Ъ§ОнЗжЦЌЃЈData ShardingЃЉЪЧвЛжжНЋДѓЙцФЃЪ§ОнМЏЗжИюГЩЖрИіНЯаЁЁЂПЩЙмРэЕФЪ§ОнПщЃЈГЦЮЊЗжЦЌЛђЫщЦЌЃЉЃЌВЂНЋетаЉЗжЦЌЗжВМЕНЖрИіЖРСЂЕФДцДЂНкЕуЃЈШчЪ§ОнПтЗўЮёЦїЁЂЮФМўЯЕЭГЛђЗжВМЪНДцДЂЯЕЭГЃЉЩЯЕФММЪѕЁЃетжжММЪѕжївЊгІгУгкДѓЪ§ОнДцДЂЁЂЪ§ОнПтЯЕЭГКЭЗжВМЪНМЦЫуГЁОАЃЌФПЕФЪЧЪЕЯжЪ§ОнЕФЫЎЦНРЉеЙЁЂЬсЩ§ЯЕЭГадФмЁЂдіЧППЩгУадКЭШнДэФмСІЁЃвдЯТЪЧЪ§ОнЗжЦЌЕФЛљБОИХФюЁЂЙЄзїдРэЁЂГЃМћЗНЗЈМАЦфгІгУГЁОАЃК
вЛЁЂЛљБОИХФю
1. ЗжЦЌЃЈShardЃЉ
- ЗжЦЌЪЧЪ§ОнЗжЦЌКѓЕФЖРСЂЪ§ОнПщЃЌУПИіЗжЦЌАќКЌдЪМЪ§ОнМЏЕФвЛВПЗжЁЃЗжЦЌПЩвдЪЧЮяРэЩЯЕФЃЈШчВЛЭЌЕФгВХЬЛђЗўЮёЦїЃЉЃЌвВПЩвдЪЧТпМЩЯЕФЃЈШчЪ§ОнПтБэЕФвЛВПЗжЃЉЁЃ
2. ЗжЦЌМќЃЈSharding KeyЃЉ
- ЗжЦЌМќЪЧОіЖЈЪ§ОнШчКЮЗжХфЕНИїИіЗжЦЌЕФЙиМќзжЖЮЁЃИљОнЗжЦЌМќЕФжЕЃЌЪ§ОнЛсБЛгГЩфЕНЬиЖЈЕФЗжЦЌЩЯЁЃбЁдёКЯЪЪЕФЗжЦЌМќЖдгкЪ§ОнЗжЦЌЕФгааЇадКЭадФмжСЙиживЊЁЃ
ЖўЁЂЙЄзїдРэ
1. ЗжЦЌВпТд
- ЗЖЮЇЗжЦЌЃКИљОнЗжЦЌМќжЕЕФЗЖЮЇЃЈШчЪ§жЕЧјМфЛђЪБМфЧјМфЃЉНЋЪ§ОнЗжХфЕНВЛЭЌЗжЦЌЁЃР§ШчЃЌАДеегУЛЇIDЕФЪ§жЕЗЖЮЇЛЎЗжЗжЦЌЁЃ
- ЙўЯЃЗжЦЌЃКЪЙгУЙўЯЃКЏЪ§ЖдЗжЦЌМќНјааМЦЫуЃЌНЋЙўЯЃжЕгГЩфЕНЬиЖЈЗжЦЌЁЃР§ШчЃЌЖдгУЛЇIDНјааЙўЯЃЃЌШЛКѓШЁФЃЗжЦЌзмЪ§ЃЌШЗЖЈЪ§ОнЙщЪєЕФЗжЦЌЁЃ
- СаБэЗжЦЌЃКИљОнЗжЦЌМќжЕдкдЄЖЈвхСаБэжаЕФЮЛжУЗжХфЪ§ОнЁЃЪЪгУгкЪ§ОнЗжВМвбжЊЧвЯрЖдЙЬЖЈЕФГЁОАЁЃ
2. Ъ§ОнТЗгЩ
- ПЭЛЇЖЫЛђжаМфМўИљОнЗжЦЌВпТдМЦЫуГіЪ§ОнгІДцДЂЛђВщбЏЕФЗжЦЌЮЛжУЃЌШЛКѓжБНггыЯргІЗжЦЌНЛЛЅЁЃетЭЈГЃЩцМАЗжЦЌМќЕФНтЮіЁЂЙўЯЃМЦЫуЛђЗЖЮЇВщевЁЃ
3. Ъ§ОнЗжВМгыЦНКт
- ЫцзХЪ§ОндіГЄЛђНкЕуБфЛЏЃЌПЩФмашвЊЕїећЗжЦЌЗжВМвдБЃГжЪ§ОнОљКтЁЃетПЩФмЩцМАЪ§ОнЧЈвЦЁЂжиаТЙўЯЃЛђЗЖЮЇЕїећЁЃ
Ш§ЁЂГЃМћЗНЗЈ
1. ПЭЛЇЖЫЗжЦЌ
- ПЭЛЇЖЫЃЈШчгІгУГЬађЃЉИКд№МЦЫуЗжЦЌМќВЂжБНггыЯргІЗжЦЌНЛЛЅЁЃМђЕЅЕЋдіМгСЫПЭЛЇЖЫЕФИДдгадЃЌЧвФбвдЪЕЯжШЋОжЪ§ОнЙмРэВпТдЁЃ
