ДѓМвКУЃЌЮвЪЧ V ИчЁЃ
БОРДНёЬьЯыЭЕИіРСЃЌвђЮЊЗХМйСЫЃЌДјМвШЫШЅХРЩНЃЌКУОУУЛгадЫЖЏСЫЃЌРлЙЛЧКЃЌДђПЊЕчФдЃЌПДЕНЗлЫПЕФЮЪЬтЃЌе§КУжЎЧАбаОПЙ§етИіЮЪЬтЃЌКУАЩЃЌСщИаРДСЫЃЌОЭвдетИіЛАЬтИјажЕмУЧећРэЕузЪСЯЃЌвдБИжЎашЁЃ 
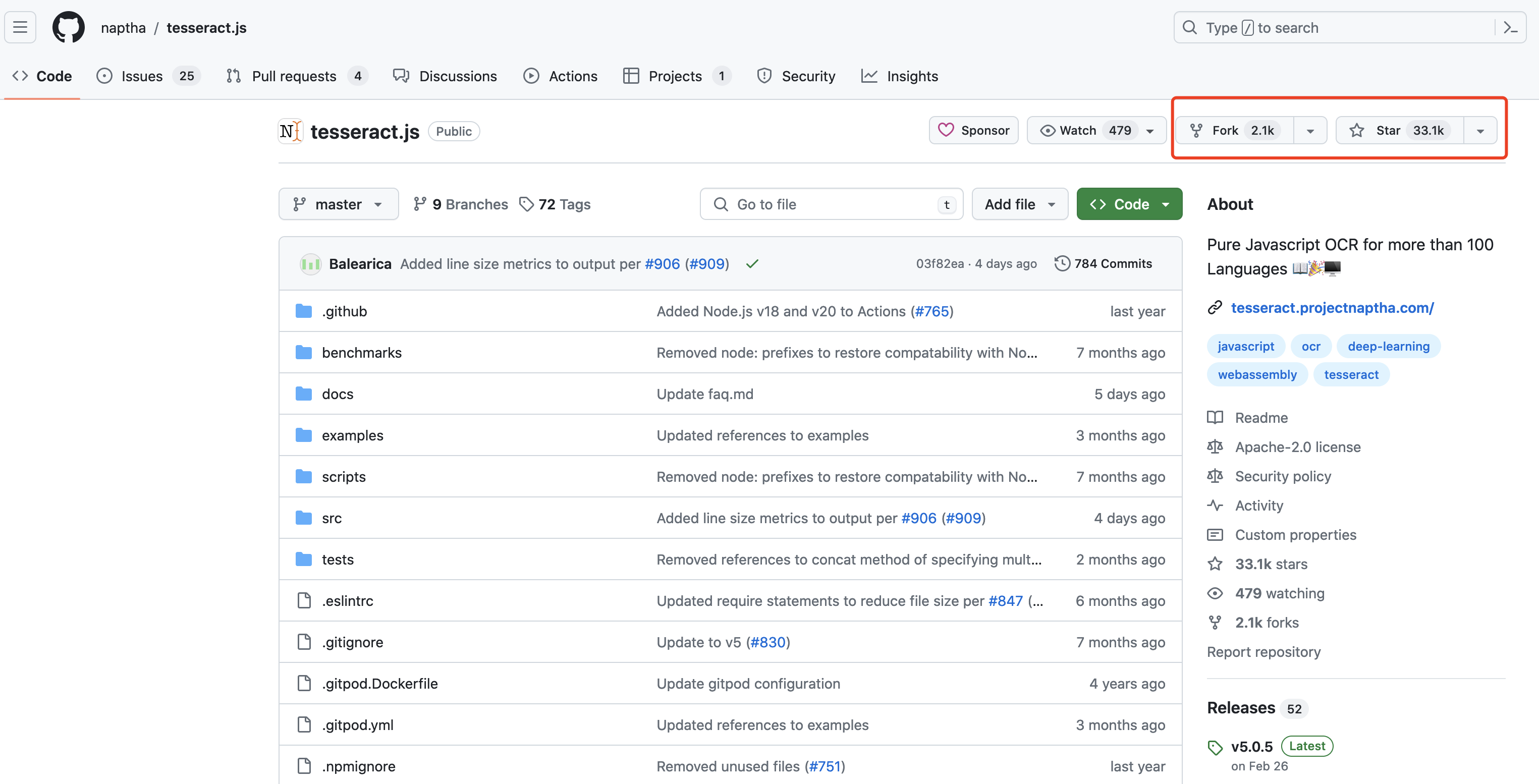
Tesseract.js ЪЧвЛИіЛљгкЭјвГЕФ OCRЃЈЙтбЇзжЗћЪЖБ№ЃЉв§ЧцЃЌПЩвдЪЖБ№ЭМЯёжаЕФЮФБОВЂНЋЦфзЊЛЛЮЊПЩЙЉМЦЫуЛњДІРэЕФЮФБОЪ§ОнЁЃдкжЎЧАЕФвЛИіЯюФП V Иче§КУгУЙ§етИіЖЋЖЋЃЌНёЬьвЛПДЃЌвбБЛ Star 33.1k СЫЃЌвВЪЧвЛИіХЃБЦЕФПЊдДЯюФППтЁЃ

гаажЕмЪЧВЛЪЧЛсвЩЛѓЃЌV ИчФуВЛЪЧИуКѓЖЫЕФУДЃПЫЫЕИуКѓЖЫЕФОЭВЛФмбаОПЧАЖЫФиЃЌВЛНіЪЧЧАЖЫЃЌВтЪдЁЂдЫЮЌЁЂЦфЫќПЊЗЂгябдЃЌжЛвЊдкетааЪБМфГЄСЫЃЌЙЄзїашвЊЖМвЊИувЛИуЃЌгябджЛЪЧЙЄОпЃЌЪЕЯжгУЛЇашЧѓВХЪЧЙиМќЃЌжЛВЛЙ§вдКѓЖЫЮЊжїЖјвбЃЌКУСЫНјШыжїЬтЁЃ
ЯШРДвЛИіМђЕЅЕФЪОР§ЃЌИаЪмвЛЯТШчКЮЪЙгУ Tesseract.js ДгЭМЦЌжаЬсШЁЮФзжЃК
<html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>OCR Demo</title> <script src="https://cdn.jsdelivr.net/npm/tesseract.js@2.3.0/dist/tesseract.min.js"></script> </head> <body> <input type="file" id="fileInput" accept="image/*"> <div id="output"></div> <script> document.getElementById('fileInput').addEventListener('change', function(event) { const file = event.target.files[0]; const reader = new FileReader(); reader.onload = function(event) { const imgData = event.target.result; Tesseract.recognize( imgData, 'eng', // ЪЖБ№гябдЃЈгЂЮФЃЉ { logger: m => console.log(m) } // ПЩбЁЕФШежОКЏЪ§ЃЌгУгкВщПДДІРэНјЖШ ).then(({ data: { text } }) => { document.getElementById('output').innerText = text; }); }; reader.readAsDataURL(file); }); </script> </body> </html>
етИіДњТыДДНЈСЫвЛИіМђЕЅЕФвГУцЃЌЦфжаАќКЌвЛИіЮФМўЪфШызжЖЮЃЌгУЛЇПЩвдбЁдёвЊЩЯДЋЕФЭМЦЌЮФМўЁЃвЛЕЉбЁдёСЫЮФМўЃЌЫќНЋБЛЖСШЁВЂДЋЕнИј Tesseract.js Нјаа OCR ДІРэЃЌШЛКѓЬсШЁЕФЮФБОНЋЯдЪОдквГУцЩЯЁЃ
Tesseract.js ЪЧвЛИіЛљгкЭјвГЕФ OCRЃЈЙтбЇзжЗћЪЖБ№ЃЉв§ЧцЃЌЪЪгУгкИїжжашвЊДгЭМЯёжаЬсШЁЮФБОЕФгІгУГЁОАЃЌЫќОпгавдЯТКЫаФЙІФмЃК
ЮФБОЪЖБ№ЃКTesseract.jsПЩвдДгЭМЯёжаЪЖБ№ГіЮФБОЃЌВЂНЋЦфзЊЛЛЮЊПЩЙЉМЦЫуЛњДІРэЕФЮФБОЪ§ОнЁЃЖргябджЇГжЃКЫќжЇГжЖржжгябдЕФЮФБОЪЖБ№ЃЌАќРЈЕЋВЛЯогкгЂгяЁЂжаЮФЁЂШегяЁЂЗЈгяЁЂЕТгяЕШЁЃОЋЖШЕїгХЃКПЩвдЭЈЙ§ЩшжУВЮЪ§РДЕїећЪЖБ№ОЋЖШКЭЫйЖШЃЌвдЪЪгІВЛЭЌашЧѓЯТЕФгІгУГЁОАЁЃЭјвГМЏГЩЃКзїЮЊвЛИіJavaScriptПтЃЌTesseract.jsПЩвджБНгдкЭјвГжаЪЙгУЃЌЮоашЖюЭтЕФЗўЮёЦїЖЫжЇГжЁЃвьВНДІРэЃКTesseract.jsЪЙгУвьВНДІРэЃЌПЩвддкКѓЬЈНјааЭМЯёДІРэКЭЮФБОЪЖБ№ЃЌВЛЛсзшШћгУЛЇНчУцЁЃGPU МгЫйЃКвЛаЉАцБОЕФTesseract.jsжЇГжРћгУ GPU НјааМгЫйЃЌвдЬсИпДІРэЫйЖШЁЃздЖЈвхЪЖБ№ФЃаЭЃКПЩвдИљОнашвЊЪЙгУбЕСЗЪ§ОнздЖЈвхЪЖБ№ФЃаЭЃЌвдЬсИпЬиЖЈЮФБОРраЭЛђЬиЖЈгябдЕФЪЖБ№зМШЗТЪЁЃШежОЪфГіЃКЬсЙЉШежОЪфГіЙІФмЃЌПЩвдгУгкИњзйДІРэНјЖШЁЂЪЖБ№НсЙћЕШаХЯЂЁЃ
