БОЦЊЮФеТЮЇШЦЩњГЩЪНAIММЪѕеЛЁЂЩњГЩЪНAIЮЂЕїбЕСЗКЭадФмЗжЮіЁЂECS GPUЪЕР§ЮЊЩњГЩЪНAIЬсЙЉЫуСІБЃеЯЁЂгІгУГЁОААИР§ЕШЯрЙиЛАЬтеЙПЊЁЃ
вЛЁЂЩњГЩЪНAIММЪѕеЛНщЩм
1ЁЂЩњГЩЪНAIБЌЗЂЕФРњГЬ
дк2022ФъЕФЯТАыФъЃЌвЕНчгРДСЫЩњГЩЪНAIЕФШЋУцБЌЗЂЃЌгШЦфЪЧвдChatGPTЮЊДњБэЕФДѓгябдФЃаЭКЭвдStable DiffusionЮЊДњБэЕФЭМЦЌЩњГЩРрФЃаЭЁЃОйИіР§згЃЌФГгзЖљдАРЯЪІвЊЧѓМвГЄаДвЛЦЊ1500зжЕФЙигкМвЭЅНЬг§ЗЈЕФаФЕУЬхЛсЃЌChatGPTПЩвдЪЄШЮетЗнЙЄзїЃЛИїжжlogoвВПЩвдЭЈЙ§Stable DiffusionЩњГЩЪНФЃаЭРДЩњГЩЃЌИљОнЬсЪОДЪЩњГЩИїРрЭМЦЌЁЃ
ЃЈ1ЃЉШэМўЫуЗЈВПЗж
ЩњГЩЪНAIЕФБЌЗЂГЙЕзЭЛЦЦСЫЙ§ЭљЖдAIгІгУЕФЯыЯѓПеМфЃЌЕЋДгШэМўКЭЫуЗЈНЧЖШЃЌЩњГЩЪНAIЕФШЋУцБЌЗЂВЂЗЧвЛѕэЖјОЭЃЌЫќЪЧНќШ§ЫФЪЎФъЫљгабаЗЂШЫдБЁЂЫуЗЈЙЄГЬЪІвдМАПЦбаШЫдБЕФХЌСІЃЌЙВЭЌДйГЩСЫЕБНёЩњГЩЪНAIЕФБЌЗЂЁЃ
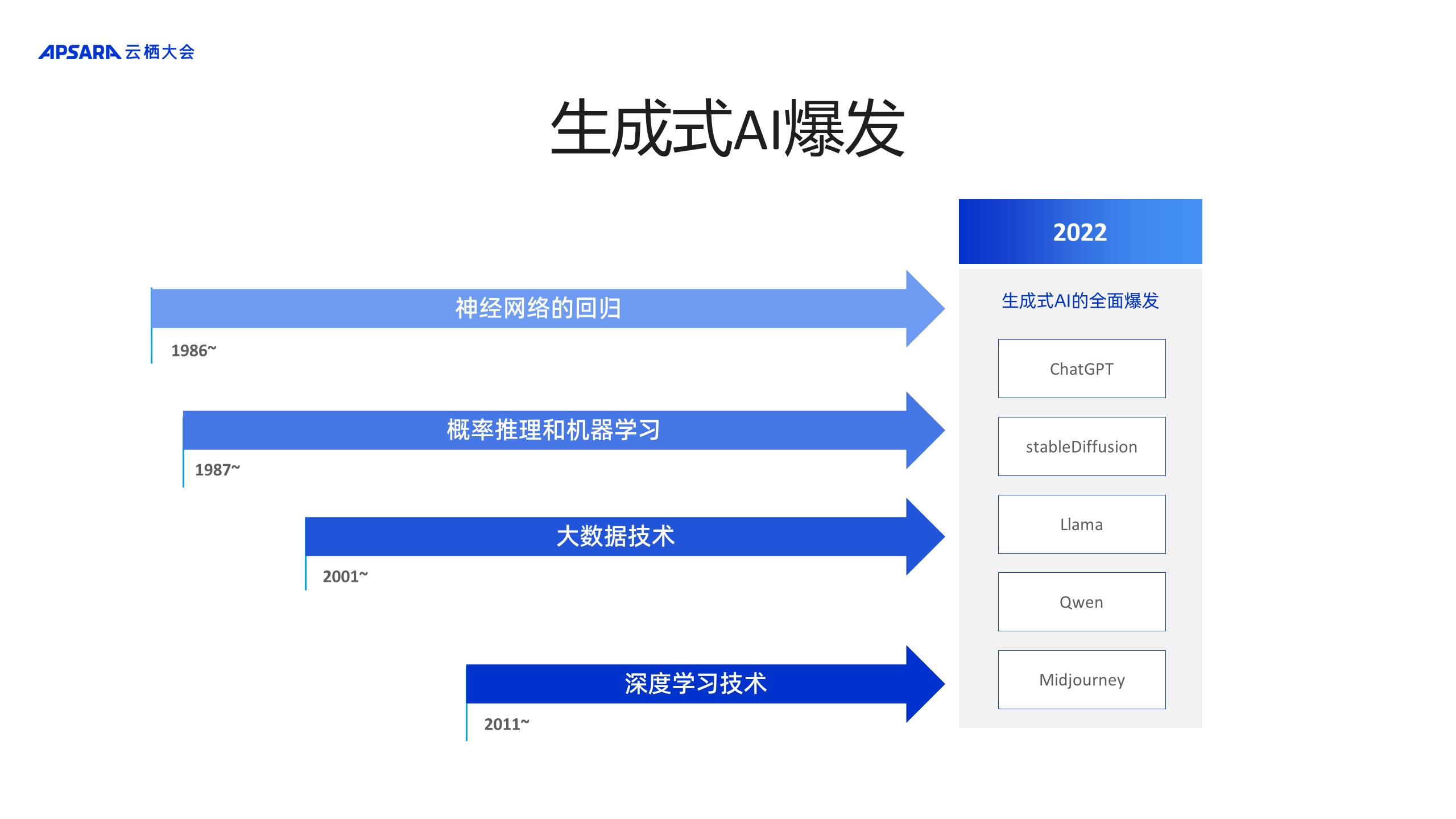
1986ФъЃЌЩЯЪРМЭСљЦпЪЎФъДњБЛХзЦњЕФЩёОЭјТчжиаТЛиЙщжїСїбаОПСьгђЁЃ1987ФъЃЌИХТЪЭЦРэКЭЛњЦїбЇЯАЫуЗЈв§ШыЃЌНЋВЛШЗЖЈадЕФЪ§бЇНЈФЃвдМАЫцЛњЬнЖШЯТНЕЕФбЇЯАЫуЗЈв§ШыЕНШЫЙЄжЧФмЕФжїСїЫуЗЈбаОПСьгђЁЃ
21ЪРМЭГѕЃЌЫцзХЛЅСЊЭјЕФБЌеЈЪНЗЂеЙЃЌДѓЪ§ОнММЪѕБЛв§ШыЕНИїИіСьгђЃЌАќРЈЩњВњЁЂЗжЮівдМАШЫЙЄжЧФмЁЃНќЪЎФъЃЌЩюЖШбЇЯАММЪѕгШЦфЛ№ШШЃЌМДЭЈЙ§ЖрВуИажЊЭјТчЖбЕўРДЬсЩ§ФЃаЭЗКЛЏОЋЖШЁЃетаЉЫуЗЈЛљДЁЩшЪЉЕФВЛЖЯбнНјЃЌДйГЩСЫЩњГЩЪНAIБЌЗЂЁЃ
ЃЈ2ЃЉгВМўВПЗж
