_data_) import numpy as np def positional_encoding(length, depth): depth = depth/2 positions = np.arange(length)[:, np.newaxis] # (seq, 1) depths = np.arange(depth)[np.newaxis, :]/depth # (1, depth) angle_rates = 1 / (10000**depths) # (1, depth) angle_rads = positions * angle_rates # (pos, depth) pos_encoding = np.concatenate([np.sin(angle_rads), np.cos(angle_rads)],axis=-1) return tf.cast(pos_encoding, dtype=tf.float32) class Bert(tf.keras.Model): def __init__(self, vocabulary_size, d_model, encoder_num, intermediate_dim, num_heads, dropout=0.1): super().__init__() self.token_embedding = tf.keras.layers.Embedding(vocabulary_size, d_model) self.segment_embedding = tf.keras.layers.Embedding(2, d_model) self.position_embedding = positional_encoding(128, d_model) self.encoder = [keras_nlp.layers.TransformerEncoder( intermediate_dim=intermediate_dim, num_heads=num_heads, dropout=dropout, ) for _ in range(encoder_num)] self.add = tf.keras.layers.Add() # ЗжРрШЮЮё self.dense_1 = tf.keras.layers.Dense(128, activation='relu') self.dense_2 = tf.keras.layers.Dense(1, activation='sigmoid') def call(self, x): token_embedding = self.token_embedding(x['token_ids']) segment_embedding = self.segment_embedding(x['segment_ids']) position_embedding = tf.concat([positional_encoding(128, 512)[tf.newaxis]]*64, axis=0) output = self.add([token_embedding, segment_embedding, position_embedding]) for item in self.encoder: output = item(output) # дЄВтађСа # output = self.dense(output) # ЗжРрШЮЮё output = self.dense_1(output[:,0,:]) output = self.dense_2(output) return output bert = Bert(tokenizer.vocabulary_size(), 512, 8, 1024, 8) bert(s[0]) bert.summary() bert.compile( loss=tf.keras.losses.BinaryCrossentropy(), optimizer='adam', metrics=[tf.keras.metrics.BinaryAccuracy()] ) bert.fit(dataset, epochs=10) # ВЛжЊЕРГіЪВУДЮЪЬтЃЌaccuracyПЈзЁВЛЖЏСЫ
ЖўЁЂТлЮФНтЖС