1ЁЂЮФБОЪЖБ№
вдЯТЪЧвЛИіМђЕЅЕФДњТыЪОР§ЃЌбнЪОШчКЮЪЙгУ Tesseract.js НјааЮФБОЪЖБ№ЃК
<html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Text Recognition Demo</title> <script src="https://cdn.jsdelivr.net/npm/tesseract.js@2.3.0/dist/tesseract.min.js"></script> </head> <body> <input type="file" id="fileInput" accept="image/*"> <div id="output"></div> <script> document.getElementById('fileInput').addEventListener('change', function(event) { const file = event.target.files[0]; const reader = new FileReader(); reader.onload = function(event) { const imgData = event.target.result; Tesseract.recognize( imgData, 'eng', // ЪЖБ№гябдЃЈгЂЮФЃЉ { logger: m => console.log(m) } // ПЩбЁЕФШежОКЏЪ§ЃЌгУгкВщПДДІРэНјЖШ ).then(({ data: { text } }) => { document.getElementById('output').innerText = text; }); }; reader.readAsDataURL(file); }); </script> </body> </html>
етЖЮДњТыДДНЈСЫвЛИіМђЕЅЕФвГУцЃЌЦфжаАќКЌвЛИіЮФМўЪфШызжЖЮЃЌгУЛЇПЩвдбЁдёвЊЩЯДЋЕФЭМЦЌЮФМўЁЃвЛЕЉбЁдёСЫЮФМўЃЌЫќНЋБЛЖСШЁВЂДЋЕнИј Tesseract.js Нјаа OCR ДІРэЃЌШЛКѓЬсШЁЕФЮФБОНЋЯдЪОдквГУцЩЯЁЃ
ТпМгыдРэНтЪЭШчЯТЃК
- гУЛЇбЁдёЭМЦЌЮФМўВЂЩЯДЋжСЭјвГЁЃетвЛВНЭЈЙ§HTMLЕФ
<input type="file">дЊЫиЪЕЯжЁЃ JavaScriptМрЬ§ЮФМўЪфШызжЖЮЕФБфЛЏЪТМўЁЃвЛЕЉгУЛЇбЁдёСЫЮФМўЃЌЛсДЅЗЂЪТМўДІРэКЏЪ§ЁЃ- дкЪТМўДІРэКЏЪ§жаЃЌЪЙгУ
FileReaderЖдЯѓЖСШЁгУЛЇбЁдёЕФЭМЦЌЮФМўЁЃетРяЪЙгУreadAsDataURL()ЗНЗЈНЋЭМЦЌЮФМўЖСШЁЮЊData URLИёЪНЁЃ - вЛЕЉЭМЦЌЮФМўБЛЖСШЁЮЊData URLЃЌОЭПЩвдНЋЦфзїЮЊВЮЪ§ДЋЕнИјTesseract.jsЕФrecognize()ЗНЗЈЁЃдкетИіР§згжаЃЌЮвУЧжИЖЈСЫвЊЪЖБ№ЕФгябдЮЊгЂЮФЃЈ'eng'ЃЉЁЃ
recognize()ЗНЗЈЗЕЛивЛИіPromiseЖдЯѓЃЌЕБЮФБОЪЖБ№ЭъГЩЪБЃЌPromiseЛсБЛНтЮіЃЌВЂЗЕЛиЪЖБ№НсЙћЁЃ- дк
PromiseЕФНтЮіЛиЕїКЏЪ§жаЃЌЮвУЧНЋЪЖБ№НсЙћжаЕФЮФБОЬсШЁГіРДЃЌВЂНЋЦфЯдЪОдквГУцЩЯЁЃдкетИіР§згжаЃЌЮвУЧНЋЮФБОФкШнВхШыЕНвГУцжаОпгаIDЮЊoutputЕФдЊЫижаЁЃ
етИіЪОР§ДњТыбнЪОСЫШчКЮЭЈЙ§Tesseract.jsЪЕЯжЮФБОЪЖБ№ЙІФмЃЌВЂНЋЪЖБ№НсЙћЯдЪОдкЭјвГЩЯЁЃ
2ЁЂЖргябджЇГж
вдЯТЪЧвЛИіМђЕЅЕФДњТыЪОР§ЃЌбнЪОШчКЮдк Tesseract.js жаЪЕЯжЖргябдЮФБОЪЖБ№ЃК
<html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Multilingual Text Recognition Demo</title> <script src="https://cdn.jsdelivr.net/npm/tesseract.js@2.3.0/dist/tesseract.min.js"></script> </head> <body> <input type="file" id="fileInput" accept="image/*"> <select id="languageSelect"> <option value="eng">English</option> <option value="fra">French</option> <option value="deu">German</option> <!