гВМўВПЗжвВЪЧДйГЩЕБЧАЩњДцЪНAIБЌЗЂЕФживЊЛљДЁЁЃШчШЫЙЄжЧФмСьгђЃЌЮвУЧЭЈГЃЯВЛЖКЭШЫРрДѓФдНјааРрБШЃЌШЫФддМга1011ИіЩёОдЊЃЌЩёОдЊжЎМфга1010 ИіЭЛДЅЃЌЯрЕБгкПЩвдДяЕНУПУыжг1017ЕФЫуСІЃЌдМЮЊ0.1 EFLOPSЁЃИіШЫМЦЫуЛњФПЧАЛЙДяВЛЕНШЫФдЕФЫуСІЃЌGPUМЏШКЕФМЦЫуФмСІвбОГЌЙ§СЫШЫРрДѓФдЕФЫуСІЃЌЯШНјЕФGPUМЦЫуМЏШКвбОПЩвдДяЕНEFLOPSЕФМЖБ№ЁЃвђДЫЃЌЫуСІвВЪЧФПЧАЩњГЩЪНAIЕФживЊгВМўБЃеЯЁЃ

ЩЯЭМжаеЙЪОСЫФПЧАзюЕфаЭЕФGPU 3ФЃаЭЕФДѓжТЭЦЫуЃЌзнзјБъPetaflop/s-DaysБэЪОвЊдквЛЬьжЎФкбЕСЗвЛИіФЃаЭЃЌЫуСІашвЊДяЕНЕФPetaflop/sЁЃGPT 3ЕФСПМЖдМЮЊ10ЕФ4ДЮЗНЕФPetaflop/s-DaysЃЌШчЙћЪЙгУЧЇПЈЕФA100зщГЩМЏШКЃЌДѓжТашвЊвЛИідТЕФЪБМфбЕСЗЭъGPT 3ЕФдЄбЕСЗФЃаЭЁЃ
2ЁЂЩњГЩЪНAIбЕСЗММЪѕеЛ
змНсРДЫЕЃЌЪЧгЩгкФЃаЭНсЙЙЕФДДаТЃЌгШЦфвд2017ФъПЊЪМTransformerФЃаЭНсЙЙЮЊДњБэЃЛСэЭтДѓЪ§ОнДјРДСЫКЃСПЕФЪ§ОнМЏЃЌЛЙАќРЈЛњЦїбЇЯАЕФЬнЖШбАгХЫуЗЈНсЙЙЃЌЙВЭЌЙЙГЩСЫAIбЕСЗЫуЗЈКЭШэМўЩЯЕФЛљДЁЁЃСэЭтЃЌДгGPUЕФдЦЗўЮёЦїЕНGPUЕФдЦЗўЮёМЏШКЃЌЙЙГЩСЫAIбЕСЗЕФгВМўЛљДЁЁЃ

ШэМўЫуЗЈгыгВМўЗЂеЙДјРДСЫЕБЯТЩњГЩЪНAIбЕСЗММЪѕеЛБЌЗЂЃЌДјРДСЫЭЈЭљAGIЕФЪяЙтЁЃ
ЖўЁЂЩњГЩЪНAIЮЂЕїбЕСЗКЭадФмЗжЮі
ЕкЖўВПЗжЃЌЮвНЋНщЩмФПЧАдкЩњГЩЪНAIЕФЮЂЕїбЕСЗГЁОАЯТЕФСїГЬЁЂЪЙгУГЁОАвдМАЛљгкECS GPUдЦЗўЮёЦїЃЌЩњДцЪНAIЮЂЕїбЕСЗГЁОАЕФадФмЗжЮіЁЃ
1ЁЂЩњГЩЪНAIДгПЊЗЂЕНВПЪ№ЕФСїГЬ