ДгТлЮФЬтФПBERT: Pre-training of Deep Bidirectional Transformers for Language UnderstandingжаОЭПЩвдПДГіРДЃЌетЪЧвЛИігябдРэНтЕФдЄбЕСЗЕФЫЋЯђЕФTransformersФЃаЭЃЛ
BERTЦфШЋГЦЮЊBidirectional Encoder Representations from TransformersЃЛBERTЕФЩшМЦФПЕФЪЧЭЈЙ§дкЫљгаВужаСЊКЯЕїНкзѓгвЩЯЯТЮФЃЌДгЮДБъМЧЕФЮФБОжадЄбЕСЗЩюЖШЫЋЯђБэЪОЃЛ
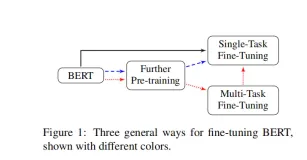
дЄЯШбЕСЗЙ§ЕФBERTФЃаЭПЩвджЛашЭЈЙ§вЛИіЖюЭтЕФЪфГіВуРДНјааЮЂЕїЃЌДгЖјЮЊЙуЗКЕФШЮЮёДДНЈзюЯШНјЕФФЃаЭЃЌШчЮЪЬтЛиД№КЭгябдЭЦРэЃЌЖјВЛашвЊНјааЪЕжЪадЕФШЮЮёЬиЖЈЕФЬхЯЕНсЙЙаоИФЁЃРрЫЦгкELMoЃЛ
вЛАуРДЫЕРћгУдЄбЕСЗгябдФЃаЭШЁЭъГЩЯТгЮШЮЮёгаСНжжЗНЪНЃКfeature-based and fine-tuningЃЛ
feature-basedЃКРрЫЦгкELMoЃЌАбBERTЕБзїДЪЧЖШыФЃаЭЃЌдйМгЩЯЬиЖЈЕФНсЙЙЃЌЖдЫљгадЄЯШбЕСЗКУЕФВЮЪ§ВЛдкНјаабЕСЗЃЛfine-tuningЃКРрЫЦгкGPTЃЌв§ШызюаЁЕФШЮЮёЬиЖЈВЮЪ§ЃЌВЂЭЈЙ§МђЕЅЕиЮЂЕїЫљгадЄЯШбЕСЗКУЕФВЮЪ§РДЖдЯТгЮШЮЮёНјаабЕСЗЃЛ
BertЕФНсЙЙгХЪЦШчЯТЫљЪОЃК
- ЪЙгУЫЋЯђгябдФЃаЭВЂНсКЯMLM(бкБЮгябдФЃаЭ)РДЪЕЯждЄбЕСЗЕФЩюЖШЃЛ
- дЄЯШбЕСЗЕФБэЪОМѕЩйСЫЖдаэЖрОЋаФЩшМЦЕФШЮЮёЬиЖЈМмЙЙЕФашЧѓЃЛ
- ЪЙгУИУдЄбЕСЗЬсИпСЫ11ИіNLPШЮЮёЕФзюаТЫЎЦНЃЛ
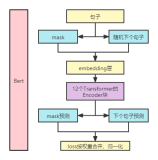
2.1 ФЃаЭМмЙЙ
BertЕФжївЊПђМмЪЧгЩTransformerжаЕФНтТыПщзщГЩЕФЃЌЯТЭМЪЧTransformerМмЙЙЃК

BERTгаbaseФЃаЭКЭlargeФЃаЭЃЛ
- baseЃКL=12, H=768, A=12, Total Parameters=110M
- largeЃКL=24, H=1024, A=16, Total Parameters=340M
ЦфжаLБэЪОEncoder BlockПщЪ§ЃЌHБэЪОвўВиВуЮЌЖШЃЌAБэЪОЖрЭЗзЂвтСІЕФЭЗЪ§
дкетРяЪЧВЛЪЧКмЦцЙжЃЌBertВЛЪЧBidirectional Encoder Representations from TransformersТ№ЃПЫЋЯђдкФФРяЃПетРявЊНтЪЭЕФЪЧЃЌTransformerЕФencoderФЃПщЦфБОжЪЪЧЖрСЌНгЕФЃЌетОЭЕМжТЦфПЩвдгыЧАУцЕФдЊЫиНЛЛЅЃЌвВПЩвдЖдКѓУцЕФдЊЫиНЛЛЅЃЌЫљвдНазіBidirectional EncoderБЛBERTЪЙгУЃЌЖјTransformerЕФdecoderашвЊcontextзіkeyКЭvalueЃЌЭЌЪБгаmaskЛњжЦЃЌбкИЧСЫКѓУцЕФаХЯЂЃЌШУЮФБОжЛзЂвтЕНЧАУцЕФаХЯЂЃЌЪЧвЛИіleft-to-rightЕФМмЙЙзіЕФЮФБОЩњГЩЃЛ

ФЃаЭМмЙЙШчЭМЃК
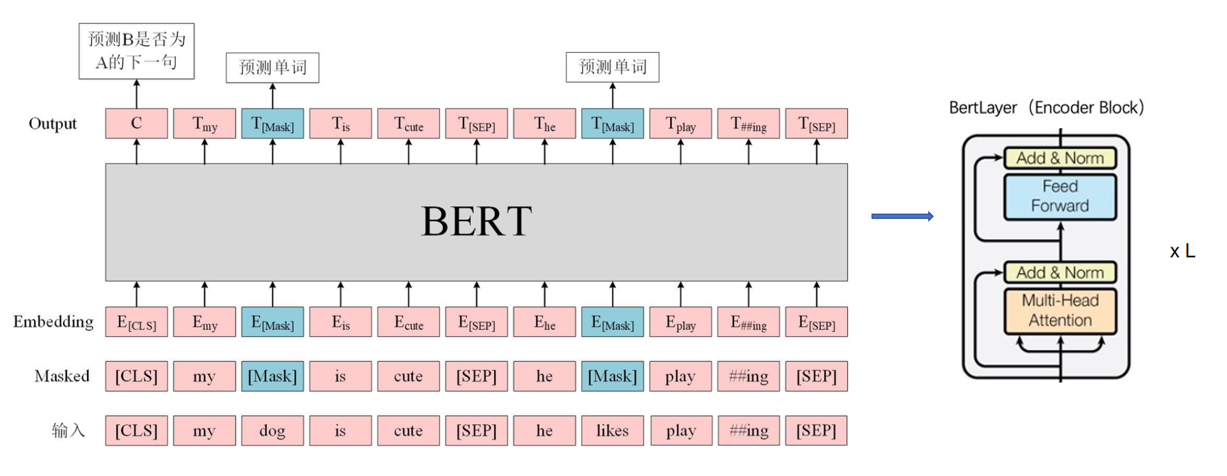
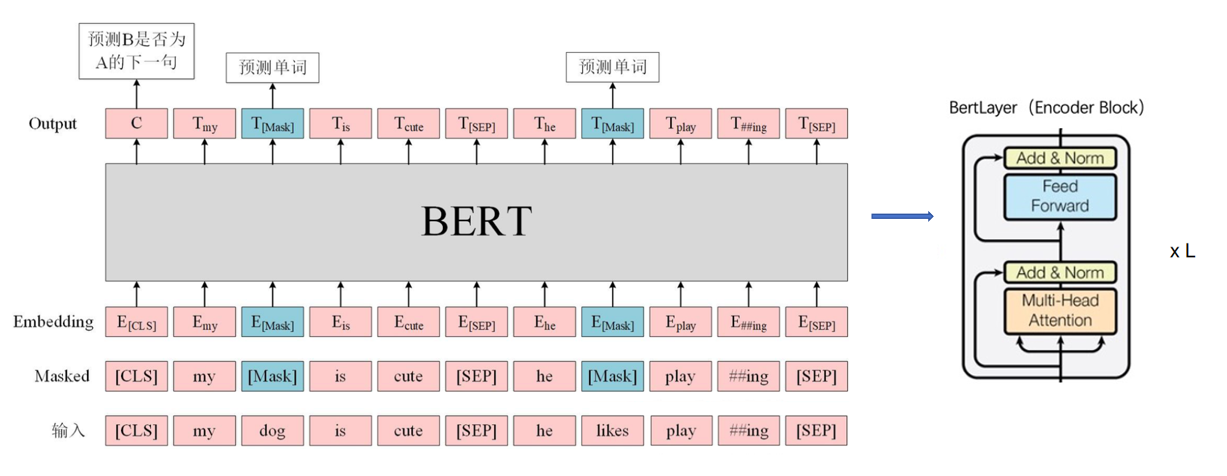
