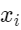[transformer]ТлЮФЪЕЯжЃКAttention Is All You NeedЃЈЩЯЃЉ/article/1504069?spm=a2c6h.13148508.setting.44.36834f0eMJOehx
2.4 зЂвтСІЛњжЦ
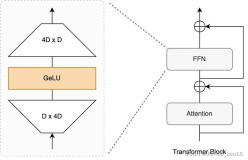
ДгЭМжаПЩвдЗЂЯжЃЌMulti-Head AttentionКЭAdd & NormЭЌбљвЛЦ№БщВМСЫећИіФЃаЭЃЛ

зЂвтСІЛњжЦЪЧдѕУДЙЄзїЕФЃК

ЭМжагаЫФИіЖЋЮїЃЌQueryЃЌKeyЃЌValueЃЌAttentionЃЌЭМжаАбKeyКЭValueЗХдкСЫвЛЦ№ЪЧвђЮЊЦфВњЩњЕФoutputЪЧгыKeyЃЌValueЕФЮЌЖШЪЧЮоЙиЕФЃЌжЛгыQueryЕФЮЌЖШгаЙиЃЛЮФжаАбKeyЃЌValueГЦзїЮЊContext sequenceЃЌQueryЛЙЪЧГЦзїЮЊQuery sequenceЃЛЮЊЪВУДвЊетУДзіЃППЩвдПДФЃаЭжагвЩЯЗНЕФMulti-Head AttentionКЭзѓЯТНЧЕФMulti-Head AttentionЕФЧјБ№НјааЗжЮіЃЛ
QueryЃЌKeyЃЌValueетШ§ИіЖЋЮїПЩвдгУpythonжаЕФзжЕфРДНтЪЭЃЌKeyЃЌValueБэЪОзжЕфжаЕФМќжЕЖдЃЌЖјQueryБэЪОЮвУЧашвЊВщбЏЕФМќЃЌQueryгыKeyЃЌValueЦЅХфЦфЕУЕНЕФНсЙћОЭЪЧЮвУЧашвЊЕФаХЯЂЃЛЕЋЪЧдкетРяВЂВЛвЊЧѓQueryгыKeyбЯИёЦЅХфЃЌжЛашвЊФЃК§ЦЅХфОЭПЩвдЃЛQueryЖдУПвЛИіKeyНјаавЛДЮФЃК§ЕФЦЅХфЃЌВЂИјГіЦЅХфГЬЖШЃЌдНЪЪХфШЈжиОЭдНДѓЃЌШЛКѓИљОнШЈжидйгыУПвЛИіValueНјаазщКЯЃЌЕУЕНзюКѓЕФНсЙћЃЛЦфЦЅХфГЬЖШЕФШЈжиОЭДњБэСЫзЂвтСІЛњжЦЕФШЈжиЃЛ
ЖрЭЗзЂвтСІЛњжЦОЭЪЧАбQueryЃЌKeyЃЌValueЖрИіЮЌЖШЕФЯђСПЗжЮЊМИИіЩйЪ§ЮЌЖШЕФЯђСПзщКЯЃЌдйдкQuery_iЃЌKey_iЃЌValue_iЩЯНјааВйзїЃЌзюКѓАбНсЙћКЯВЂЃЛ
ФЃаЭжаMulti-Head AttentionгаШ§ИіЃЌ етШ§ИіЗжБ№ЖдгІШ§жжMulti-Head Attention LayerЃКthe cross attention layerЃЌthe global self attention layerЃЌ the causal self attention layerЃЌДгЭМжавВПЩвдЗЂЯжУПвЛВуЖМгаИїздЕФВЛЭЌЃЌЯТУцРДвЛвЛНщЩмЃЛ
the cross attention layerЃКФЃаЭгвЩЯНЧ(НтТыЦї)ЕФMulti-Head AttentionЪЧзЂвтСІЛњжЦзюжБНгЕФЪЙгУЃЌЦфНЋБрТыЦїЕФаХЯЂКЭНтТыЦїЕФаХЯЂГфЗжЕФНсКЯСЫЦ№РДЃЌЮФжаАбетвЛВуНазіthe cross attention layerЃЛЦфcontext sequenceЪЧEncoderжаЕУЕНЕФЃЛ

