ЮЪЬтвЛЃКДѓЪ§ОнМЦЫуMaxComputeВщбЏmax-computeЕФБэЪ§ОнБЈетИіДэЪЧдѕУДЛиЪТАЁЃП
ДѓЪ§ОнМЦЫуMaxComputeЮвгУYarn-clusterФЃЪНВщбЏmax-computeЕФБэЪ§ОнБЈетИіДэЪЧдѕУДЛиЪТАЁЃПЮФЕЕЫбВЛЕНБЈДэдвђ 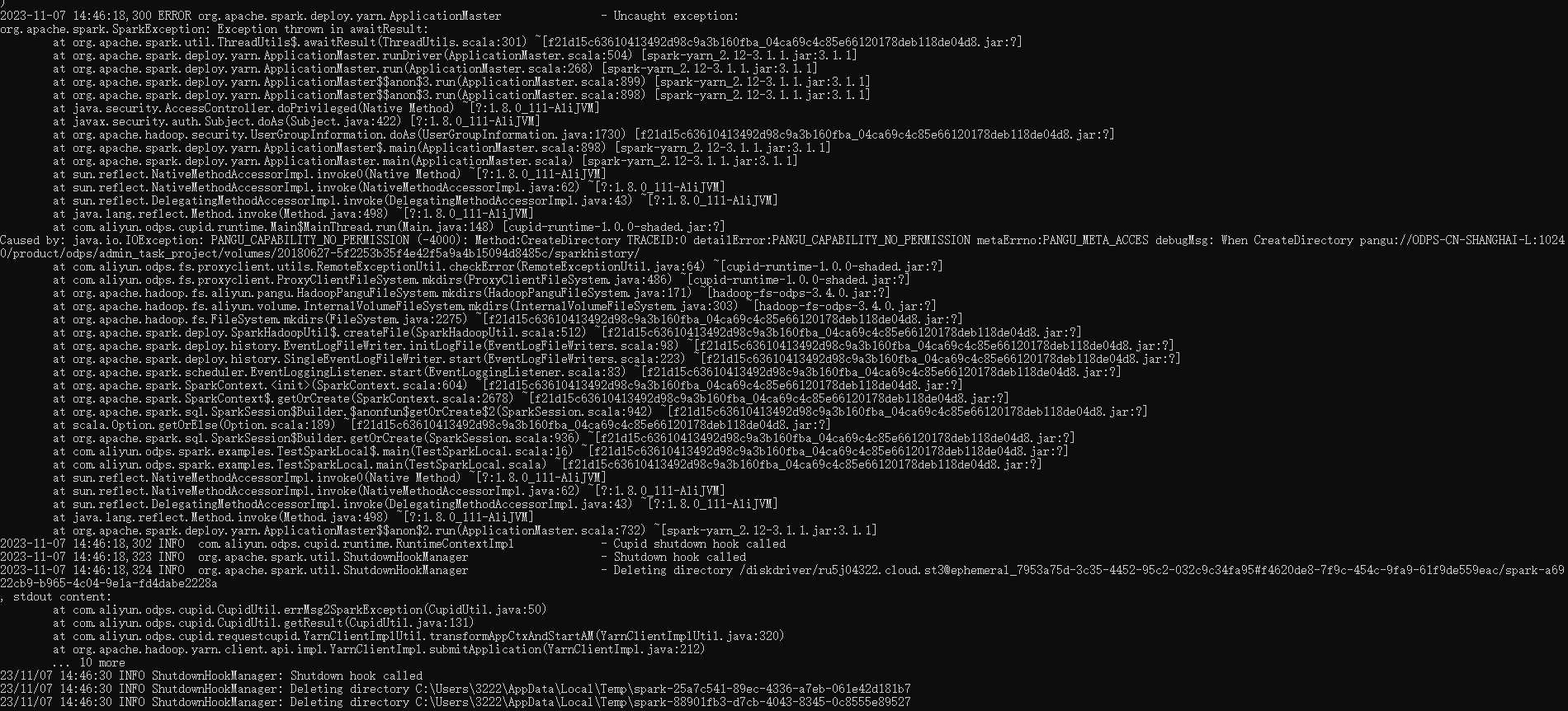
ВЮПМД№АИЃК
ЪЙгУ Spark КЭ Yarn МЏШКФЃЪНЪБгіЕНСЫвЛИіДэЮѓЁЃДэЮѓЕФОпЬхдвђПЩФмашвЊНјвЛВНЗжЮіЁЃ
ЮЊСЫНтОіетИіЮЪЬтЃЌФњПЩвдГЂЪдвдЯТВНжшЃК
- МьВщФњЕФ Spark АцБОЪЧЗёгыФњЕФМЏШКМцШнЁЃШЗБЃФњЕФ Spark АцБОгыФњЕФ Yarn МЏШКАцБОМцШнЁЃ
- МьВщФњЕФМЏШКХфжУЃЌШЗБЃФњЕФМЏШКгазуЙЛЕФзЪдДРДдЫааФњЕФ Spark гІгУГЬађЁЃетПЩФмЩцМАЕНМьВщФњЕФ Yarn МЏШКЕФФкДцЁЂCPU КЭДцДЂзЪдДЁЃ