гаУЛгаИаОѕЗЧГЃМђЕЅЃЌЦфжаЮвИаОѕжЛашвЊзЂвтЕФЪЧЪфШыВуЕФКЭЪфГіВуЃЛЦфжагаСНИіЙиМќЕФФЃаЭMasked LMКЭNext Sentence PredictionЃЛ
2.2 ЪфШыВу
ЪзЯШгябдФЃаЭЕФЪфШыЛљБОЖМЪЧвЛДЎзжЗћДЎЃЌЕквЛВНвЊНјааЗжДЪДІРэЃЌТлЮФжаВЩШЁЕФАьЗЈЪЧWordPieceЃЌЦфФЃаЭЪЕЯжКмМђЕЅЃЌЮвжЎКѓЛсдкСэвЛЦЊЮФеТNLP: tokenizer-CSDNВЉПЭжаЖдЫљгаЕФNLP tokenizerНјааЗжЮіЃЌетРяВЛдйВћЪіЃЛ
ЗжДЪЪБашвЊзЂвтЕФЪЧЃЌsentencesБЛДђАќГЩвЛИіЕЅвЛЕФsequenceЃЌУПИіsequenceЕФЕквЛИіБъМЧзмЪЧвЛИіЬиЪтЕФЗжРрБъМЧ[CLS]ЁЃгыИУБъМЧЖдгІЕФзюжевўВизДЬЌБЛгУзїЗжРрШЮЮёЕФОлКЯађСаБэЪОЁЃЮвУЧгУСНжжЗНЪНРДЧјЗжетаЉОфзгЁЃЪзЯШЃЌЮвУЧгУвЛИіЬиЪтЕФБъМЧ[SEP]НЋЫќУЧЗжПЊЁЃ
ЗжДЪКѓЃЌЮвУЧАбmy dog is cute, he likes playingзЊЛЏЮЊСЫ['<cls>', 'my', 'dog', 'is', 'cute', '<sep>', 'he', 'likes', 'play', '##ing', '<sep>']
НгЯТРДОЭЪЧЙиМќФЃаЭMasked LMЃЛ
Masked LM
ДгжБОѕРДЫЕЃЌЩюЖШЕФЫЋЯђгябдФЃаЭвЊБШЧГВуЕФЕЅЯђФЃаЭИќЧПДѓЃЌвђЮЊЩюЖШФЃаЭПЩвдбЇЕНЕФЖЋЮїИќЗсИЛЃЛЕЋЪЧБъзМгябдФЃаЭЕФбЕСЗФЃЪНвЛАуЪЧleft-to-rightЛђепright-to-leftЃЌЖјbertЪЧвЛИіЫЋЯђЕФгябдФЃаЭЃЌдкбЕСЗЙ§ГЬжаПЩвдЧхГўЕФПДЕНЩЯЯТЮФаХЯЂЃЌЫљвдМђЕЅЕФЬсИпФЃаЭЕФЩюЖШВЂВЛФмЙЛШУЛњЦїИќКУЕФЩюШыРэНтЮФБОаХЯЂЃЛЮЊСЫКЯРэЕФЬсИпФЃаЭЕФЩюЖШЃЌШУЛњЦїЩюШыРэНтЮФБОаХЯЂЃЌетРяТлЮФжаЪЙгУСЫвЛИіКмЧЩУюЕФЗНЗЈЃЌвЛАуРДЫЕЃЌгябдађСажаШБЩйФГМИИізжЛљБОВЛЛсЖдЮвУЧРэНтЕФДѓвтВњЩњгАЯьЃЌР§ШчгЂгяЕФЭъаЮЬюПеЃЛЮЊСЫШУФЃаЭПЩвдЯёЮвУЧвЛбљЩюШыЕФРэНтгябдађСаЃЌЮвУЧПЩвдЫцЛњЕФЖдвЛаЉДЪгяНјааmaskЃЌШУгябдФЃаЭдкбЕСЗЕФЪБКђзідЄВтШЮЮёНјЖјМгЧПЖдгябдЕФРэНтЃЛ
MLMЪЧжИдкбЕСЗЕФЪБКђЫцМДДгЪфШыгяСЯЩЯmaskЕєвЛаЉЕЅДЪЃЌШЛКѓЭЈЙ§ЕФЩЯЯТЮФдЄВтИУЕЅДЪЃЌИУШЮЮёЗЧГЃЯёЮвУЧдкжабЇЪБЦкОГЃзіЕФЭъаЮЬюПеЁЃе§ШчДЋЭГЕФгябдФЃаЭЫуЗЈКЭRNNЦЅХфФЧбљЃЌMLMЕФетИіаджЪКЭTransformerЕФНсЙЙЪЧЗЧГЃЦЅХфЕФЁЃдкBERTЕФЪЕбщжаЃЌ15%ЕФWordPiece TokenЛсБЛЫцЛњMaskЕєЁЃдкбЕСЗФЃаЭЪБЃЌвЛИіОфзгЛсБЛЖрДЮЮЙЕНФЃаЭжагУгкВЮЪ§бЇЯАЃЌЕЋЪЧGoogleВЂУЛгадкУПДЮЖМmaskЕєетаЉЕЅДЪЃЌЖјЪЧдкШЗЖЈвЊMaskЕєЕФЕЅДЪжЎКѓЃЌзівдЯТДІРэЁЃ
- 80%ЕФЪБКђЛсжБНгЬцЛЛЮЊ[Mask]ЃЌНЋОфзг ЁАmy dog is cuteЁБ зЊЛЛЮЊОфзг ЁАmy dog is [Mask]ЁБЁЃ
- 10%ЕФЪБКђНЋЦфЬцЛЛЮЊЦфЫќШЮвтЕЅДЪЃЌНЋЕЅДЪ ЁАcuteЁБ ЬцЛЛГЩСэвЛИіЫцЛњДЪЃЌР§Шч ЁАappleЁБЁЃНЋОфзг ЁАmy dog is cuteЁБ зЊЛЛЮЊОфзг ЁАmy dog is appleЁБЁЃ
