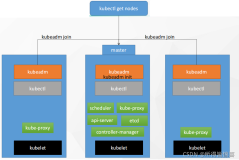
在现代云计算环境中,容器化技术已经成为了标准部署手段,其中 Kubernetes 作为容器编排的事实标准,其性能直接影响到应用的稳定性与效率。因此,对 Kubernetes 集群进行持续的性能优化是保障服务质量的必要措施。以下是几个关键方面的性能优化策略:
首先,监控是性能优化的前提。通过集成如 Prometheus 这样的监控工具,我们可以实时获取节点和容器的资源使用情况,包括 CPU、内存、网络和磁盘 I/O。此外,对于应用性能指标(如延迟和吞吐量)的跟踪同样不可或缺。这些数据不仅帮助我们识别瓶颈,还提供了优化的基础。
其次,资源管理是确保集群稳定运行的关键。Kubernetes 提供了多种资源管理机制,例如 cgroups 和 ResourceQuotas,它们可以帮助限制和分配资源。通过合理配置 Pod 的 CPU 和内存请求/限制,我们能够避免资源的过度分配和浪费,从而提升整体的资源利用效率。
接着,网络优化是提高服务响应速度的重要环节。在大规模集群中,跨节点通信往往会引入延迟。采用高性能的网络解决方案,比如 DPDK 或者 Cilium,可以显著减少网络延迟。同时,合理规划服务部署和配置负载均衡策略也能有效缩短服务间的通信路自动化是持续优化过程中不可或缺的一环。通过脚本和工具自动化常规的调优任务,例如自动扩展、资源回收以及故障恢复,可以降低人为干预的需要,并提高效率。此外,机器学习等智能技术的应用正在逐渐成为自动化运维的新趋势。
最后,实践表明定期进行压力测试和性能审查是发现问题的有效方法。通过模拟高负载情况检验集群的极限性能,可以及时发现潜在的性能问题。结合性能日志和监控数据,运维团队应定期评估现有的配置和资源分配策略,根据业务发展动态调整优化计划。
综上所述,Kubernetes 集群的性能优化是一个涉及监控、资源管理、网络优化及自动化等多个层面的复杂工程。通过上述策略的实施,我们不仅可以确保集群的高效稳定运行,还能够适应快速变化的业务需求,实现持续的服务优化。