-- Add more options for other languages --> </select> <div id="output"></div> <script> document.getElementById('fileInput').addEventListener('change', function(event) { const file = event.target.files[0]; const reader = new FileReader(); reader.onload = function(event) { const imgData = event.target.result; const selectedLanguage = document.getElementById('languageSelect').value; Tesseract.recognize( imgData, selectedLanguage, // ИљОнгУЛЇбЁдёЕФгябдНјааЮФБОЪЖБ№ { logger: m => console.log(m) } // ПЩбЁЕФШежОКЏЪ§ЃЌгУгкВщПДДІРэНјЖШ ).then(({ data: { text } }) => { document.getElementById('output').innerText = text; }); }; reader.readAsDataURL(file); }); </script> </body> </html>
ТпМгыдРэНтЪЭШчЯТЃК
- гУЛЇбЁдёвЊЩЯДЋЕФЭМЦЌЮФМўЃЌВЂбЁдёвЊЪЖБ№ЕФгябдЁЃетИіЪОР§ЪЙгУСЫвЛИі
<select>дЊЫиЃЌдЪаэгУЛЇДгдЄЖЈвхЕФгябдСаБэжабЁдёвЊЪЖБ№ЕФгябдЁЃ JavaScriptМрЬ§ЮФМўЪфШызжЖЮКЭгябдбЁдёзжЖЮЕФБфЛЏЪТМўЁЃвЛЕЉгУЛЇбЁдёСЫЮФМўВЂбЁдёСЫгябдЃЌЛсДЅЗЂЪТМўДІРэКЏЪ§ЁЃ- дкЪТМўДІРэКЏЪ§жаЃЌЪЙгУ
FileReaderЖдЯѓЖСШЁгУЛЇбЁдёЕФЭМЦЌЮФМўЃЌВЂНЋЦфзЊЛЛЮЊ Data URL ИёЪНЁЃ - ЛёШЁгУЛЇбЁдёЕФгябдЃЌетРяЭЈЙ§
<select>дЊЫиЕФжЕРДШЗЖЈгУЛЇбЁдёЕФгябдЁЃ - НЋЭМЦЌЪ§ОнКЭбЁдёЕФгябдзїЮЊВЮЪ§ДЋЕнИј
Tesseract.jsЕФrecognize()ЗНЗЈЁЃ recognize()ЗНЗЈЗЕЛивЛИіPromiseЖдЯѓЃЌЕБЮФБОЪЖБ№ЭъГЩЪБЃЌPromiseЛсБЛНтЮіЃЌВЂЗЕЛиЪЖБ№НсЙћЁЃ- дк
PromiseЕФНтЮіЛиЕїКЏЪ§жаЃЌНЋЪЖБ№НсЙћжаЕФЮФБОЬсШЁГіРДЃЌВЂНЋЦфЯдЪОдквГУцЩЯЁЃ
ЭЈЙ§етИіЪОР§ЃЌгУЛЇПЩвдбЁдёВЛЭЌЕФгябдНјааЮФБОЪЖБ№ЃЌВЂЧвПЩвдИљОнашвЊРЉеЙИќЖргябдбЁЯюЁЃ
3ЁЂОЋЖШЕїгХ
дк Tesseract.js жаЕїећЪЖБ№ОЋЖШЕФжївЊЗНЪНЪЧЭЈЙ§ХфжУВЮЪ§РДЪЕЯжЁЃвдЯТЪЧвЛИіЪОР§ДњТыЃЌбнЪОШчКЮЭЈЙ§ЩшжУВЛЭЌЕФХфжУВЮЪ§РДЕїећЪЖБ№ОЋЖШЃК
<html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Text Recognition Accuracy Demo</title> <script src="https://cdn.jsdelivr.net/npm/tesseract.js@2.3.0/dist/tesseract.min.js"></script> </head> <body> <input type="file" id="fileInput" accept="image/*"> <button id="highAccuracyButton">High Accuracy</button> <button id="fastRecognitionButton">Fast Recognition</button> <div id="output"></div> <script> document.getElementById('fileInput').addEventListener('change', function(event) { const file = event.target.files[0]; const reader = new FileReader(); reader.onload = function(event) { const imgData = event.target.result; recognizeText(imgData); }; reader.readAsDataURL(file); }); document.getElementById('highAccuracyButton').addEventListener('click', function() { Tesseract.setParameters({ tessedit_ocr_engine_mode: 'OEM_TESSERACT_ONLY', // ЪЙгУ Tesseract в§Чц tessedit_pageseg_mode: 