- 10%ЕФЪБКђЛсБЃСєдЪМTokenЃЌР§ШчБЃГжОфзгЮЊ ЁАmy dog is cuteЁБ ВЛБфЁЃ
етУДзіЕФдвђЪЧШчЙћОфзгжаЕФФГИіToken 100%ЖМЛсБЛmaskЕєЃЌФЧУДдкfine-tuningЕФЪБКђФЃаЭОЭЛсгавЛаЉУЛгаМћЙ§ЕФЕЅДЪЁЃМгШыЫцЛњTokenЕФдвђЪЧвђЮЊTransformerвЊБЃГжЖдУПИіЪфШыtokenЕФЗжВМЪНБэеїЃЌЗёдђФЃаЭОЭЛсМЧзЁетИі[mask]ЪЧtoken ЁЏcuteЁЎЁЃжСгкЕЅДЪДјРДЕФИКУцгАЯьЃЌвђЮЊвЛИіЕЅДЪБЛЫцЛњЬцЛЛЕєЕФИХТЪжЛга15%*10% =1.5%ЃЌетИіИКУцгАЯьЦфЪЕЪЧПЩвдКіТдВЛМЦЕФЁЃ СэЭтЮФеТжИГіУПДЮжЛдЄВт15%ЕФЕЅДЪЃЌвђДЫФЃаЭЪеСВЕФБШНЯТ§ЁЃ
гХЕуЃК
- БЛЫцЛњбЁдё15%ЕФДЪЕБжавд10%ЕФИХТЪгУШЮвтДЪЬцЛЛШЅдЄВте§ШЗЕФДЪЃЌЯрЕБгкЮФБООРДэШЮЮёЃЌЮЊBERTФЃаЭИГгшСЫвЛЖЈЕФЮФБООРДэФмСІЃЛ
- БЛЫцЛњбЁдё15%ЕФДЪЕБжавд10%ЕФИХТЪБЃГжВЛБфЃЌЛКНтСЫfinetuneЪБКђгыдЄбЕСЗЪБКђЪфШыВЛЦЅХфЕФЮЪЬтЃЈдЄбЕСЗЪБКђЪфШыОфзгЕБжагаmaskЃЌЖјfinetuneЪБКђЪфШыЪЧЭъећЮоШБЕФОфзгЃЌМДЮЊЪфШыВЛЦЅХфЮЪЬтЃЉЁЃ
ШБЕуЃК - еыЖдгаСНИіМАСНИівдЩЯСЌајзжзщГЩЕФДЪЃЌЫцЛњmaskзжИюСбСЫСЌајзжжЎМфЕФЯрЙиадЃЌЪЙФЃаЭВЛЬЋШнвзбЇЯАЕНДЪЕФгявхаХЯЂЁЃжївЊеыЖдетвЛЖЬАхЃЌвђДЫgoogleДЫКѓЗЂБэСЫBERT-WWMЃЌЙњФкЕФЙўЙЄДѓСЊКЯбЖЗЩЗЂБэСЫжаЮФАцЕФBERT-WWMЁЃ
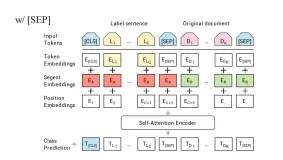
Embedding
BERT ФЃаЭНЋ Token EmbeddingsЃЌSegment EmbeddingsЃЌPosition Embeddings РћгУЧѓКЭЕФЗНЪНЕУЕНвЛИі Embedding зїЮЊФЃаЭЕФЪфШыЃЌШчЭМЫљЪОЃК

етРяКЭTransformerВЛЭЌЕФЪЧЃЌетРяЛЙЖрСЫвЛИіSegment EmbeddingЃЛToken EmbeddingКЭSegment EmbeddingЕФБрТыЗНЪНШчЭМЫљЪОЃК

ЖјЖдгкPosition EmbeddingЃЌВЩгУЕФЪЧжБНгДг[0,1,2,...,sequence_length]ШЛКѓдйРДвЛВуembeddingВуЕФЗНЪНЃЌаЇЙћКЭШ§НЧКЏЪ§ВюВЛЖрЃЛДѓМвПЩвдНјааЪЕЯжВтЪдЃЌЪдвЛЪдЕНЕзФФИіКУЃЛ
Segment EmbeddingsЃКpaddingВПЗжгУЕквЛВПЗжЕФВЙЦыЃЛМД0000001111000000
2.3 BERTМмЙЙВу
етвЛВуЕФНВНтПЩвдПДвЛЯТЯТУцетЦЊЮФеТЃЌНщЩмЕФКмЯъЯИЃЛ
[transformer]ТлЮФЪЕЯжЃКAttention Is All You Need-CSDNВЉПЭ
зЂвтСІЛњжЦЪЧдѕУДЙЄзїЕФЃК

