ЪВУДЪЧZero-ETL
- ETL ЪЧНЋЩЯВувЕЮёЯЕЭГЕФЪ§ОнОЙ§ЬсШЁ(Extract)ЁЂзЊЛЛЧхЯД(Transform)ЁЂМгди(Load)ЕНЪ§ОнВжПтЕФДІРэЙ§ГЬЃЌФПЕФЪЧНЋЩЯгЮЗжЩЂЕФЪ§ОнећКЯЕНФПБъЖЫЪ§ВжЃЌЭЈЙ§дкЪ§ВжжазіНјвЛВНЕФМЦЫуЗжЮіЃЌРДЮЊвЕЮёзігааЇЕФЩЬвЕОіВпЁЃ
ПЊЗЂДЋЭГЕФETLСїГЬЃЌОпБИвдЯТЬєеНЃК
- зЪдДГЩБОдіМгЃКВЛЭЌЕФЪ§ОндДПЩФмашвЊВЛЭЌЕФETLЙЄОпЃЌДюНЈETLСДТЗЛсВњЩњЖюЭтЕФзЪдДГЩБО
- ЯЕЭГИДдгЖШдіМгЃКгУЛЇашвЊздааЮЌЛЄETLЙЄОпЃЌдіМгСЫдЫЮЌФбЖШЃЌЮоЗЈзЈзЂгквЕЮёгІгУЕФПЊЗЂ
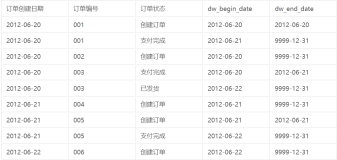
- Ъ§ОнЪЕЪБадНЕЕЭЃКВПЗжETLСїГЬЩцМАжмЦкадЕФХњСПИќаТЃЌдкНќЪЕЪБЕФгІгУГЁОАжаЃЌЮоЗЈзіЕНПьЫйВњГіЗжЮіНсЙћЁЃ
Zero-ETLЪЧжМдкЮЊгУЛЇМѕЩйВЛЭЌЪ§ОндДМфШЫЙЄЧЈвЦЛђЭЌВНЕФЙЄзїСПЃЌНЕЕЭETLЕФГЩБОКЭИДдгЖШЃЌШУгУЛЇВЛашвЊПЊЗЂКЭЙизЂETLСїГЬЃЌзЈзЂгкЩЯВуЕФгІгУПЊЗЂКЭЪ§ОнЗжЮіЁЃ
АЂРядЦбўГиЪ§ОнПтЬсЙЉЕФZero-ETLЗўЮё
Zero-ETLгХЪЦ
АЂРядЦбўГиЪ§ОнПтZero-ETLжМдкЪЕЯжЪТЮёДІРэКЭЪ§ОнЗжЮівЛЬхЛЏЃЌЪЕЯжНЈВжГЩБОЕФНЕЕЭЃЌНЈВжаЇТЪЕФЬсЩ§ЁЃ
ФПЧАЪЙгУZero-ETLЗНАИЃЌЪ§ОнНгШыГЩБОПЩЯТНЕ30%ЃЌЙЙНЈЪ§ОнВжПтЕФаЇТЪПЩЬсЩ§60%ЁЃ
змНсРДПДЃЌZero-ETLЕФгХЪЦШчЯТЃК
СуГЩБОЃКЬсЙЉЕЭГЩБОЕФЪ§ОнНгШыСДТЗЃЌгУЛЇПЩУтЗбЛђМЋЕЭГЩБОЪЕЯждкAnalyticDBжаЖдЩЯгЮPolarDBЪ§ОнНјааЗжЮі
взгУадКУЃКЮоашДДНЈКЭЮЌЛЄжДааETLЃЈЬсШЁЁЂзЊЛЛЁЂМгдиВйзїЃЉЕФИДдгЪ§ОнЙмЕРЃЌНіашбЁдёдДЖЫЪ§ОнКЭФПБъЖЫЪЕР§ЃЌздЖЏДДНЈЪЕЪБЪ§ОнЭЌВНСДТЗЃЌМѕЩйЙЙНЈКЭЙмРэЪ§ОнЙмЕРЫљДјРДЕФЬєеНЃЌзЈзЂЩЯВугІгУПЊЗЂ
ЖрдДЛуМЏЃКZero-ETLЕФФПБъЖЫПЩвдЬсЙЉШЋОжЪгНЧЃЌНЋЖрИіЪ§ОндДЪЕР§ЛуМЏЕНФПБъЖЫНјааИДдгЗжЮіЁЂЙиСЊВщбЏЕШ
АЂРядЦдЦдЩњЪ§ОнВжПтAnalyticDB MySQLЛљгкКўВжвЛЬхМмЙЙДђдьЃЌИпЖШМцШнMySQLЃЌКСУыМЖИќаТЃЌбЧУыМЖВщбЏЃЌПЩвдЭЌЪБЬсЙЉИпЭЬЭТРыЯпДІРэКЭИпадФмдкЯпЗжЮіЁЃ
еыЖддкAnalyticDB MySQLжаЗжЮіPolarDBЕФЪ§ОнЃЌЮвУЧЬсЙЉвдЯТСНжжZero-ETLЙІФмЁЃ
- СЊАюЗжЮіЃКЭЈЙ§ИУЙІФмПЩвдУтЗбНЋPolarDB MySQLЕФЪ§ОнЪЕЪБЭЌВНЕНAnalyticDB MySQLжаЃЌжЛашвЊМђЕЅХфжУдДЖЫКЭФПБъЖЫЃЌБуПЩЭъГЩЭЌВНШЮЮёЕФЙЙНЈЃЌгУЛЇЮоашЖюЭтдйЮЌЛЄЦфЫћЕФЪ§ОнЭЌВНСДТЗЃЛЪ§ОнНјШыAnalyticDB MySQLКѓПЩвджБНггУADB SparkЛђXIHEМЦЫув§ЧцНјааВщбЏКЭЗжЮі

