ЮЪЬтвЛЃКЮвЯыЧыЮЪЯТMДѓЪ§ОнМЦЫуMaxComputeгяЗЈЪЧВЛЪЧИќЖрЕФРрЫЦhiveЃП
ЮвЯыЧыЮЪЯТMДѓЪ§ОнМЦЫуMaxComputeгяЗЈЪЧВЛЪЧИќЖрЕФРрЫЦhiveЃП
ВЮПМД№АИЃК
ЪЧЕФЁЃ ПЩвдПЊhiveМцШнПЊЙиЁЃhttps://help.aliyun.com/zh/maxcompute/user-guide/hive-compatible-data-type-edition?spm=a2c4g.11174283.0.i2
ЙигкБОЮЪЬтЕФИќЖрЛиД№ПЩЕуЛїНјааВщПДЃК
ЮЪЬтЖўЃКЮЪЯТДѓЪ§ОнМЦЫуMaxComputeСйЪБВщбЏЁЂpyodpsРяУцЕФДњТыУЛАьЗЈздЖЏЛЛааТ№ЃП
ЮЪЯТДѓЪ§ОнМЦЫуMaxComputeСйЪБВщбЏЁЂpyodpsРяУцЕФДњТыУЛАьЗЈздЖЏЛЛааТ№ЃПЮЊЪВУДЮвгааЉДњТыКмГЄЃЌЙиБеДђПЊЫћЛсздЖЏЛЛааЃЌгааЉКУЯёгжВЛЛсЕФЃЌЮвКУЯёвГУЛгаЗЂЯжЪВУДЛЛааЕФЩшжУ
ВЮПМД№АИЃК
ПДЯТетРяЃЌздЖЏЛЛааПЩвдЩшжУ
ЙигкБОЮЪЬтЕФИќЖрЛиД№ПЩЕуЛїНјааВщПДЃК
ЮЪЬтШ§ЃКspark.aliyun.odps.datasource гаУЛгаЛљгкscala 2.12ЙЙНЈЕФАцБОЃП
ЮвЯыдкБОЕиSpark ЭЈЙ§DataSource ЗУЮЪMaxcomputer
ФПЧАЪЙгУЕФSparkЛЗОГЮЊ3.1.1ЃЌЮвашвЊЛљгкScala_2.12АцБОЙЙНЈЕФDataSourceЁЃ
ЛђепФмЬсЙЉвЛИіИќгбКУЗУЮЪMaxComputerЕФЗНЪНЁЃ
ИаМЄВЛОЁЃЁ
вдЯТЪЧЮвевЕНЕФзюИпDataSourceАцБО
groupid = com.aliyun.emr
artifactId = emr-maxcomputer_2.11
version 2.20
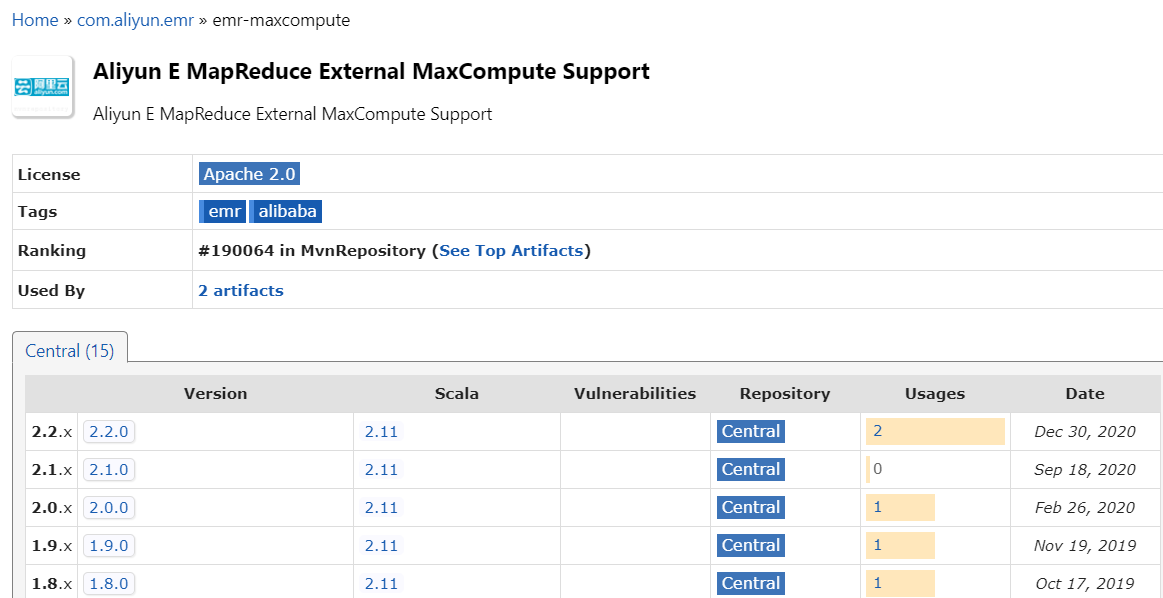
ВЮПМД№АИЃК