ЭМжагаЫФИіЖЋЮїЃЌQueryЃЌKeyЃЌValueЃЌAttentionЃЌЭМжаАбKeyКЭValueЗХдкСЫвЛЦ№ЪЧвђЮЊЦфВњЩњЕФoutputЪЧгыKeyЃЌValueЕФЮЌЖШЪЧЮоЙиЕФЃЌжЛгыQueryЕФЮЌЖШгаЙиЃЛЮФжаАбKeyЃЌValueГЦзїЮЊContext sequenceЃЌQueryЛЙЪЧГЦзїЮЊQuery sequenceЃЛЮЊЪВУДвЊетУДзіЃППЩвдПДФЃаЭжагвЩЯЗНЕФMulti-Head AttentionКЭзѓЯТНЧЕФMulti-Head AttentionЕФЧјБ№НјааЗжЮіЃЛ
QueryЃЌKeyЃЌValueетШ§ИіЖЋЮїПЩвдгУpythonжаЕФзжЕфРДНтЪЭЃЌKeyЃЌValueБэЪОзжЕфжаЕФМќжЕЖдЃЌЖјQueryБэЪОЮвУЧашвЊВщбЏЕФМќЃЌQueryгыKeyЃЌValueЦЅХфЦфЕУЕНЕФНсЙћОЭЪЧЮвУЧашвЊЕФаХЯЂЃЛЕЋЪЧдкетРяВЂВЛвЊЧѓQueryгыKeyбЯИёЦЅХфЃЌжЛашвЊФЃК§ЦЅХфОЭПЩвдЃЛQueryЖдУПвЛИіKeyНјаавЛДЮФЃК§ЕФЦЅХфЃЌВЂИјГіЦЅХфГЬЖШЃЌдНЪЪХфШЈжиОЭдНДѓЃЌШЛКѓИљОнШЈжидйгыУПвЛИіValueНјаазщКЯЃЌЕУЕНзюКѓЕФНсЙћЃЛЦфЦЅХфГЬЖШЕФШЈжиОЭДњБэСЫзЂвтСІЛњжЦЕФШЈжиЃЛ
ЖрЭЗзЂвтСІЛњжЦОЭЪЧАбQueryЃЌKeyЃЌValueЖрИіЮЌЖШЕФЯђСПЗжЮЊМИИіЩйЪ§ЮЌЖШЕФЯђСПзщКЯЃЌдйдкQuery_iЃЌKey_iЃЌValue_iЩЯНјааВйзїЃЌзюКѓАбНсЙћКЯВЂЃЛ
ЖјTransformerЕФencoderжажЛЪЙгУСЫthe global self attention layerКЭЧАРЁЩёОЭјТчЃЛетРяЖдЦфзівЛИіМђЕЅЕФНщЩмЃЛ
the global self attention layerЃКФЃаЭзѓЯТНЧ(БрТыЦї)ЕФMulti-Head AttentionЃЌетвЛВуИКд№ДІРэЩЯЯТЮФађСаЃЌВЂбизХЫћЕФГЄЖШШЅДЋВЅаХЯЂМДQueryгыQueryжЎМфЕФаХЯЂЃЛ

QueryгыQueryжЎМфЕФаХЯЂДЋВЅгаКмЖржжЗНЪНЃЌР§ШчдкTransformerУЛГіРДжЎМфЮвУЧЦеБщВЩгУBidirectional RNNs КЭ CNNsЕФЗНЪНРДДІРэЃЛ
ЕЋЪЧЮЊЪВУДетРяВЛЪЙгУRNNКЭCNNЕФЗНЗЈФиЃП

RNNКЭCNNЕФЯожЦЃК
- RNN дЪаэаХЯЂбизХађСавЛТЗСїЖЏЃЌЕЋЪЧЫќвЊОЙ§аэЖрДІРэВНжшВХФмЕНДяФЧРя(ЯожЦЬнЖШСїЖЏ)ЁЃетаЉ RNN ВНжшБиаыАДЫГађдЫааЃЌвђДЫ RNN ВЛЬЋФмЙЛРћгУЯжДњВЂааЩшБИЕФгХЪЦЁЃ
- дк CNN жаЃЌУПИіЮЛжУЖМПЩвдВЂааДІРэЃЌЕЋЫќжЛЬсЙЉгаЯоЕФНгЪеГЁЁЃНгЪеГЁжЛЫцзХ CNN ВуЪ§ЕФдіМгЖјЯпаддіГЄЃЌашвЊЕўМгаэЖрОэЛ§ВуРДПчађСаДЋЪфаХЯЂ(аЁВЈЭјЭЈЙ§ЪЙгУРЉеХОэЛ§РДМѕЩйетИіЮЪЬт)ЁЃ
the global self attention layerдЪаэУПИіађСадЊЫижБНгЗУЮЪУПИіЦфЫћађСадЊЫиЃЌжЛашЩйСПВйзїЃЌВЂЧвЫљгаЪфГіЖМПЩвдВЂааМЦЫуЁЃ ОЭЯёЯТЭМетбљЃК

ЫфШЛЭМЯёРрЫЦгкЯпадВуЃЌЦфБОжЪКУЯёвВЪЧЯпадВуЃЌЕЋЪЧЦфаХЯЂДЋВЅФмСІвЊБШЦеЭЈЕФЯпадВувЊЧПЃЛ
ЧАРЁЩёОЭјТчЃК
ИУЭјТчгЩСНИіЯпадВузщГЩЁЃжаМфгавЛИіreluМЄЛюКЏЪ§ЃЌЛЙгавЛИіdropoutВуЃЛетРяУцЮЌЖШБфЛЏЪЧАбd_modelЮЌЯШЬсЩ§ЕНdffЮЌЖШЃЌШЛКѓАбdffЮЌЖШНЕЕЭЕНd_modelЮЌЖШЃЛ
2.4 ЪфГіВу