дкетРявЊзЂвтЕФЪЧЃЌУПвЛДЮЕФВщбЏЪЧПЩвдПДЕУЕНЫљгаЕФKeyЃЌValueЕФЃЌЕЋЪЧВщбЏгыВщбЏЯрЛЅжЎМфЪЧПДВЛЕНЕФЃЌМДЖРСЂЕФЃЛ
the global self attention layerЃКФЃаЭзѓЯТНЧ(БрТыЦї)ЕФMulti-Head AttentionЃЌетвЛВуИКд№ДІРэЩЯЯТЮФађСаЃЌВЂбизХЫћЕФГЄЖШШЅДЋВЅаХЯЂМДQueryгыQueryжЎМфЕФаХЯЂЃЛ

QueryгыQueryжЎМфЕФаХЯЂДЋВЅгаКмЖржжЗНЪНЃЌР§ШчдкTransformerУЛГіРДжЎМфЮвУЧЦеБщВЩгУBidirectional RNNs КЭ CNNsЕФЗНЪНРДДІРэЃЛ
ЕЋЪЧЮЊЪВУДетРяВЛЪЙгУRNNКЭCNNЕФЗНЗЈФиЃП

RNNКЭCNNЕФЯожЦЃК
- RNN дЪаэаХЯЂбизХађСавЛТЗСїЖЏЃЌЕЋЪЧЫќвЊОЙ§аэЖрДІРэВНжшВХФмЕНДяФЧРя(ЯожЦЬнЖШСїЖЏ)ЁЃетаЉ RNN ВНжшБиаыАДЫГађдЫааЃЌвђДЫ RNN ВЛЬЋФмЙЛРћгУЯжДњВЂааЩшБИЕФгХЪЦЁЃ
- дк CNN жаЃЌУПИіЮЛжУЖМПЩвдВЂааДІРэЃЌЕЋЫќжЛЬсЙЉгаЯоЕФНгЪеГЁЁЃНгЪеГЁжЛЫцзХ CNN ВуЪ§ЕФдіМгЖјЯпаддіГЄЃЌашвЊЕўМгаэЖрОэЛ§ВуРДПчађСаДЋЪфаХЯЂ(аЁВЈЭјЭЈЙ§ЪЙгУРЉеХОэЛ§РДМѕЩйетИіЮЪЬт)ЁЃ
the global self attention layerдЪаэУПИіађСадЊЫижБНгЗУЮЪУПИіЦфЫћађСадЊЫиЃЌжЛашЩйСПВйзїЃЌВЂЧвЫљгаЪфГіЖМПЩвдВЂааМЦЫуЁЃ ОЭЯёЯТЭМетбљЃК

ЫфШЛЭМЯёРрЫЦгкЯпадВуЃЌЦфБОжЪКУЯёвВЪЧЯпадВуЃЌЕЋЪЧЦфаХЯЂДЋВЅФмСІвЊБШЦеЭЈЕФЯпадВувЊЧПЃЛ
the causal self attention layerЃКвђЙћздзЂвтВуЃЌетвЛВугыthe global self attention layerРрЫЦЃЌЦфВЛЭЌЕФЬиЕуЪЧашвЊmaskЃЌMasked Multi-Head AttentionЃЛетРявЊзЂвтЕФЪЧTransformerЪЧвЛИіздЛиЙщФЃаЭЃЌУПДЮВњЩњвЛИіЪфГіВЂЧвАбЪфГіЕБзїЪфШыгУРДМЬајВњЩњЪфГіЃЌвђДЫетаЉФЃаЭШЗБЃУПИіађСадЊЫиЕФЪфГіНівРРЕгкЯШЧАЕФађСадЊЫиЃЌЫљвдашвЊЖдAttention weightsНјааДІРэЃЛ

ИљОнТлЮФЙЋЪН:

ПЩвдЗЂЯж Q КЭ KЪЧзіОиеѓдЫЫуЕФЃЌAttentionжаЕФЕЅИідЊЫиМЦЫуЪЧQжаЕФФГааКЭ KжаЕФФГаазіЕуЛ§дЫЫуЃЛТлЮФжаЪЧМЦЫу AttentionКѓдкЯргІбкТыЮЛжУГЫвЛИіЮоЧюаЁЃЌетРяЦфЪЕПЩвдгХЛЏвЛЯТЃЌжЛМЦЫу AttentionгааЇЕФЮЛжУЃЌПЩвдМгПьЫйЖШЃЛ
етвЛВуИљОнбЕСЗКЭЭЦРэгавЛЕуВЛЭЌЃЌШчЩЯЮФЫљЫЕЃЌдкбЕСЗЪБЃЌЮвУЧВЛашвЊУПвЛДЮаТВњЩњЕФЪфГізіЮЊЪфШыЃЌЮвУЧжБНггУецжЕ(shift)ДњЬцаТВњЩњЕФЪфГіНјаабЕСЗОЭКУЃЌетбљПЩвддкШБЪЇвЛЕуЮШЖЈадЕФЧщПіЯТЃЌМгПьбЕСЗЫйЖШЃЌВЂЕУЕНУПвЛИіЮЛжУЩЯЕФЫ№ЪЇДѓаЁЃЛ
дкЭЦРэЪБЃЌЮвУЧВЂУЛгаецжЕЃЌЮвУЧжЛФмвдУПвЛДЮаТВњЩњЕФЪфГізїЮЊЪфШыНјааМЦЫуЃЌетРягаСНжжздЛиЙщЕФДІРэЗНЪНЃЛвЛИіЪЧRNNЃЌвЛИіЪЧCNNЃКFast WavenetЃЛ
вдЯТЪЧИУВуЕФМђвЊБэЪОЃЌМДУПИіађСадЊЫиЕФЪфГіНівРРЕгкЯШЧАЕФађСадЊЫиЃЛ

2.5 ЧАРЁЩёОЭјТч
дкencoderКЭdecoderжаЃЌЖМАќКЌСЫFeed ForwardЭјТчЃЌШчЭМЫљЪОЃК

ИУЭјТчгЩСНИіЯпадВузщГЩЁЃжаМфгавЛИіreluМЄЛюКЏЪ§ЃЌЛЙгавЛИіdropoutВуЃЛетРяУцЮЌЖШБфЛЏЪЧАбd_modelЮЌЯШЬсЩ§ЕНdffЮЌЖШЃЌШЛКѓАбdffЮЌЖШНЕЕЭЕНd_modelЮЌЖШЃЛ
Ш§ЁЂЙ§ГЬЪЕЯж
3.1 АВзААќКЭЕМАќ
import tensorflow as tf import keras_nlp import matplotlib.pyplot as plt import numpy as np plt.rcParams['font.sans-serif']=['SimHei'] plt.rcParams['axes.unicode_minus']=False
3.2 Ъ§ОнзМБИ
бЕСЗЕФЙ§ГЬШчЭМЫљЪОЃК