'PSM_SINGLE_BLOCK', // ЕЅИіЮФБОПщФЃЪН tessedit_char_whitelist: 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789', // ЪЖБ№ЕФзжЗћАзУћЕЅ tessedit_zero_rejection: true // дЪаэСужУаХЖШЕФЪЖБ№НсЙћ }); // жиаТЪЖБ№ЮФБО recognizeText(); }); document.getElementById('fastRecognitionButton').addEventListener('click', function() { Tesseract.setParameters({ tessedit_ocr_engine_mode: 'OEM_LSTM_ONLY', // ЪЙгУ LSTM в§Чц tessedit_pageseg_mode: 'PSM_AUTO' // здЖЏЗжвГФЃЪН }); // жиаТЪЖБ№ЮФБО recognizeText(); }); function recognizeText(imgData) { Tesseract.recognize( imgData, 'eng', // ЪЖБ№гябдЃЈгЂЮФЃЉ { logger: m => console.log(m) } // ПЩбЁЕФШежОКЏЪ§ЃЌгУгкВщПДДІРэНјЖШ ).then(({ data: { text } }) => { document.getElementById('output').innerText = text; }); } </script> </body> </html>
ТпМгыдРэНтЪЭШчЯТЃК
- гУЛЇбЁдёвЊЩЯДЋЕФЭМЦЌЮФМўЁЃвЛЕЉбЁдёСЫЮФМўЃЌЛсДЅЗЂЮФМўЪфШызжЖЮЕФБфЛЏЪТМўЃЌВЂЖСШЁЭМЦЌЮФМўЕФЪ§ОнЁЃ
- ЭЈЙ§ЕуЛїЁАHigh AccuracyЁБЛђЁАFast RecognitionЁБАДХЅЃЌгУЛЇПЩвдбЁдёВЛЭЌЕФЪЖБ№ОЋЖШЁЃИљОнАДХЅЕФЕуЛїЪТМўЃЌЛсЕїгУВЛЭЌЕФХфжУВЮЪ§ЁЃ
- дкЕуЛїЁАHigh AccuracyЁБАДХЅЪБЃЌЩшжУСЫвЛаЉВЮЪ§РДЬсИпЪЖБ№ЕФОЋЖШЁЃР§ШчЃЌЪЙгУ Tesseract в§ЧцЁЂЕЅИіЮФБОПщФЃЪНЁЂздЖЈвхзжЗћАзУћЕЅЕШЁЃ
- дкЕуЛїЁАFast RecognitionЁБАДХЅЪБЃЌЩшжУСЫвЛаЉВЮЪ§РДМгПьЪЖБ№ЫйЖШЁЃР§ШчЃЌЪЙгУ LSTM в§ЧцЁЂздЖЏЗжвГФЃЪНЕШЁЃ
- ЕїгУ
recognizeText()КЏЪ§РДНјааЮФБОЪЖБ№ЃЌИУКЏЪ§ЛсИљОнЫљЩшжУЕФВЮЪ§РДЪЖБ№ЭМЦЌжаЕФЮФБОЁЃ
ЭЈЙ§етИіЪОР§ЃЌгУЛЇПЩвдИљОнашЧѓбЁдёВЛЭЌЕФЪЖБ№ОЋЖШЃЌДгЖјЪЕЯжИќСщЛюЕФЮФБОЪЖБ№ЁЃ
4ЁЂЭјвГМЏГЩ
вдЯТЪЧвЛИіМђЕЅЕФДњТыЪОР§ЃЌбнЪОШчКЮдкЭјвГжаМЏГЩ Tesseract.js НјааЮФБОЪЖБ№ЃК
<html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Web Integration with Tesseract.js</title> <script src="https://cdn.jsdelivr.net/npm/tesseract.js@2.3.0/dist/tesseract.min.js"></script> </head> <body> <input type="file" id="fileInput" accept="image/*"> <div id="output"></div> <script> document.getElementById('fileInput').addEventListener('change', function(event) { const file = event.target.files[0]; const reader = new FileReader(); reader.onload = function(event) { const imgData = event.target.result; Tesseract.recognize( imgData, 'eng', // ЪЖБ№гябдЃЈгЂЮФЃЉ { logger: m => console.log(m) } // ПЩбЁЕФШежОКЏЪ§ЃЌгУгкВщПДДІРэНјЖШ ).then(({ data: { text } }) => { document.getElementById('output').innerText = text; }); }; reader.readAsDataURL(file); }); </script> </body> </html>
ТпМгыдРэНтЪЭШчЯТЃК
- гУЛЇдкЭјвГжабЁдёвЊЩЯДЋЕФЭМЦЌЮФМўЁЃетвЛВНЭЈЙ§HTMLЕФ