- дЊЪ§ОнздЖЏЭЌВНЃКЭЈЙ§ИУЙІФмЃЌгУЛЇдкPolarDB-XжаПЊЦєСаДцБэКѓЃЌПЩвдздЖЏНЋСаДцБэЕФдЊЪ§ОнЭЌВНЕНAnalyticDB MySQLжаЃЌСЂМДдкADBжаЗжЮіPolarDB-XжаЕФЪ§ОнЃЌВЂПЩНЋPolarDB-XжаЕФБэКЭЦфЫћЪ§ОндДЕФБэНјааЙиСЊВщбЏЗжЮіЁЃ

ШчКЮЪЙгУАЂРядЦбўГиЪ§ОнПтZero-ETLЗўЮё
PolarDB MySQLСЊАюЗжЮі
PolarDB MySQLИХРРвГ-ЁИСЊАюЗжЮіЁЙНјШыИУЙІФм
- аТНЈСЊАюЗжЮіСДТЗЃКбЁдёдДЖЫЪЕР§КЭФПБъЖЫЪЕР§ЃЌФЌШЯЭЌВНећЪЕР§ЃЌДђПЊЁИИпМЖХфжУЁЙКѓПЩвдбЁдёПтБэЖдЯѓЃЌвВПЩвдЖдДѓБэНјааЗжЧјМќЩшжУЁЃ


- БрМСДТЗЁЂВщПДСДТЗЃКжЇГжаоИФПтБэЖдЯѓЕШЃЌжЇГжВщПДСЊАюЗжЮіШЮЮёЕФХфжУЯъЧщ

PolarDB-X дЊЪ§ОнздЖЏЗЂЯж
PolarDB-X 2.0ПижЦЬЈ-ЁИСаДцв§ЧцЁЙвГУцНјШыИУЙІФм
- ЁИСаДцв§ЧцЁЙвГУцЃЌДДНЈСаДцв§ЧцЃЌВЂЁИПЊЭЈADBКўВжЁЙЃЌДЫДІПЩбЁдёЭЌЕигђЯТЕФвбгаЪЕР§


- ЭъГЩПЊЭЈЃЌдкФПБъЖЫAnalyticDB MySQLЪЕР§жа-ЁИЪ§ОнНгШыЁЙ-ЁИдЊЪ§ОнЗЂЯжЁЙжаЛсздЖЏДДНЈдЊЪ§ОнЭЌВНШЮЮёЃЛВЂПЩЭЈЙ§ЁИSQLПЊЗЂЁЙЁЂDMSЛђЦфЫћПЭЛЇЖЫЙЄОпЃЌдкЪЕР§жаЖддДЖЫPolarDB-XСаДцБэНјааВщбЏЗжЮіЁЃ

Zero-ETLгХЪЦ
АЂРядЦбўГиЪ§ОнПтZero-ETLжМдкЪЕЯжЪТЮёДІРэКЭЪ§ОнЗжЮівЛЬхЛЏЃЌЪЕЯжНЈВжГЩБОЕФНЕЕЭЃЌНЈВжаЇТЪЕФЬсЩ§ЁЃ
ФПЧАЪЙгУZero-ETLЗНАИКЭДЋЭГЕФЪ§ОнЭЌВНСДТЗЗНАИЖдБШРДПДЃЌСДТЗГЩБОПЩЯТНЕ30%ЃЌЙЙНЈЪ§ОнВжПтЕФаЇТЪПЩЬсЩ§60%ЁЃ
змНсРДПДЃЌZero-ETLЕФгХЪЦШчЯТЃК
СуГЩБОЃКЬсЙЉЕЭГЩБОЕФЪ§ОнНгШыСДТЗЃЌгУЛЇПЩУтЗбЛђМЋЕЭГЩБОЪЕЯждкAnalyticDBжаЖдЩЯгЮPolarDBЪ§ОнНјааЗжЮі
взгУадКУЃКЮоашДДНЈКЭЮЌЛЄжДааETLЃЈЬсШЁЁЂзЊЛЛЁЂМгдиВйзїЃЉЕФИДдгЪ§ОнЙмЕРЃЌНіашбЁдёдДЖЫЪ§ОнКЭФПБъЖЫЪЕР§ЃЌздЖЏДДНЈЪЕЪБЪ§ОнЭЌВНСДТЗЃЌМѕЩйЙЙНЈКЭЙмРэЪ§ОнЙмЕРЫљДјРДЕФЬєеНЃЌзЈзЂЩЯВугІгУПЊЗЂ
ЖрдДЛуМЏЃКZero-ETLЕФФПБъЖЫПЩвдЬсЙЉШЋОжЪгНЧЃЌНЋЖрИіЪ§ОндДЪЕР§ЛуМЏЕНФПБъЖЫНјааИДдгЗжЮіЁЂЙиСЊВщбЏЕШ