2. жаМфМўЗжЦЌ
- ЪЙгУзЈУХЕФЗжЦЌжаМфМўЃЈШчДњРэЗўЮёЦїЁЂЪ§ОнПтТЗгЩВуЃЉДІРэЗжЦЌМЦЫуКЭЪ§ОнТЗгЩЁЃжаМфМўЭГвЛЙмРэЗжЦЌВпТдКЭЪ§ОнЗжВМЃЌМѕЧсПЭЛЇЖЫИКЕЃЃЌвзгкЪЕЯжЪ§ОнЧЈвЦКЭРЉШнЁЃ
3. Ъ§ОнПтФкНЈЗжЦЌ
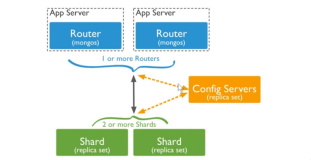
- вЛаЉЪ§ОнПтЯЕЭГЃЈШчMongoDBЁЂCassandraЁЂRedis ClusterЕШЃЉФкжУСЫЗжЦЌжЇГжЃЌЬсЙЉЭИУїЕФЗжЦЌЙмРэКЭЪ§ОнТЗгЩЁЃгУЛЇжЛашХфжУЗжЦЌВпТдЃЌЪ§ОнПтздааДІРэЗжЦЌЯИНкЁЃ
ЫФЁЂгІгУГЁОА
1. ДѓЪ§ОнДцДЂ
- ЕБЪ§ОнСПГЌЙ§ЕЅвЛДцДЂЩшБИЕФШнСПЯожЦЪБЃЌЭЈЙ§ЗжЦЌНЋЪ§ОнЗжВМЕНЖрЬЈЗўЮёЦїЃЌЪЕЯжНќКѕЮоЯоЕФДцДЂРЉеЙЁЃ
2. ИпВЂЗЂЗУЮЪ
- ЗжЦЌПЩвдЗжЩЂЖСаДЧыЧѓЃЌБмУтЕЅЕуЦПОБЃЌЬсИпЯЕЭГећЬхДІРэФмСІЁЃУПИіЗжЦЌПЩвдЖРСЂДІРэЧыЧѓЃЌЪЕЯжЫЎЦНРЉеЙЁЃ
3. ИпПЩгУгыШнДэ
- ЗжЦЌЪ§ОндкЖрИіНкЕуЩЯШпгрДцДЂЃЌЕЅИіНкЕуЙЪеЯВЛгАЯьећЬхЗўЮёЁЃПЩЭЈЙ§БИЗнЁЂИДжЦЛђЙЪеЯзЊвЦЛњжЦБЃжЄЪ§ОнЕФГжајПЩгУадЁЃ
4. ГЁОАОйР§
- ДѓаЭЩчНЛЭјТчЕФгУЛЇЪ§ОнЁЂЯћЯЂМЧТМЕШЁЃ
- ЕчЩЬЦНЬЈЕФЖЉЕЅаХЯЂЁЂЩЬЦЗПтДцЁЂгУЛЇааЮЊЪ§ОнЕШЁЃ
- IoTЃЈЮяСЊЭјЃЉЯЕЭГЕФЩшБИзДЬЌЁЂДЋИаЦїЪ§ОнЕШЁЃ
- Н№ШкаавЕЕФНЛвзМЧТМЁЂгУЛЇеЫЛЇаХЯЂЕШЁЃ
ЮхЁЂзЂвтЪТЯю
- Ъ§ОнЧуаБЃКБмУтЗжЦЌВпТдЕМжТЪ§ОнЗжВМВЛОљЃЌдьГЩФГаЉЗжЦЌИКдиЙ§ИпЁЃ
- ПчЗжЦЌВйзїЃКДІРэЩцМАЖрИіЗжЦЌЕФЪТЮёЁЂСЊНгВщбЏЕШИДдгВйзїЪБЃЌПЩФмашвЊЖюЭтЕФаЕїЛњжЦЁЃ
- ЗжЦЌМќбЁдёЃКгІбЁдёФмЙЛОљдШЗжВМЪ§ОнЁЂЗДгГЗУЮЪФЃЪНВЂвзгкРЉеЙЕФЗжЦЌМќЁЃ
- Ъ§ОнЧЈвЦГЩБОЃКПМТЧЗжЦЌЕїећЪБЕФЪ§ОнЧЈвЦДњМлЃЌЩшМЦвзгкжизщЕФЗжЦЌВпТдЁЃ
змНсРДЫЕЃЌЪ§ОнЗжЦЌЪЧвЛжжгааЇЕФДѓЪ§ОнЙмРэКЭЗжВМЪНЯЕЭГЩшМЦММЪѕЃЌЭЈЙ§НЋЪ§ОнЧаЗжГЩЖрИіЗжЦЌВЂЗжВМдкЖрИіДцДЂНкЕуЩЯЃЌЪЕЯжЪ§ОнЕФЫЎЦНРЉеЙЁЂЬсЩ§ЯЕЭГадФмЁЂдіЧППЩгУадКЭШнДэФмСІЁЃбЁдёКЯЪЪЕФЗжЦЌВпТдЁЂЗжЦЌМќвдМАЗжЦЌЙмРэЗНЗЈЪЧЪЕЪЉЪ§ОнЗжЦЌЕФЙиМќЁЃ