- МьВщФњЕФгІгУГЬађШежОЃЌвдЛёШЁИќЖрЙигкДэЮѓЕФЯъЯИаХЯЂЁЃетПЩвдАяжњФњШЗЖЈЮЪЬтЫљдкЃЌВЂВЩШЁЪЪЕБЕФДыЪЉНтОіЮЪЬтЁЃ
ЙигкБОЮЪЬтЕФИќЖрЛиД№ПЩЕуЛїНјааВщПДЃК
ЮЪЬтЖўЃКДѓЪ§ОнМЦЫуMaxComputeББУРЧаГЩЖЌСюЪБСЫЃЌИцОЏЙцдђЗўЮёЦїЖдгІЕФЪБЧјЃЌЪЧВЛЪЧвВашвЊФуУЧЕївЛЯТЃП
ДѓЪ§ОнМЦЫуMaxComputeББУРЧаГЩЖЌСюЪБСЫЃЌИцОЏЙцдђЗўЮёЦїЖдгІЕФЪБЧјЃЌЪЧВЛЪЧвВашвЊФуУЧЕївЛЯТЃП
ВЮПМД№АИЃК
ЙигкБОЮЪЬтЕФИќЖрЛиД№ПЩЕуЛїНјааВщПДЃК
ЮЪЬтШ§ЃКДѓЪ§ОнМЦЫуMaxComputeетИіЕїећФФИіАЁЃП
FAILED: Metering data exceed max value. Input: 14.534129GB, Complexity: 4.0, Max Value: 40
ДѓЪ§ОнМЦЫуMaxComputeетИіЕїећФФИіАЁЃП
ВЮПМД№АИЃК