ДгЭМжаЮвУЧПЩвдПДГіЃЌЮвУЧашвЊзМБИКУдДsequenceКЭСНИіФПБъsequenceЃЌЦфжадДsequenceЧАКѓгІИУга\
етРяашвЊЬсабЕФвЛЕуЪЧЃЌгвВрбЕСЗЙ§ГЬЪЧВЛвРРЕУПвЛВНЕФЪфГіНсЙћЕФЃКетжжЩшжУБЛГЦЮЊЁАteacher forcingЁБЃЌвђЮЊВЛЙмФЃаЭдкУПИіЪБМфВНЕФЪфГіШчКЮЃЌЫќЖМЛсЛёЕУЯТвЛИіЪБМфВНЕФецжЕзїЮЊЪфШыЁЃетЪЧбЕСЗЮФБОЩњГЩФЃаЭЕФвЛжжМђЕЅЖјгааЇЕФЗНЗЈЁЃетЪЧгааЇЕФЃЌвђЮЊВЛашвЊЫГађдЫааФЃаЭЃЌдкВЛЭЌЕФађСаЮЛжУЕФЪфГіПЩвдВЂааМЦЫуЁЃ
You might have expected the `input, output`, pairs to simply be the `Portuguese, English` sequences. Given the Portuguese sequence, the model would try to generate the English sequence. It's possible to train a model that way. You'd need to write out the inference loop and pass the model's output back to the input. It's slower (time steps can't run in parallel), and a harder task to learn (the model can't get the end of a sentence right until it gets the beginning right), but it can give a more stable model because the model has to learn to correct its own errors during training.
змНсОЭЪЧ teacher forcing ЭЈЙ§ЩсЦњФЃаЭЕФЮШЖЈадЃЌМгПьбЇЯАбЕСЗЫйЖШЃЌЯрЙиДњТыШчЯТЃК
# Ъ§ОнДІРэ def process_data(x): res = tf.strings.split(x, '\t') return res[1], res[3] # ЕМШыЪ§Он dataset = tf.data.TextLineDataset('ch-en.tsv') dataset = dataset.map(process_data) # НЈСЂжагЂЮФwordpieceДЪБэ vocab_chinese = keras_nlp.tokenizers.compute_word_piece_vocabulary( dataset.map(lambda x, y: x), vocabulary_size=20_000, lowercase=True, strip_accents=True, split_on_cjk=True, reserved_tokens=["[PAD]", "[START]", "[END]", "[MASK]", "[UNK]"], ) vocab_english = keras_nlp.tokenizers.compute_word_piece_vocabulary( dataset.map(lambda x, y: y), vocabulary_size=20_000, lowercase=True, strip_accents=True, split_on_cjk=True, reserved_tokens=["[PAD]", "[START]", "[END]", "[MASK]", "[UNK]"], ) # ЙЙНЈЗжДЪЦї chinese_tokenizer = keras_nlp.tokenizers.WordPieceTokenizer(vocabulary=vocab_chinese, oov_token="[UNK]") english_tokenizer = keras_nlp.tokenizers.WordPieceTokenizer(vocabulary=vocab_english, oov_token="[UNK]") # дйНјаавЛДЮЪ§ОнДІРэ def process_data_(ch, en, maxtoken=128): ch = chinese_tokenizer(ch)[:,:maxtoken] en = english_tokenizer(tf.strings.lower(en))[:,:maxtoken] ch = tf.concat([tf.ones(shape=(64,1), dtype='int32'), ch, tf.ones(shape=(64,1), dtype='int32')*2], axis=-1).to_tensor() en = tf.concat([tf.ones(shape=(64,1), dtype='int32'), en, tf.ones(shape=(64,1), dtype='int32')*2], axis=-1) en_inputs = en[:, :-1].to_tensor() # Drop the [END] tokens en_labels = en[:, 1:].to_tensor() # Drop the [START] tokens return (ch, en_inputs), en_labels dataset = dataset.batch(64).map(process_data_) train_dataset = dataset.take(1000) val_dataset = dataset.skip(500).take(300) # Ъ§ОнзМБИЭъБЯ ВщПДЪ§Он # for (pt, en), en_labels in dataset.take(1): # break # print(pt.shape) # print(en.shape) # print(en_labels.shape) # (64, 33) # (64, 28) # (64, 28)
3.3 ДЪЧЖШыКЭЮЛжУБрТы
ДЪЧЖШыКЭЮЛжУБрТыЕФЕиЗНвЛЙВгаСНДІЃЌвЛДІЪЧInputЃЌвЛДІЪЧOutput(shifted right)ЃЛСНДІВЩгУЮЛжУБрТыЕФЗНЪНЪЧвЛбљЕФЃЛ