гУ Hadoop ЬсЙЉЕФ DataSource API:Spark ЬсЙЉСЫ Hadoop Ъ§ОндД API,ПЩвдЭЈЙ§етИі API ЗУЮЪ Hadoop ЩЯЕФЪ§ОнЁЃдкБОЕи Spark жа,ФуПЩвдЪЙгУ Hadoop ЕФПЭЛЇЖЫФЃЪНРДЗУЮЪ Hadoop ЩЯЕФЪ§ОнЁЃОпЬхЪЙгУЗНЗЈПЩвдВЮПМ Spark ЙйЗНЮФЕЕжаЙигк Hadoop Ъ§ОндДЕФНщЩмЁЃ
- ЪЙгУ Spark ЬсЙЉЕФ JDBC Ъ§ОндД API:Spark ЬсЙЉСЫ JDBC Ъ§ОндД API,ПЩвдЭЈЙ§етИі API ЗУЮЪ JDBC Ъ§ОнПтЩЯЕФЪ§ОнЁЃдкБОЕи Spark жа,ФуПЩвдЪЙгУетИі API РДЗУЮЪ MaxComputer ЩЯЕФЪ§ОнЁЃОпЬхЪЙгУЗНЗЈПЩвдВЮПМ Spark ЙйЗНЮФЕЕжаЙигк JDBC Ъ§ОндДЕФНщЩмЁЃ
- ГЂЪдЪЙгУЦфЫћЪ§ОндД:ШчЙћвдЩЯСНжжЗНЗЈЖМВЛТњзуФуЕФашЧѓ,ФуПЩвдГЂЪдЪЙгУЦфЫћЪ§ОндДЁЃР§Шч,ФуПЩвдЪЙгУ Hive Ъ§ОндДЁЂSolr Ъ§ОндДЁЂElasticsearch Ъ§ОндДЕШЕШЁЃетаЉЪ§ОндДЖМгаЖдгІЕФ Spark API,ФуПЩвдИљОнашЧѓбЁдёКЯЪЪЕФЪ§ОндДЁЃ
ЙигкБОЮЪЬтЕФИќЖрЛиД№ПЩЕуЛїНјааВщПДЃК
ЮЪЬтЫФЃКmaxcomputer НЈБэЃЌПЩвдздЖЏЩњВњБэНсЙЙТ№ЃПАДееНгШыЕФЪ§ОндД
maxcomputer НЈБэЃЌПЩвдздЖЏЩњВњБэНсЙЙТ№ЃПАДееНгШыЕФЪ§ОндД
ВЮПМД№АИЃК
MaxCompute ПЩвдЮЊгУЛЇЬсЙЉздЖЏНЈБэЕФЙІФмЁЃ MaxCompute ЬсЙЉСЫвЛжжГЦЮЊ SQL Like ЕФгябдгяЗЈЃЌгУгкУшЪіЪ§ОнБэНсЙЙВЂДДНЈБэЁЃ MaxCompute жЇГжЪЙгУРрЫЦгк SQL ЕФгяОфРДЖЈвхБэНсЙЙЃЌВЂжЇГжвдЯТМИжжРраЭЃК
- БэДДНЈгяОф
- зжЖЮЖЈвхгяОф
- Ъ§ОнВхШыгяОф
- Ъ§ОнВщбЏгяОф
MaxCompute ЛЙЬсЙЉСЫздЖЏНЈБэЙІФмЃЌПЩвдИљОнЕМШыЕФЪ§ОндДздЖЏЭЦЕМГіБэНсЙЙЃЌВЂЩњГЩЯргІЕФ SQL Like гяОфЁЃ гУЛЇПЩвдЭЈЙ§вдЯТМИИіВНжшЪЕЯжздЖЏНЈБэЃК