<input type="file">дЊЫиЪЕЯжЁЃ JavaScriptМрЬ§ЮФМўЪфШызжЖЮЕФБфЛЏЪТМўЁЃвЛЕЉгУЛЇбЁдёСЫЮФМўЃЌЛсДЅЗЂЪТМўДІРэКЏЪ§ЁЃ- дкЪТМўДІРэКЏЪ§жаЃЌЪЙгУ
FileReaderЖдЯѓЖСШЁгУЛЇбЁдёЕФЭМЦЌЮФМўЃЌВЂНЋЦфзЊЛЛЮЊ Data URL ИёЪНЁЃ - НЋЭМЦЌЪ§ОнКЭбЁдёЕФгябдзїЮЊВЮЪ§ДЋЕнИј
Tesseract.jsЕФrecognize()ЗНЗЈЁЃдкетИіР§згжаЃЌЮвУЧжИЖЈСЫвЊЪЖБ№ЕФгябдЮЊгЂЮФЃЈ'eng'ЃЉЁЃ recognize()ЗНЗЈЗЕЛивЛИіPromiseЖдЯѓЃЌЕБЮФБОЪЖБ№ЭъГЩЪБЃЌPromiseЛсБЛНтЮіЃЌВЂЗЕЛиЪЖБ№НсЙћЁЃ- дк
PromiseЕФНтЮіЛиЕїКЏЪ§жаЃЌЮвУЧНЋЪЖБ№НсЙћжаЕФЮФБОЬсШЁГіРДЃЌВЂНЋЦфЯдЪОдквГУцЩЯЁЃдкетИіР§згжаЃЌЮвУЧНЋЮФБОФкШнВхШыЕНвГУцжаОпгаIDЮЊoutputЕФдЊЫижаЁЃ
ЭЈЙ§етИіЪОР§ЃЌгУЛЇПЩвддкЭјвГжажБНгЪЙгУTesseract.jsНјааЮФБОЪЖБ№ЃЌЮоашЖюЭтЕФЗўЮёЦїЖЫжЇГжЁЃ
5ЁЂвьВНДІРэ
вдЯТЪЧвЛИіМђЕЅЕФДњТыЪОР§ЃЌбнЪОШчКЮЪЙгУ Tesseract.js НјаавьВНДІРэЃЌвдБудкКѓЬЈНјааЭМЯёДІРэКЭЮФБОЪЖБ№ЃЌЖјВЛЛсзшШћгУЛЇНчУцЃК
<html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Asynchronous Text Recognition Demo</title> <script src="https://cdn.jsdelivr.net/npm/tesseract.js@2.3.0/dist/tesseract.min.js"></script> </head> <body> <input type="file" id="fileInput" accept="image/*"> <div id="output">Processing...</div> <script> document.getElementById('fileInput').addEventListener('change', function(event) { const file = event.target.files[0]; const reader = new FileReader(); reader.onload = function(event) { const imgData = event.target.result; // дквьВНШЮЮёжажДааЮФБОЪЖБ№ recognizeText(imgData); }; reader.readAsDataURL(file); }); function recognizeText(imgData) { // ЪЙгУ Promise РДАќзАвьВНВйзї new Promise((resolve, reject) => { // дквьВНШЮЮёжажДааЮФБОЪЖБ№ Tesseract.recognize( imgData, 'eng', // ЪЖБ№гябдЃЈгЂЮФЃЉ { logger: m => console.log(m) } // ПЩбЁЕФШежОКЏЪ§ЃЌгУгкВщПДДІРэНјЖШ ).then(({ data: { text } }) => { // НЋЪЖБ№НсЙћДЋЕнИј Promise ЕФНтЮіКЏЪ§ resolve(text); }).catch(error => { // ШчЙћЗЂЩњДэЮѓЃЌНЋДэЮѓаХЯЂДЋЕнИј Promise ЕФОмОјКЏЪ§ reject(error); }); }).then(text => { // вьВНШЮЮёЭъГЩКѓЃЌИќаТвГУцЩЯЕФЮФБОФкШн document.getElementById('output').innerText = text; }).catch(error => { // ДІРэДэЮѓЧщПіЃЌР§ШчЪфГіДэЮѓаХЯЂЕНПижЦЬЈ console.error('Error:', error); }); } </script> </body> </html>
ТпМгыдРэНтЪЭШчЯТЃК
- гУЛЇдкЭјвГжабЁдёвЊЩЯДЋЕФЭМЦЌЮФМўЁЃетвЛВНЭЈЙ§HTMLЕФ
<input type="file">дЊЫиЪЕЯжЁЃ JavaScriptМрЬ§ЮФМўЪфШызжЖЮЕФБфЛЏЪТМўЁЃвЛЕЉгУЛЇбЁдёСЫЮФМўЃЌЛсДЅЗЂЪТМўДІРэКЏЪ§ЁЃ- дкЪТМўДІРэКЏЪ§жаЃЌЪЙгУ
FileReaderЖдЯѓЖСШЁгУЛЇбЁдёЕФЭМЦЌЮФМўЃЌВЂНЋЦфзЊЛЛЮЊ Data URL ИёЪНЁЃ - дквьВНШЮЮё