ЕЅSQLЯћЗбЯожЦЁЃhttps://help.aliyun.com/zh/maxcompute/product-overview/consumption-control?spm=a2c4g.11186623.0.0.3f606a90nstdO3#section-dt6-yj2-osc
ЙигкБОЮЪЬтЕФИќЖрЛиД№ПЩЕуЛїНјааВщПДЃК
ЮЪЬтЫФЃКДѓЪ§ОнМЦЫуMaxComputeАДЙйЭјЩЯЕФЗНЗЈЃЌШЛКѓБЈетИіДэСЫЃП
ДѓЪ§ОнМЦЫуMaxComputeАДЙйЭјЩЯЕФЗНЗЈЃЌspark3.1.1ЭЈЙ§resourceФПТМЯТЕФconfЮФМўХфжУЃЌШЛКѓБЈетИіДэСЫЃП 
ВЮПМД№АИЃК
зюКѓhiveФЧИіВЮЪ§ШЅЕєЪдЯТ
ЙигкБОЮЪЬтЕФИќЖрЛиД№ПЩЕуЛїНјааВщПДЃК
ЮЪЬтЮхЃКДѓЪ§ОнМЦЫуMaxComputeетИіЮЪЬтдѕУДНтОіАЁЃП
ДѓЪ§ОнМЦЫуMaxComputeетИіЮЪЬтдѕУДНтОіАЁЃПЯждкВщБэЩОБэОЭБЈетИіДэ 
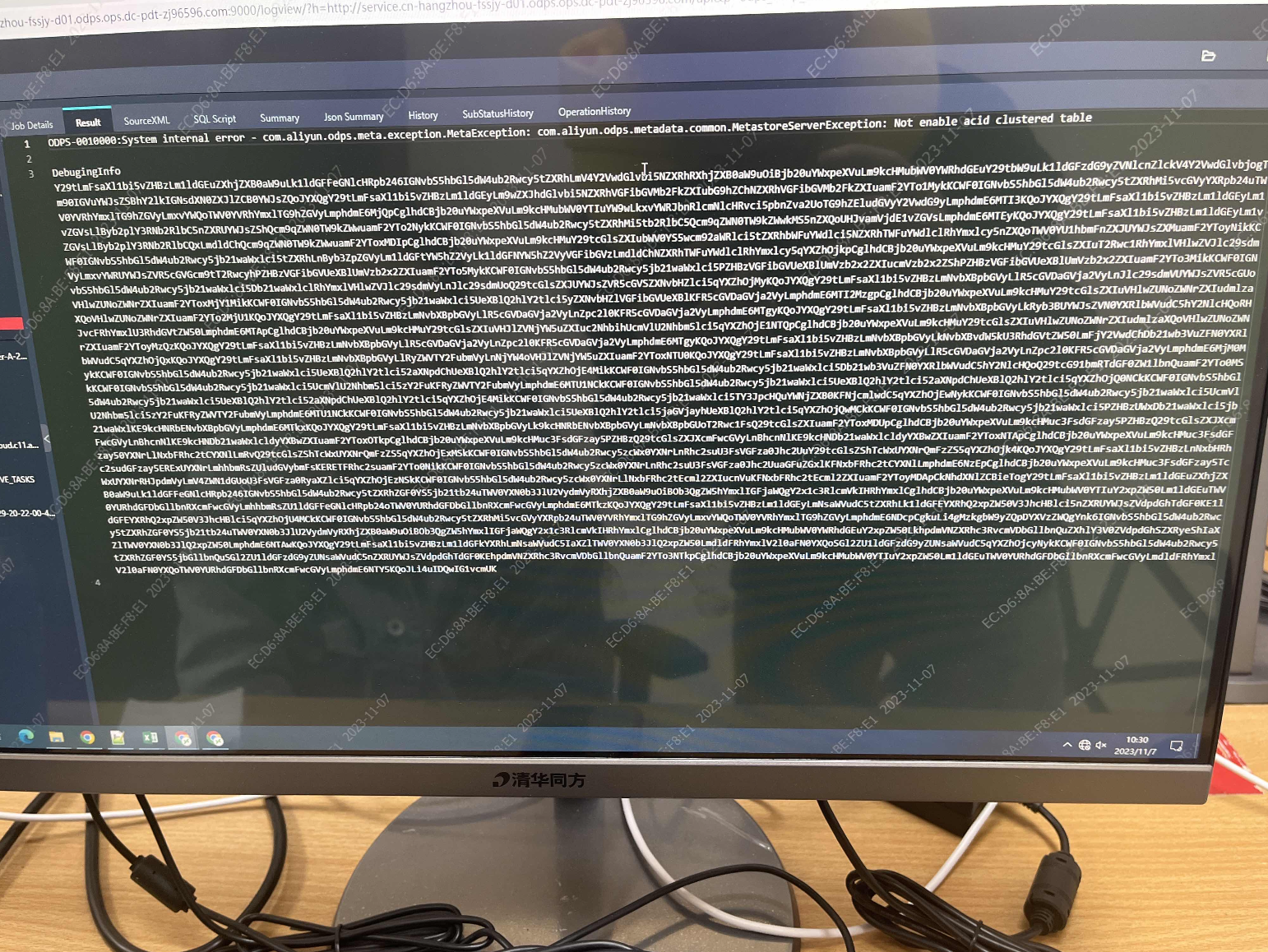
ВЮПМД№АИЃК
етИіБЈДэИњSQLЕФАцБОгаЙиЯЕЁЃ
ЙигкБОЮЪЬтЕФИќЖрЛиД№ПЩЕуЛїНјааВщПДЃК