- ЕМШыЪ§ОндД
- ЪЙгУ
describeЛђshow create tableВщПДБэНсЙЙ - ИљОнЗЕЛиНсЙћЙЙНЈ SQL Like гяОф
- жДаа SQL Like гяОфДДНЈБэ
ЙигкБОЮЪЬтЕФИќЖрЛиД№ПЩЕуЛїНјааВщПДЃК
ЮЪЬтЮхЃКApacheFLinkШЮЮёЪЕЪБЯћЗбKafkaДАПкЕФМЦЫувЊИФГЩmaxcomputeвЊдѕУДЪЕЯжФиЃП
дкдРДЕФЪ§ОнДІРэМмЙЙжа гавЛИіApache FLinkШЮЮёЪЕЪБЯћЗбKafka зівЛИіДАПкЕФМЦЫу ЯждквЊИФГЩmaxcomputeЛАвЊдѕУДЪЕЯжФиетИіЪЕЪБМЦЫуШЮЮёФиЃП
ВЮПМД№АИЃК
ШчЙћФуЯывЊНЋЯжгаЕФ Apache Flink ЪЕЪБМЦЫуШЮЮёИФЮЊЪЙгУ MaxCompute НјааДІРэЃЌПЩвдЭЈЙ§вдЯТВНжшЪЕЯжЃК
- НЋЪЕЪБЪ§ОндДДг Kafka ИФЮЊжЇГж MaxCompute ЕФЪ§ОндДЃЌШч MaxCompute DataHub Лђ MaxCompute Table StoreЁЃетбљПЩвдЪЙ MaxCompute ФмЙЛжБНгЖСШЁЪЕЪБЪ§ОнЁЃ
- ЪЙгУ MaxCompute SQL Лђ UDF РДЪЕЯжДАПкМЦЫуЁЃMaxCompute ЬсЙЉСЫвЛЯЕСаИпМЖКЏЪ§КЭВйзїЗћЃЌПЩвдгУгкЪЕЯжИДдгЕФДАПкМЦЫуашЧѓЁЃФњПЩвддк MaxCompute SQL жаЪЙгУетаЉКЏЪ§КЭВйзїЗћЃЌЛђепБраДздЖЈвхЕФ User Defined Function (UDF) РДЪЕЯжИќМгИДдгЕФДАПкМЦЫуТпМЁЃ
- НЋМЦЫуНсЙћБЃДцЕН MaxCompute БэжаЁЃMaxCompute ЬсЙЉСЫвЛжжМђЕЅЖјПЩППЕФЗНЪНРДДцДЂКЭЙмРэЪ§ОнЃЌФњПЩвдНЋМЦЫуНсЙћБЃДцЕН MaxCompute БэжавдБуНјааНјвЛВНЕФЗжЮіКЭДІРэЁЃ
ЙигкБОЮЪЬтЕФИќЖрЛиД№ПЩЕуЛїНјааВщПДЃК
