ЮЪЬтвЛЃКDataWorksетжжЧщПіЮЊЩЖЛсИцОЏ,ЃП
DataWorksетжжЧщПіЮЊЩЖЛсИцОЏ, ЙцдђЪЧгЩ'БэааЪ§, вЛЬьВюжЕ' ИФЮЊ'БэааЪ§ЩЯжмЦкВюжЕ', зђЬьдчЩЯ9ЕузѓгваоИФЕФЃП 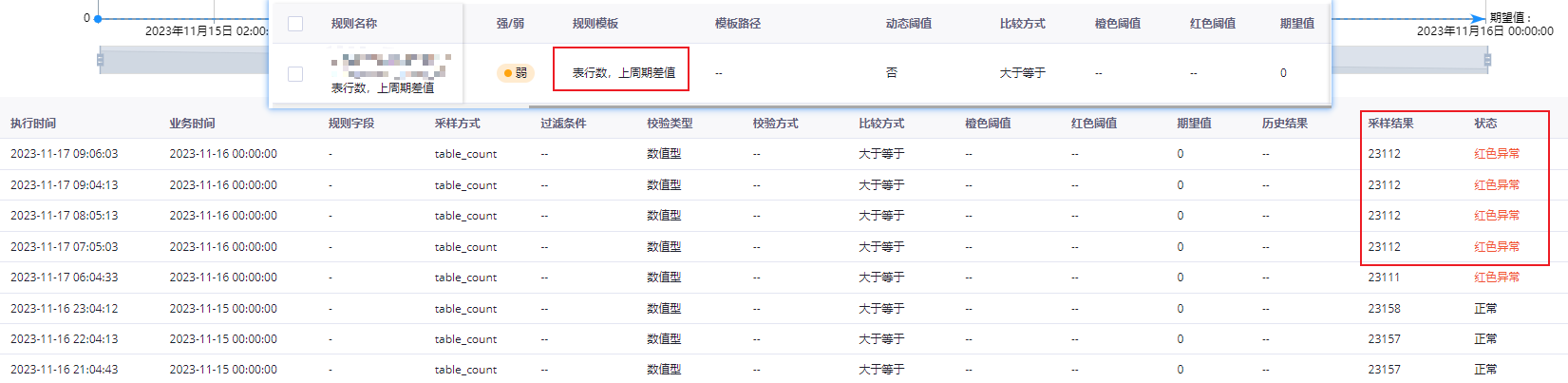
ВЮПМЛиД№ЃК
DataWorksдкжДааЪ§ОнЭЌВНШЮЮёЪБЃЌЛсИљОнФњЩшжУЕФжЪСПЙцдђНјаааЃбщЁЃЕБШЮЮёдЫааЭъГЩКѓЃЌШчЙћЗЂЯжЪ§ОнжЪСПВЛТњзуЙцдђвЊЧѓЃЌОЭЛсДЅЗЂИцОЏЁЃ
ИљОнФњЬсЙЉЕФаХЯЂЃЌЙцдђгЩ'БэааЪ§ЃЌ вЛЬьВюжЕ'ИФЮЊ'БэааЪ§ЩЯжмЦкВюжЕ'ЃЌзђЬьдчЩЯ9ЕузѓгваоИФЕФЁЃдкетжжЧщПіЯТЃЌШчЙћЭЌВНШЮЮёдкаоИФЙцдђКѓдЫааЃЌВЂЧвЪ§ОнжЪСПВЛТњзуаТЙцдђЕФвЊЧѓЃЌФЧУДОЭЛсГіЯжКьЩЋвьГЃИцОЏЁЃ
ЮЊСЫНтОіетИіЮЪЬтЃЌФњПЩвдАДеевдЯТВНжшВйзїЃК
- МьВщЭЌВНШЮЮёЕФдЫааШежОЃЌевЕНОпЬхЕФДэЮѓаХЯЂКЭдвђЁЃШежОжаЭЈГЃЛсАќКЌЯъЯИЕФДэЮѓУшЪіКЭПЩФмЕФНтОіЗНАИЁЃ
- ИљОнДэЮѓаХЯЂКЭдвђЃЌЖдЭЌВНШЮЮёНјааЕїећЁЃР§ШчЃЌФњПЩвдГЂЪдЕїећЭЌВНЦЕТЪЁЂдіМгжиЪдДЮЪ§ЕШЁЃ
ЙигкБОЮЪЬтЕФИќЖрЛиД№ПЩЕуЛїдЮФВщПДЃК/ask/571697
ЮЪЬтЖўЃКDataWorksЭЌвЛИіДњТыЃЌдкБОЕиХмБЈСЫЩЯЪіДэЮѓЃЌдѕУДЛсЪЧДЋВЮДэЮѓФиЃП
DataWorksЭЌвЛИіДњТыЃЌдкБОЕиХмБЈСЫЩЯЪіДэЮѓЃЌдкdataworksЩЯЪЧгаНсЙћЕФЃЌдѕУДЛсЪЧДЋВЮДэЮѓФиЃПУЛгаДЋВЮЃЌОЭЪЧЪЙгУСЫDataframeЛёШЁЪ§ОнЃЌЪЙгУget_table БОЕиЛёШЁОЭЪЧе§ГЃЕФ
ВЮПМЛиД№ЃК
ЖдЕФ ОЭЪЧ detail logСДНгЭтУцЕФвЛВу runlogШежОЭъећЕФЮФБО
ЙигкБОЮЪЬтЕФИќЖрЛиД№ПЩЕуЛїдЮФВщПДЃК/ask/571691
ЮЪЬтШ§ЃКDataWorksЮЊЩЖдкБОЕиЪдгУpyodps ЛсБЈДэ ЁАе§ГЃдЫаа ЭЌвЛИіДњТыЃП