recognizeText()жажДааЮФБОЪЖБ№ЁЃЭЈЙ§НЋЮФБОЪЖБ№ВйзїАќзАдкPromiseЖдЯѓжаЃЌЪЙЦфГЩЮЊвЛИівьВНШЮЮёЁЃетбљПЩвдШЗБЃЮФБОЪЖБ№ВйзїдкКѓЬЈНјааЃЌВЛЛсзшШћгУЛЇНчУцЁЃ - ЕБвьВНШЮЮёЭъГЩЪБЃЈМДЮФБОЪЖБ№ВйзїЭъГЩЪБЃЉЃЌНЋЪЖБ№НсЙћИќаТЕНвГУцЩЯЁЃетЭЈЙ§
PromiseЖдЯѓЕФНтЮіКЏЪ§ЪЕЯжЁЃ
ЭЈЙ§етИіЪОР§ЃЌгУЛЇПЩвддкЭјвГжажДааЮФБОЪЖБ№ВйзїЃЌЖјВЛЛсгАЯьЕНгУЛЇНчУцЕФЯьгІадФмЁЃ
6ЁЂGPU МгЫй
дк Tesseract.js жаЃЌGPU МгЫйЪЧЭЈЙ§дкфЏРРЦїЛЗОГжаЪЙгУ WebGL ММЪѕРДЪЕЯжЕФЁЃвдЯТЪЧвЛИіМђЕЅЕФДњТыЪОР§ЃЌбнЪОШчКЮдк Tesseract.js жаЦєгУ GPU МгЫйЃК
<html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>GPU Acceleration Text Recognition Demo</title> <script src="https://cdn.jsdelivr.net/npm/tesseract.js@2.3.0/dist/tesseract.min.js"></script> </head> <body> <input type="file" id="fileInput" accept="image/*"> <div id="output">Processing...</div> <script> document.getElementById('fileInput').addEventListener('change', function(event) { const file = event.target.files[0]; const reader = new FileReader(); reader.onload = function(event) { const imgData = event.target.result; // дквьВНШЮЮёжажДааЮФБОЪЖБ№ recognizeText(imgData); }; reader.readAsDataURL(file); }); function recognizeText(imgData) { // ЦєгУ GPU МгЫй Tesseract.setOcrStrategy(Tesseract.OcrStrategy.AUTO); // ЪЙгУ Promise РДАќзАвьВНВйзї new Promise((resolve, reject) => { // дквьВНШЮЮёжажДааЮФБОЪЖБ№ Tesseract.recognize( imgData, 'eng', // ЪЖБ№гябдЃЈгЂЮФЃЉ { logger: m => console.log(m) } // ПЩбЁЕФШежОКЏЪ§ЃЌгУгкВщПДДІРэНјЖШ ).then(({ data: { text } }) => { // НЋЪЖБ№НсЙћДЋЕнИј Promise ЕФНтЮіКЏЪ§ resolve(text); }).catch(error => { // ШчЙћЗЂЩњДэЮѓЃЌНЋДэЮѓаХЯЂДЋЕнИј Promise ЕФОмОјКЏЪ§ reject(error); }); }).then(text => { // вьВНШЮЮёЭъГЩКѓЃЌИќаТвГУцЩЯЕФЮФБОФкШн document.getElementById('output').innerText = text; }).catch(error => { // ДІРэДэЮѓЧщПіЃЌР§ШчЪфГіДэЮѓаХЯЂЕНПижЦЬЈ console.error('Error:', error); }); } </script> </body> </html>
ТпМгыдРэНтЪЭШчЯТЃК
- гУЛЇдкЭјвГжабЁдёвЊЩЯДЋЕФЭМЦЌЮФМўЁЃетвЛВНЭЈЙ§HTMLЕФ
<input type="file">дЊЫиЪЕЯжЁЃ JavaScriptМрЬ§ЮФМўЪфШызжЖЮЕФБфЛЏЪТМўЁЃвЛЕЉгУЛЇбЁдёСЫЮФМўЃЌЛсДЅЗЂЪТМўДІРэКЏЪ§ЁЃ- дкЪТМўДІРэКЏЪ§жаЃЌЪЙгУ
FileReaderЖдЯѓЖСШЁгУЛЇбЁдёЕФЭМЦЌЮФМўЃЌВЂНЋЦфзЊЛЛЮЊ Data URL ИёЪНЁЃ - дквьВНШЮЮё
recognizeText()жажДааЮФБОЪЖБ№ЁЃЭЈЙ§НЋЮФБОЪЖБ№ВйзїАќзАдкPromiseЖдЯѓжаЃЌЪЙЦфГЩЮЊвЛИівьВНШЮЮёЁЃетбљПЩвдШЗБЃЮФБОЪЖБ№ВйзїдкКѓЬЈНјааЃЌВЛЛсзшШћгУЛЇНчУцЁЃ - дкЕїгУ
recognize()ЗНЗЈжЎЧАЃЌЪЙгУTesseract.setOcrStrategy()РДЦєгУ GPU МгЫйЁЃетНЋЪЙTesseract.jsГЂЪдЪЙгУ GPU РДМгЫйЮФБОЪЖБ№Й§ГЬЁЃ
ЭЈЙ§етИіЪОР§ЃЌгУЛЇПЩвддкЭјвГжаЦєгУ GPU МгЫйвдМгПьЮФБОЪЖБ№ЫйЖШЃЌДгЖјЬсЩ§гУЛЇЬхбщЁЃ