ЮЛжУБрТыКЏЪ§ШчЯТЃК
def positional_encoding(length, depth): depth = depth/2 positions = np.arange(length)[:, np.newaxis] # (seq, 1) depths = np.arange(depth)[np.newaxis, :]/depth # (1, depth) angle_rates = 1 / (10000**depths) # (1, depth) angle_rads = positions * angle_rates # (pos, depth) pos_encoding = np.concatenate( [np.sin(angle_rads), np.cos(angle_rads)], axis=-1) return tf.cast(pos_encoding, dtype=tf.float32)
ДЪЧЖШыКЭЮЛжУБрТыВуЕФДњТыШчЯТЃК
class PositionEmbedding(tf.keras.layers.Layer): def __init__(self, vocabulary_size, d_model): super().__init__() self.d_model = d_model self.embedding = tf.keras.layers.Embedding(vocabulary_size, d_model, mask_zero=True) self.pos_encoding = positional_encoding(length=2048, depth=d_model) def compute_mask(self, *args, **kwargs): return self.embedding.compute_mask(*args, **kwargs) def call(self, x): length = tf.shape(x)[1] x = self.embedding(x) x *= tf.math.sqrt(tf.cast(self.d_model, tf.float32)) x = x + self.pos_encoding[tf.newaxis, :length, :] return x
3.4 зЂвтСІЛњжЦ
ФЃаЭжаMulti-Head AttentionгаШ§ИіЃЌ етШ§ИіЗжБ№ЖдгІШ§жжMulti-Head Attention LayerЃКthe cross attention layerЃЌthe global self attention layerЃЌ the causal self attention layerЃЌШчЭМЫљЪОЃК

ЖЈвхвЛИіBaseAttention
class BaseAttention(tf.keras.layers.Layer): def __init__(self, **kwargs): super().__init__() self.mha = tf.keras.layers.MultiHeadAttention(**kwargs) self.layernorm = tf.keras.layers.LayerNormalization() self.add = tf.keras.layers.Add()
the cross attention layerЖЈвхШчЯТЃК
class CrossAttention(BaseAttention): def call(self, x, context): attn_output, attn_scores = self.mha( query=x, key=context, value=context, return_attention_scores=True) # Cache the attention scores for plotting later. self.last_attn_scores = attn_scores x = self.add([x, attn_output]) x = self.layernorm(x) return x
the global self attention layerЖЈвхШчЯТЃК
class GlobalSelfAttention(BaseAttention): def call(self, x): attn_output = self.mha( query=x, value=x, key=x) x = self.add([x, attn_output]) x = self.layernorm(x) return x
the causal self attention layerЖЈвхШчЯТЃК
class CausalSelfAttention(BaseAttention): def call(self, x): attn_output = self.mha( query=x, value=x, key=x, use_causal_mask = True) x = self.add([x, attn_output]) x = self.layernorm(x) return x
3.5 ЧАРЁЩёОЭјТч
ИУЭјТчгЩСНИіЯпадВузщГЩЁЃжаМфгавЛИіreluМЄЛюКЏЪ§ЃЌЛЙгавЛИіdropoutВуЃЛетРяУцЮЌЖШБфЛЏЪЧАбd_modelЮЌЯШЬсЩ§ЕНdffЮЌЖШЃЌШЛКѓАбdffЮЌЖШНЕЕЭЕНd_modelЮЌЖШЃЛ

ДњТыШчЯТЃК
class FeedForward(tf.keras.layers.Layer): def __init__(self, d_model, dff, dropout_rate=0.1): super().__init__() self.seq = tf.keras.Sequential([ tf.keras.layers.Dense(dff, activation='relu'), tf.keras.layers.Dense(d_model), tf.keras.layers.Dropout(dropout_rate) ]) self.add = tf.keras.layers.Add() self.layer_norm = tf.keras.layers.LayerNormalization() def call(self, x): x = self.add([x, self.seq(x)]) x = self.layer_norm(x) return x
3.6 БрТыЦї
ФЃаЭНсЙЙШчЯТЃЌТлЮФжаБрТыЦїЪЧгЩ6ИіБрТыВузщГЩЕФЃЛ