DataWorksЮЊЩЖдкБОЕиЪдгУpyodps ЛсБЈДэ ЁАtypeErrorЃК codeЃЈЃЉ argument 13 must be strЃЌ not intЁБЃЌdataworks е§ГЃдЫаа ЭЌвЛИіДњТыЃП
ВЮПМЛиД№ЃК
етИіПДзХЪЧДЋЕнЕФВЮЪ§РраЭВЛЗћКЯ pyodpsПЩвдзЩбЏЯТmcЭЌбЇАяУІПДПД дкШКЙЋИцПЩвдевЕН
ЙигкБОЮЪЬтЕФИќЖрЛиД№ПЩЕуЛїдЮФВщПДЃК/ask/571689
ЮЪЬтЫФЃКDataWorksЖЫетИіБэЗЧГЃДѓ гУsizeВщВЛЖЏ етИідрЪ§ОнОпЬхЪЧФФЬѕЃП
DataWorksЖЫетИіБэЗЧГЃДѓ гУsizeВщВЛЖЏ ЯыПДЕНБЈдрЪ§ОнетЬѕ ЖдгІЕФЦфЫћзжЖЮЕФаХЯЂ гУРДЖЈЮЛ етИідрЪ§ОнОпЬхЪЧФФЬѕЃП
ВЮПМЛиД№ЃК
дкDataWorksжаЃЌШчЙћФуЯыВщПДДѓБэжаЕФФГЬѕМЧТМЃЌПЩвдЭЈЙ§SQLЕФзгВщбЏРДЪЕЯжЁЃР§ШчЃЌМйЩшФуЕФБэУћЮЊbig_tableЃЌФуЯыВщПДid=5ЕФФЧЬѕМЧТМЃЌФуПЩвдетбљаДЃК
SELECT * FROM big_table WHERE id=5;
етбљЃЌФуОЭПЩвдВщПДid=5ЕФФЧЬѕМЧТМСЫЁЃ
ШчЙћФуЕФБэЗЧГЃДѓЃЌПЩФмашвЊЛЈЗбвЛаЉЪБМфРДжДааетИіВщбЏЁЃФуПЩвдПМТЧЪЙгУЗжвГВщбЏЛђепжЛВщбЏВПЗжзжЖЮЕФЗНЪНРДЬсИпВщбЏаЇТЪЁЃР§ШчЃЌФуПЩвдетбљаДЃК
SELECT id, name FROM big_table WHERE id=5 LIMIT 10;
етбљЃЌФуОЭПЩвджЛВщПДidКЭnameетСНИізжЖЮЕФаХЯЂСЫЁЃ
ЙигкБОЮЪЬтЕФИќЖрЛиД№ПЩЕуЛїдЮФВщПДЃК/ask/571685
ЮЪЬтЮхЃКDataWorksетЪЧЪВУДдвђбНЃП
DataWorksетЪЧЪВУДдвђбНЃЌЮвАбЭЈЙ§dataworksАбБэЪ§ОнЗЂЫЭЕНkafkaЃЌБэзжЖЮШЋЪЧstringРраЭЃЌЮЊЪВУДЛсгадрЪ§ОнФиЃП 
ВЮПМЛиД№ЃК
жЛвЊУЛгааДШыГЩЙІ ОЭЛсБЛЙщЮЊдрЪ§Он ЃЌПДетИіБЈДэ ПЩФмЪЧkafkaзДЬЌвьГЃЛђЭјТчЮоЗЈСЊЭЈЁЃ
ЙигкБОЮЪЬтЕФИќЖрЛиД№ПЩЕуЛїдЮФВщПДЃК/ask/571684