аэЖрживЊЕФЯТгЮШЮЮёЃЌШчЮЪД№ЃЈQAЃЉКЭздШЛгябдЭЦРэЃЈNLIЃЉЃЌЖМЪЧЛљгкЖдСНИіОфзгжЎМфЕФЙиЯЕЕФРэНтЃЌЖјетВЂВЛЪЧгЩгябдНЈФЃжБНгВЖЛёЕФЁЃЮЊСЫбЕСЗвЛИіФмРэНтОфзгЙиЯЕЕФФЃаЭЃЌЪЙгУвЛИіbinarized next sentence prediction (NSP)ШЮЮёЖдBERTНјаадЄбЕСЗЃЛ
NSPбЕСЗЗНЪНЃКbinarizedЃЌМДСНИіБъМЧЃЌisnextКЭnotnextЃЛisnextжИЕФЪЧinputЕФЯТвЛОфsentenceЃЛnotnextжИЕФЪЧВЛЪЧinputЕФЯТвЛОфЃЛЭЈЙ§ЪфГі50%ЕФПЩФмЪЧisnextЃЌга50%ЕФПЩФмЪЧnotnextРДЖдФЃаЭНјаабЕСЗЃЌШУФЃаЭРэНтОфзгЙиЯЕЃЛ
[CLS]ЕФзїгУ
BERTдкЕквЛОфЧАЛсМгвЛИі
[CLS]БъжОЃЌзюКѓвЛВуИУЮЛЖдгІЯђСППЩвдзїЮЊећОфЛАЕФгявхБэЪОЃЌДгЖјгУгкЯТгЮЕФЗжРрШЮЮёЕШЁЃвђЮЊгыЮФБОжавбгаЕФЦфЫќДЪЯрБШЃЌетИіЮоУїЯдгявхаХЯЂЕФЗћКХЛсИќЁАЙЋЦНЁБЕиШкКЯЮФБОжаИїИіДЪЕФгявхаХЯЂЃЌДгЖјИќКУЕФБэЪОећОфЛАЕФгявхЁЃ ОпЬхРДЫЕЃЌself-attentionЪЧгУЮФБОжаЕФЦфЫќДЪРДдіЧПФПБъДЪЕФгявхБэЪОЃЌЕЋЪЧФПБъДЪБОЩэЕФгявхЛЙЪЧЛсеМжївЊВПЗжЕФЃЌвђДЫЃЌОЙ§BERTЕФ12ВуЃЈBERT-baseЮЊР§ЃЉЃЌУПДЮДЪЕФembeddingШкКЯСЫЫљгаДЪЕФаХЯЂЃЌПЩвдШЅИќКУЕФБэЪОздМКЕФгявхЁЃЖј[CLS]ЮЛБОЩэУЛгагявхЃЌОЙ§12ВуЃЌОфзгМЖБ№ЕФЯђСПЃЌЯрБШЦфЫће§ГЃДЪЃЌПЩвдИќКУЕФБэеїОфзггявхЃЌетбљЮвУЧОЭПЩвдгУЦфЪфГіРДХаЖЯСНИіОфзгжЎМфЕФЙиЯЕВЂзіЮФБОЗжРрШЮЮёЃЛ
2.5 BERTЮЂЕї
BERTЮЂЕїЪЧРћгУбЕСЗКУЕФBERTШЅЪЪХфЯТгЮШЮЮёЃЌвЛАуРДЫЕЃЌЮвУЧжЛашвЊЕїећЖЫЕНЖЫЕФВЮЪ§ЃЌдйАбЬиЖЈШЮЮёЕФЪфШыКЭЪфГіЗХШыФЃаЭжаНјаабЕСЗОЭПЩвдЃЌЮвУЧВЂВЛашвЊбЕСЗвбОбЕСЗКУЕФBERTЃЌжЛашвЊбЕСЗЕїећЕФВЮЪ§МДПЩЃЛ

Ш§ЁЂЙ§ГЬЪЕЯж
НгЯТРДЮвУЧЪЙгУTensorflowЙЙНЈвЛИіBERTФЃаЭЃЛ
3.1 ЕМАќ
етРяЪЙгУtensorflowКЭkeras_nlpСНИіАќ
import tensorflow as tf import keras_nlp
3.2 Ъ§ОнзМБИ
етРяЕФЪ§ОнРДздGLUE BenchmarkжаЕФThe Corpus of Linguistic Acceptability
dataset = tf.data.TextLineDataset( ['./data/CoLA_train.tsv'] ) def process_data(x): x = tf.strings.split(x, '\t') return x[3], x[1] dataset = dataset.map(process_data).batch(64, drop_remainder=True) vocabulary = keras_nlp.tokenizers.compute_word_piece_vocabulary( dataset.map(lambda x, y: x), vocabulary_size=4000, lowercase=True, strip_accents=True, ) tokenizer = keras_nlp.tokenizers.WordPieceTokenizer( vocabulary=vocabulary, sequence_length=None, lowercase=True, strip_accents=True, ) cls = tokenizer.vocabulary.index('[CLS]') sep = tokenizer.vocabulary.index('[SEP]') pad = tokenizer.vocabulary.index('[PAD]') segment_packer = keras_nlp.layers.MultiSegmentPacker( sequence_length=128, start_value=cls, end_value=sep, sep_value=sep, pad_value=pad, ) def process_data_(x, y): x = tokenizer(x) input_token, segment_token = segment_packer(x) padding_token = tf.cast(input_token != 0, dtype=tf.int32) x = { 'token_ids': input_token, 'segment_ids': segment_token, 'padding_mask': padding_token, } y = tf.strings.to_number(y, tf.int32) return x, y dataset = dataset.map(process_data_) s = dataset.take(1).get_single_element() # ({'token_ids': <tf.Tensor: shape=(64, 128), dtype=int32, numpy= # array([[ 1, 324, 388, ..., 0, 0, 0], # [ 1, 144, 82, ..., 0, 0, 0], # [ 1, 144, 82, ..., 0, 0, 0], # ..., # [ 1, 87, 503, ..., 0, 0, 0], # [ 1, 87, 503, ..., 0, 0, 0], # [ 1, 87, 503, ..., 0, 0, 0]])>, # 'segment_ids': <tf.Tensor: shape=(64, 128), dtype=int32, numpy= # array([[0, 0, 0, ..., 0, 0, 0], # [0, 0, 0, ..., 0, 0, 0], # [0, 0, 0, ..., 0, 0, 0], # ..., # [0, 0, 0, ..., 0, 0, 0], # [0, 0, 0, ..., 0, 0, 0], # [0, 0, 0, ..., 0, 0, 0]])>, # 'padding_mask': <tf.Tensor: shape=(64, 128), dtype=int32, numpy= # array([[1, 1, 1, ..., 0, 0, 0], # [1, 1, 1, ..., 0, 0, 0], # [1, 1, 1, ..., 0, 0, 0], # ..., # [1, 1, 1, ..., 0, 0, 0], # [1, 1, 1, ..., 0, 0, 0], # [1, 1, 1, ..., 0, 0, 0]])>}, # <tf.Tensor: shape=(64,), dtype=int32, numpy= # array([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 0, 1, # 0, 0, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 1, # 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 1, 0, 1, 1, 1, 0, 0, 0])>)
3.3 ФЃаЭНЈСЂ
гУЯТУцДњТыРДНЈСЂФЃаЭЃК