БрТыВуДњТыШчЯТЃК
class EncoderLayer(tf.keras.layers.Layer): def __init__(self, *, d_model, num_heads, dff, dropout=0.1): super().__init__() self.self_attention = GlobalSelfAttention( num_heads = num_heads, key_dim = d_model, dropout = dropout ) self.ffn = FeedForward(d_model, dff) def call(self, x): x = self.self_attention(x) x = self.ffn(x) return x
БрТыЦїДњТыШчЯТЃК
class Encoder(tf.keras.layers.Layer): def __init__(self, *, vocabulary_size, d_model, nums_heads, dff, num_layers=6, dropout=0.1): super().__init__() # ИјEncoderЬэМгЪєадЃЌБугкБцЪЖ self.d_model = d_model self.num_layers = num_layers self.pos_embedding = PositionEmbedding(vocabulary_size, d_model) self.encoder_layers = [EncoderLayer(d_model=d_model, num_heads=nums_heads, dff=dff, dropout=dropout) for _ in range(num_layers)] self.dropout = tf.keras.layers.Dropout(dropout) def call(self, x): x = self.pos_embedding(x) x = self.dropout(x) for encoder_layer in self.encoder_layers: x = encoder_layer(x) return x
3.7 НтТыЦї
ФЃаЭНсЙЙШчЯТЃЌТлЮФжаНтТыЦїЪЧгЩ6ИіНтТыВузщГЩЕФЃЛ

НтТыВуДњТыШчЯТЃК
class DecoderLayer(tf.keras.layers.Layer): def __init__(self, *, d_model, num_heads, dff, dropout=0.1): super().__init__() self.causal_self_attention = CausalSelfAttention(num_heads=num_heads, key_dim=d_model, dropout=dropout) self.cross_attention = CrossAttention(num_heads=num_heads, key_dim=key_dim, dropout=dropout) self.ffn = FeedForward(d_model, dff) def call(self, x, context): x = self.causal_self_attention(x) x = self.cross_attention(x, context) # етРяДцДЂзюКѓЕФзЂвтСІЗжЪ§ЮЊСЫКѓУцЕФЛЭМ self.last_attn_scores = self.cross_attention.last_attn_scores x = self.ffn(x) return x
НтТыЦїДњТыШчЯТЃК
class Decoder(tf.keras.layers.Layer): def __init__(self, *, vocabulary_size, d_model, num_heads, dff, num_layers=6, dropout=0.1): super(Decoder, self).__init__() self.d_model = d_model self.num_layers = num_layers self.pos_embedding = PositionEmbedding(vocabulary_size=vocabulary_size, d_model=d_model) self.decoder_layers = [DecoderLayer(d_model=d_model, num_heads=num_heads, dff=dff, dropout=dropout) for _ in range(num_layers)] self.dropout = tf.keras.layers.Dropout(rate=dropout) self.last_attn_scores = None def call(self, x, content): x = self.pos_embedding(x) x = self.dropout(x) for decoder_layer in self.decoder_layers: x = decoder_layer(x, content) self.last_attn_scores = self.decoder_layers[-1].last_attn_scores return x
3.8 Transformer
гаСЫБрТыЦїКЭНтТыЦїЃЌЯждкЮвУЧРДЙЙдьTransformerФЃаЭЃЌФЃаЭЕФећЬхПђМмШчЯТЃК

ашвЊЩшжУЕФГЌВЮШчЯТЃК
num_layers = 4 d_model = 128 dff = 512 num_heads = 8 dropout = 0.1
TransformerФЃаЭДњТыШчЯТЃК
class Transformer(tf.keras.Model): def __init__(self, *, num_layers, d_model, num_heads, dff, input_vocabulary_size, target_vocabulary_size, dropout=0.1): super().__init__() self.encoder = Encoder(vocabulary_size=input_vocabulary_size, d_model=d_model, num_layers=num_layers, num_heads=num_heads, dff=dff) self.decoder = Decoder(vocabulary_size=target_vocabulary_size, d_model=d_model, num_layers=num_layers, num_heads=num_heads, dff=dff) self.final_layer = tf.keras.layers.Dense(target_vocabulary_size, activation='softmax') def call(self, inputs): context, x = inputs context = self.encoder(context) x = self.decoder(x, context) logits = self.final_layer(x) # ВЛЬЋРэНт try: # Drop the keras mask, so it doesn't scale the losses/metrics. # b/250038731 del logits._keras_mask except AttributeError: pass return logits
вдЯТЪЧВЛЭЌВуЪ§ЕФTransformerКЭRNN+AttentionФЃаЭЕФПЩЪгЛЏФЃаЭЃК