7ЁЂздЖЈвхЪЖБ№ФЃаЭ
Tesseract.jsжЇГжздЖЈвхЪЖБ№ФЃаЭЃЌетЪЙЕУгУЛЇПЩвдИљОнздМКЕФашЧѓбЕСЗФЃаЭЃЌвдЬсИпЬиЖЈРраЭЮФБОЛђЬиЖЈгябдЕФЪЖБ№зМШЗТЪЁЃвдЯТЪЧвЛИіМђЕЅЕФЪОР§ДњТыЃЌбнЪОШчКЮЪЙгУздЖЈвхЪЖБ№ФЃаЭЃК
<html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Custom Model Text Recognition Demo</title> <script src="https://cdn.jsdelivr.net/npm/tesseract.js@2.3.0/dist/tesseract.min.js"></script> </head> <body> <input type="file" id="fileInput" accept="image/*"> <div id="output">Processing...</div> <script> document.getElementById('fileInput').addEventListener('change', function(event) { const file = event.target.files[0]; const reader = new FileReader(); reader.onload = function(event) { const imgData = event.target.result; // дквьВНШЮЮёжажДааЮФБОЪЖБ№ recognizeText(imgData); }; reader.readAsDataURL(file); }); function recognizeText(imgData) { // ЩшжУздЖЈвхЪЖБ№ФЃаЭТЗОЖ const customModelPath = 'path/to/your/custom/model.traineddata'; // ЪЙгУ Promise РДАќзАвьВНВйзї new Promise((resolve, reject) => { // дквьВНШЮЮёжажДааЮФБОЪЖБ№ Tesseract.recognize( imgData, { lang: 'custom', // ЪЙгУздЖЈвхгябдБъЪЖЗћ tessedit_char_whitelist: 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789', // ЪЖБ№ЕФзжЗћАзУћЕЅ tessedit_zero_rejection: true // дЪаэСужУаХЖШЕФЪЖБ№НсЙћ } ).then(({ data: { text } }) => { // НЋЪЖБ№НсЙћДЋЕнИј Promise ЕФНтЮіКЏЪ§ resolve(text); }).catch(error => { // ШчЙћЗЂЩњДэЮѓЃЌНЋДэЮѓаХЯЂДЋЕнИј Promise ЕФОмОјКЏЪ§ reject(error); }); }).then(text => { // вьВНШЮЮёЭъГЩКѓЃЌИќаТвГУцЩЯЕФЮФБОФкШн document.getElementById('output').innerText = text; }).catch(error => { // ДІРэДэЮѓЧщПіЃЌР§ШчЪфГіДэЮѓаХЯЂЕНПижЦЬЈ console.error('Error:', error); }); } </script> </body> </html>
ТпМгыдРэНтЪЭШчЯТЃК
- гУЛЇдкЭјвГжабЁдёвЊЩЯДЋЕФЭМЦЌЮФМўЁЃетвЛВНЭЈЙ§HTMLЕФ
<input type="file">дЊЫиЪЕЯжЁЃ JavaScriptМрЬ§ЮФМўЪфШызжЖЮЕФБфЛЏЪТМўЁЃвЛЕЉгУЛЇбЁдёСЫЮФМўЃЌЛсДЅЗЂЪТМўДІРэКЏЪ§ЁЃ- дкЪТМўДІРэКЏЪ§жаЃЌЪЙгУ
FileReaderЖдЯѓЖСШЁгУЛЇбЁдёЕФЭМЦЌЮФМўЃЌВЂНЋЦфзЊЛЛЮЊ Data URL ИёЪНЁЃ - дквьВНШЮЮё
recognizeText()жажДааЮФБОЪЖБ№ЁЃЭЈЙ§НЋЮФБОЪЖБ№ВйзїАќзАдкPromiseЖдЯѓжаЃЌЪЙЦфГЩЮЊвЛИівьВНШЮЮёЁЃетбљПЩвдШЗБЃЮФБОЪЖБ№ВйзїдкКѓЬЈНјааЃЌВЛЛсзшШћгУЛЇНчУцЁЃ - дкЕїгУ
recognize()ЗНЗЈжЎЧАЃЌЭЈЙ§ЩшжУlangВЮЪ§ЮЊздЖЈвхгябдБъЪЖЗћЃЌжИЖЈЪЙгУздЖЈвхЕФЪЖБ№ФЃаЭЁЃЭЌЪБЃЌПЩвдИљОнашвЊЩшжУЦфЫћВЮЪ§ЃЌШчЪЖБ№ЕФзжЗћАзУћЕЅЁЂдЪаэСужУаХЖШЕФЪЖБ№НсЙћЕШЁЃ
ЭЈЙ§етИіЪОР§ЃЌгУЛЇПЩвддкЭјвГжаЪЙгУздЖЈвхЕФЪЖБ№ФЃаЭНјааЮФБОЪЖБ№ЃЌДгЖјЬсИпЬиЖЈРраЭЮФБОЛђЬиЖЈгябдЕФЪЖБ№зМШЗТЪЁЃ
8ЁЂШежОЪфГі