import numpy as np def positional_encoding(length, depth): depth = depth/2 positions = np.arange(length)[:, np.newaxis] # (seq, 1) depths = np.arange(depth)[np.newaxis, :]/depth # (1, depth) angle_rates = 1 / (10000**depths) # (1, depth) angle_rads = positions * angle_rates # (pos, depth) pos_encoding = np.concatenate([np.sin(angle_rads), np.cos(angle_rads)],axis=-1) return tf.cast(pos_encoding, dtype=tf.float32) class Bert(tf.keras.Model): def __init__(self, vocabulary_size, d_model, encoder_num, intermediate_dim, num_heads, dropout=0.1): super().__init__() self.token_embedding = tf.keras.layers.Embedding(vocabulary_size, d_model) self.segment_embedding = tf.keras.layers.Embedding(2, d_model) self.position_embedding = positional_encoding(128, d_model) self.encoder = [keras_nlp.layers.TransformerEncoder( intermediate_dim=intermediate_dim, num_heads=num_heads, dropout=dropout, ) for _ in range(encoder_num)] self.add = tf.keras.layers.Add() # ЗжРрШЮЮё self.dense_1 = tf.keras.layers.Dense(128, activation='relu') self.dense_2 = tf.keras.layers.Dense(1, activation='sigmoid') def call(self, x): token_embedding = self.token_embedding(x['token_ids']) segment_embedding = self.segment_embedding(x['segment_ids']) position_embedding = tf.concat([positional_encoding(128, 512)[tf.newaxis]]*64, axis=0) output = self.add([token_embedding, segment_embedding, position_embedding]) for item in self.encoder: output = item(output) # дЄВтађСа # output = self.dense(output) # ЗжРрШЮЮё output = self.dense_1(output[:,0,:]) output = self.dense_2(output) return output
3.4 ФЃаЭбЕСЗ
ФЃаЭХфжУКЭбЕСЗДњТыШчЯТЃК
bert = Bert(tokenizer.vocabulary_size(), 512, 8, 1024, 8) bert(s[0]) bert.summary() bert.compile( loss=tf.keras.losses.BinaryCrossentropy(), optimizer='adam', metrics=[tf.keras.metrics.BinaryAccuracy()] ) bert.fit(dataset, epochs=10) # ВЛжЊЕРГіЪВУДЮЪЬтЃЌaccuracyПЈзЁВЛЖЏСЫ

ЫФЁЂећЬхзмНс
ЛљгкTransformerФЃаЭЕФBERTЃЌНЈСЂЦ№РДКмМђЕЅЃЛетРяДњТыЫЦКѕгаЮЪЬтЃЌашвЊНтД№ЃЛ