ФЃаЭВЮЪ§ДѓаЁШчЯТЃК
model.summary()

ШчЙћГіЯжЃКThis model has not yet been built. Build the model first by calling build() or by calling the model on a batch of data.ЃЌЪдзХДјШыЪ§ОнbuildвЛЯТФЃаЭ
model = Transformer(num_layers=num_layers, d_model=d_model, num_heads=num_heads, dff=dff, input_vocabulary_size=chinese_tokenizer.vocabulary_size(), target_vocabulary_size=english_tokenizer.vocabulary_size(), dropout=dropout) output = model((pt, en)) print(en.shape) print(pt.shape) print(output.shape)
3.9 бЕСЗ
ИљОндЮФЕФЙЋЪНздЖЈвхвЛИібЇЯАТЪЕїЖШЦї: 
ДњТыШчЯТЃК
class CustomSchedule(tf.keras.optimizers.schedules.LearningRateSchedule): def __init__(self, d_model, warmup_steps=4000): super().__init__() self.d_model = d_model self.d_model = tf.cast(self.d_model, tf.float32) self.warmup_steps = warmup_steps def __call__(self, step): step = tf.cast(step, dtype=tf.float32) arg1 = tf.math.rsqrt(step) arg2 = step * (self.warmup_steps ** -1.5) return tf.math.rsqrt(self.d_model) * tf.math.minimum(arg1, arg2) learning_rate = CustomSchedule(d_model) optimizer = tf.keras.optimizers.Adam(learning_rate, beta_1=0.9, beta_2=0.98, epsilon=1e-9)
ЕїЖШЧњЯпШчЯТЫљЪОЃК

ЖЈвхlossКЭmetricsЃК
def masked_loss(label, pred): mask = label != 0 loss_object = tf.keras.losses.SparseCategoricalCrossentropy(reduction='none') loss = loss_object(label, pred) mask = tf.cast(mask, dtype=loss.dtype) loss *= mask loss = tf.reduce_sum(loss)/tf.reduce_sum(mask) return loss def masked_accuracy(label, pred): pred = tf.argmax(pred, axis=2) label = tf.cast(label, pred.dtype) match = label == pred mask = label != 0 match = match & mask match = tf.cast(match, dtype=tf.float32) mask = tf.cast(mask, dtype=tf.float32) return tf.reduce_sum(match)/tf.reduce_sum(mask)
ПЊЪМбЕСЗЃК
model.compile(loss=masked_loss, optimizer=optimizer, metrics=[masked_accuracy]) model.fit(train_dataset, epochs=10, validation_data=val_dataset)

