概述
Snapchat是一款流行的社交媒体应用,它允许用户发送和接收带有滤镜和贴纸的照片和视频,以及创建和观看故事和发现内容。Snapchat的数据是非常有价值的,因为它可以反映用户的行为、偏好和趋势。然而,Snapchat的数据并不容易获取,因为它的网站是动态的,而且有反爬虫的机制。那么,我们如何用R语言来爬取和分析Snapchat的数据呢?本文将介绍一种利用R的jsonlite库来解析和处理Snapchat的数据的方法,以及如何使用代理IP技术来绕过Snapchat的反爬虫的策略。
正文
什么是jsonlite库?
jsonlite是一个R包,它可以将JSON数据转换为R对象,或者将R对象转换为JSON数据。JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,它可以用来存储和传输结构化的数据。JSON数据的基本单位是键值对,它们可以组成对象、数组、字符串、数字、布尔值或空值。JSON数据的优点是它易于阅读和编写,而且可以被多种编程语言解析和生成。
为什么要用jsonlite库来爬取Snapchat的数据?
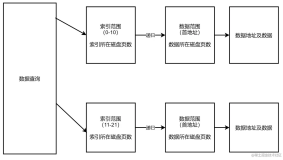
Snapchat的网站是动态的,也就是说,它的内容是根据用户的交互和请求而实时生成的。这意味着,我们不能用传统的网页爬虫来直接获取Snapchat的网页源代码,因为它们并不包含我们想要的数据。然而,我们可以通过分析Snapchat的网页请求,找到其中包含数据的部分,也就是JSON数据。Snapchat的网页请求是通过XHR(XMLHttpRequest)技术来实现的,它可以在不刷新网页的情况下,向服务器发送和接收数据。我们可以用浏览器的开发者工具(如Chrome的F12)来查看Snapchat的网页请求,找到我们感兴趣的JSON数据的URL,然后用R的jsonlite库来解析和处理这些数据。
如何用jsonlite库来爬取Snapchat的数据?
我们以Snapchat的发现页面为例,来演示如何用jsonlite库来爬取Snapchat的数据。Snapchat的发现页面是一个展示各种内容的平台,包括新闻、娱乐、体育、生活等。我们可以用以下的步骤来获取Snapchat的发现页面的数据:
1. 准备工作:
在开始之前,确保已经安装好R语言、jsonlite库以及必要的依赖。如果还未安装,可以通过以下命令进行安装:
install.packages("jsonlite")
install.packages("httr")
2. 设置爬虫代理IP:
为保护自身隐私,以及绕过网站的反爬机制,我们将使用代理IP技术。以下是代码示例,使用爬虫代理的域名、端口、用户名、密码,加上中文注释:
# 设置亿牛云 爬虫代理加强版 代理服务器
proxy_host <- "ip.16yun.cn"
proxy_port <- 31111
proxy_user <- "YourUsername"
proxy_pass <- "YourPassword"
3. 发送POST请求:
利用R语言的httr库,我们创建一个POST请求的函数,用于向www.snapchat.com发送请求。这里我们设置了用户代理信息和代理服务器信息:
# 创建一个POST请求
post_request <- function(url, data, proxy_host, proxy_port, proxy_user, proxy_pass) {
req <- httr::POST(url, httr::add_headers(
'User-Agent' = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
), httr::set_proxy(proxy_host, proxy_port, username = proxy_user, password = proxy_pass))
if (length(data)) {
req <- httr::add_params(req, data)
}
return(req)
}
4. 发送请求并解析JSON响应:
通过发送POST请求,我们获取www.snapchat.com的JSON响应,并使用jsonlite库解析数据:
# 发送POST请求
response <- post_request("https://www.snapchat.com/", list(), proxy_host, proxy_port, proxy_user, proxy_pass)
# 解析JSON响应
json_data <- jsonlite::fromJSON(response$content)
结语:
通过本文的探讨,我们深入了解了如何使用R语言和jsonlite库进行高效的www.snapchat.com数据爬取。同时,借助代理IP技术,我们实现了匿名性和反爬的绕过,确保了数据采集的成功。这篇文章为读者提供了实用而专业的指导,希望读者在技术之旅中能够不断突破边界,探索更广阔的数据领域。