вдЯТЪЧвЛИіМђЕЅЕФДњТыЪОР§ЃЌбнЪОШчКЮдк Tesseract.js жаЪЙгУШежОЪфГіЙІФмЃК
<html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Text Recognition with Logging Demo</title> <script src="https://cdn.jsdelivr.net/npm/tesseract.js@2.3.0/dist/tesseract.min.js"></script> </head> <body> <input type="file" id="fileInput" accept="image/*"> <div id="output">Processing...</div> <script> document.getElementById('fileInput').addEventListener('change', function(event) { const file = event.target.files[0]; const reader = new FileReader(); reader.onload = function(event) { const imgData = event.target.result; // дквьВНШЮЮёжажДааЮФБОЪЖБ№ЃЌВЂМЧТМШежО recognizeText(imgData); }; reader.readAsDataURL(file); }); function recognizeText(imgData) { // ЪЙгУ Promise РДАќзАвьВНВйзї new Promise((resolve, reject) => { // дквьВНШЮЮёжажДааЮФБОЪЖБ№ЃЌВЂМЧТМШежО Tesseract.recognize( imgData, 'eng', // ЪЖБ№гябдЃЈгЂЮФЃЉ { logger: m => console.log(m) // ШежОЪфГіКЏЪ§ЃЌгУгкВщПДДІРэНјЖШ } ).then(({ data: { text } }) => { // НЋЪЖБ№НсЙћДЋЕнИј Promise ЕФНтЮіКЏЪ§ resolve(text); }).catch(error => { // ШчЙћЗЂЩњДэЮѓЃЌНЋДэЮѓаХЯЂДЋЕнИј Promise ЕФОмОјКЏЪ§ reject(error); }); }).then(text => { // вьВНШЮЮёЭъГЩКѓЃЌИќаТвГУцЩЯЕФЮФБОФкШн document.getElementById('output').innerText = text; }).catch(error => { // ДІРэДэЮѓЧщПіЃЌР§ШчЪфГіДэЮѓаХЯЂЕНПижЦЬЈ console.error('Error:', error); }); } </script> </body> </html>
ТпМгыдРэНтЪЭШчЯТЃК
- гУЛЇдкЭјвГжабЁдёвЊЩЯДЋЕФЭМЦЌЮФМўЁЃетвЛВНЭЈЙ§HTMLЕФ
<input type="file">дЊЫиЪЕЯжЁЃ JavaScriptМрЬ§ЮФМўЪфШызжЖЮЕФБфЛЏЪТМўЁЃвЛЕЉгУЛЇбЁдёСЫЮФМўЃЌЛсДЅЗЂЪТМўДІРэКЏЪ§ЁЃ- дкЪТМўДІРэКЏЪ§жаЃЌЪЙгУ
FileReaderЖдЯѓЖСШЁгУЛЇбЁдёЕФЭМЦЌЮФМўЃЌВЂНЋЦфзЊЛЛЮЊ Data URL ИёЪНЁЃ - дквьВНШЮЮё
recognizeText()жажДааЮФБОЪЖБ№ЃЌВЂЭЈЙ§ЩшжУloggerВЮЪ§РДЦєгУШежОЪфГіЙІФмЁЃетбљПЩвддкПижЦЬЈжаВщПДДІРэНјЖШКЭЦфЫћЯрЙиаХЯЂЁЃ - дкЮФБОЪЖБ№ЭъГЩКѓЃЌНЋЪЖБ№НсЙћИќаТЕНвГУцЩЯЁЃШчЙћЗЂЩњДэЮѓЃЌвВЛсдкПижЦЬЈжаЪфГіДэЮѓаХЯЂЁЃ
ЭЈЙ§етИіЪОР§ЃЌгУЛЇПЩвддкЭјвГжаЪЙгУ Tesseract.js НјааЮФБОЪЖБ№ЃЌВЂЭЈЙ§ШежОЪфГіЙІФмВщПДДІРэНјЖШКЭЕїЪдаХЯЂЁЃ
зюКѓ
ЯывЊдкЧАЖЫНтОіЭМЯёЪЖБ№ЕФажЕмЃЌПЩвдЕН Github ЩЯЯТдиTesseract.jsПтЃЌАВзАКЭЯрЙибЇЯАЮФЕЕЖМФмЯТдиЕНЃЌЪЕдкЛёШЁВЛЕНЕФажЕмевVИчЗЂИјФуЃЌМйЦкЕкЖўЬьЃЌГіШЅЗХЫЩЕФЭЌЪБвВПЩвдПДПД V ИчЕФЮФеТЃЌзЃДѓМвЭцЕУПЊаФЁЃ

![ЩюЖШбЇЯАгІгУЦЊ-МЦЫуЛњЪгОѕ-OCRЙтбЇзжЗћЪЖБ№[7]ЃКOCRзлЪіЁЂГЃгУCRNNЪЖБ№ЗНЗЈЁЂDBNetЁЂCTPNМьВтЗНЗЈЕШЁЂЦРЙРжИБъЁЂгІгУГЁОА](https://ucc.alicdn.com/fnj5anauszhew_20230611_eba1a5baa8bf41b08e8306e0af20dbcd.png?x-oss-process=image/resize,h_160,m_lfit)