3.10 ЭЦРэ
ШчЩЯЮФЫљЫЕЃЌгЩгкЭЦРэЙ§ГЬгкбЕСЗЙ§ГЬВЛвЛжТЃЌЮвУЧашвЊжиаТаДвЛИіЭЦРэЕФДњТыЃЌДњТыШчЯТЃК
MAX_TOKENS = 128 class Translator(tf.Module): def __init__(self, tokenizers, transformer): self.tokenizers = tokenizers self.transformer = transformer def __call__(self, sentence, max_length=MAX_TOKENS): # sentenceЪЧжаЮФЃЌвђДЫашвЊtokenizerВЂЧвМгЩЯ<start>:1КЭ<end>:2 assert isinstance(sentence, tf.Tensor) if len(sentence.shape) == 0: sentence = sentence[tf.newaxis] sentence = self.tokenizers(sentence) sentence = tf.concat([tf.ones(shape=[sentence.shape[0], 1], dtype='int32'), sentence, tf.ones(shape=[sentence.shape[0], 1], dtype='int32')*2], axis=-1).to_tensor() encoder_input = sentence # As the output language is English, initialize the output with the start = tf.constant(1, dtype='int64')[tf.newaxis] end = tf.constant(2, dtype='int64')[tf.newaxis] # tf.TensorArray РрЫЦгкpythonжаЕФСаБэ output_array = tf.TensorArray(dtype=tf.int64, size=0, dynamic_size=True) # дкindex=0ЕФЮЛжУаДШыstart output_array = output_array.write(0, start) for i in tf.range(max_length): output = tf.transpose(output_array.stack()) predictions = self.transformer([encoder_input, output], training=False) # Shape `(batch_size, seq_len, vocab_size)` # Дгseq_lenжаЕФзюКѓвЛИіЮЌЖШбЁдёlast token predictions = predictions[:, -1:, :] # Shape `(batch_size, 1, vocab_size)`. predicted_id = tf.argmax(predictions, axis=-1) # `predicted_id`МгШыЕНoutput_arrayжазїЮЊвЛИіаТЕФЪфШы output_array = output_array.write(i+1, predicted_id[0]) # ШчЙћЪфГіendОЭБэУїЭЃжЙ if predicted_id == end: break output = tf.transpose(output_array.stack()) # жиаТМЦЫувЛЯТзюЭтУцЕФбЛЗЃЌЕУЕНзюКѓЕФзЂвтСІЕУЗж self.transformer([encoder_input, output[:,:-1]], training=False) attention_weights = self.transformer.decoder.last_attn_scores lst = [] for item in output[0].numpy(): lst.append(english_tokenizer.vocabulary[item]) translated_text = ''.join(lst) translated_tokens = output[0] return translated_text, translated_tokens, attention_weights``` ЭЦРэВтЪдЃК ```python def print_translation(sentence, tokens, ground_truth): print(f'{"Input:":15s}: {sentence}') print(f'{"Prediction":15s}: {tokens}') print(f'{"Ground truth":15s}: {ground_truth}') translator = Translator(chinese_tokenizer, model) sentence = 'ЮвддПДЃЁ' ground_truth = "Let's try it." translated_text, translated_tokens, attention_weights = translator(tf.constant(sentence)) print_translation(sentence, translated_text, ground_truth) # Input: : ЮвддПДЃЁ # Prediction : [START] let ' s try to see this . [END] # Ground truth : Let's try it.
3.11 зЂвтСІПЩЪгЛЏ
ЖЈвхЛзЂвтСІШЈжиЕФКЏЪ§ЃК
def plot_attention_head(in_tokens, translated_tokens, attention): # ФЃаЭдкЪфГіжаВЛВњЩњ<START>ЃЌЮвУЧжБНгКіТд translated_tokens = translated_tokens[1:] ax = plt.gca() ax.matshow(attention[0]) ax.set_xticks(range(len(in_tokens))) ax.set_yticks(range(len(translated_tokens))) labels = [vocab_chinese[label] for label in in_tokens.numpy()] ax.set_xticklabels(labels, rotation=90) labels = [vocab_english[label] for label in translated_tokens.numpy()] ax.set_yticklabels(labels)
ВтЪдДњТыШчЯТЃК
sentence = 'ЮвддПДЃЁ' ground_truth = "Let's try it." translated_text, translated_tokens, attention_weights = translator(tf.constant(sentence)) in_tokens = tf.concat([tf.constant(1)[tf.newaxis], chinese_tokenizer(tf.constant(sentence)), tf.constant(2)[tf.newaxis]], axis=-1) attention = tf.squeeze(attention_weights, 0) # ЛЕк0ИіЭЗ attention[0] етРявЛЙВга8ИіЭЗ plot_attention_head(in_tokens, translated_tokens, attention[0])
Ек0ИіЭЗНсЙћШчЯТЃК

ЫФЁЂећЬхзмНс
ДњТыгаЕуГЄЃЁ