ДѓжТПЩвдЗжЮЊШ§ВПЗжЁЊЁЊдЄбЕСЗЁЂЮЂЕїКЭЭЦРэЃЌШчЯТЭМЫљЪОЃК

зюзѓВрЪЧPre-TrainingЃЈдЄбЕСЗЃЉЃЌЩњГЩЭЈгУФЃаЭЃЌжаМфЪЧFine TuningЃЈЮЂЕїЃЉЃЌЩњГЩЬиЖЈСьгђЕФЪ§ОнМЏЃЌзюжедкВПЪ№ЪБЃЌНјааInferenceЭЦРэЁЃ
дкPre-TrainingНзЖЮЃЌзюживЊЕФЬиЕуЪЧгаКЃСПЕФЪ§ОнМЏвдМАДѓЕФВЮЪ§СПЃЌвђДЫИУГЁОАашвЊДѓЙцФЃЫуСІНјааЗжВМЪНбЕСЗЃЌЭЈГЃвддТЮЊЕЅЮЛЕФПЊЗЂжмЦкКЭЩњВњЕќДњЕФСїГЬЁЃ
дкFine TuningНзЖЮЃЌгыPre-TrainingТдгаЧјБ№ЃЌИУГЁОАЯТашвЊSpecial DataЃЌШчДЙжБСьгђФЃаЭЕФПЭЛЇзЈЪєЕФЫНгђЪ§ОнЁЃДЫЭтЃЌИљОнгІгУГЁОАашЧѓЃЌгааЉГЁОАПЩФмашдквЊЗжжгМЖFine TuningГівЛИіФЃаЭЃЌгааЉГЁОАПЩвдвджмЮЊЕЅЮЛЩњВњФЃаЭЃЌНјЖјАбPre-TrainingФЃаЭБфГЩspecializeЬиЖЈСьгђЕФФЃаЭЃЌШчcodingЁЂmedia adviseЁЂeducationЕШДЙРрЕФФЃаЭЁЃ
дкInferenceЭЦРэНзЖЮЃЌЦфЬиЕуИќМгУїЯдЃЌМДгУгкВПЪ№ЃЌзюЙиМќЪЧШчКЮдкЗћКЯЬиЖЈЕФдкЯпЗўЮёЛЗОГЯТзіЕНЪБбгКЭЭЬЭТЃЌвдДяЕНЩЯЯпашЧѓЁЃ
ЩњГЩЪНAIЮЂЕїбЕСЗГЁОАжаСНРрГЃМћЕФФЃаЭЃЌШчЩЯЭМЫљЪОЁЃ
ЕквЛРрЃЌШчУюбМЯрЛњAPPЃЌЫќЪЧЛљгкDiffusionЩњГЩРрФЃаЭЬсЙЉеыЖдПЭЛЇЖЈжЦЛЏзЈЪєФЃаЭЕФвЛжжбЕСЗЗНЪНЃЌЫќЪЧПьЫйFine TuningгыИпаЇInferenceМцЙЫЕФвЛжжбЕЭЦвЛЬхЕФЩњГЩЪНAIФЃаЭЁЃ
ЕкЖўРрЃЌДЙжБСьгђЕФДѓФЃаЭЃЌвдДѓгябдФЃаЭЮЊДњБэЃЌЫќИљОнЬиЖЈГЁОАвдМАЖдгІЕФДЙРрСьгђЕФЪ§ОнЃЌЛљгкЛљзљФЃаЭFine TuningЖЈжЦЛЏЕФLLMФЃаЭЁЃ
2ЁЂЩњГЩЪНAIЮЂЕїГЁОАЕФGPUадФмЗжЮі
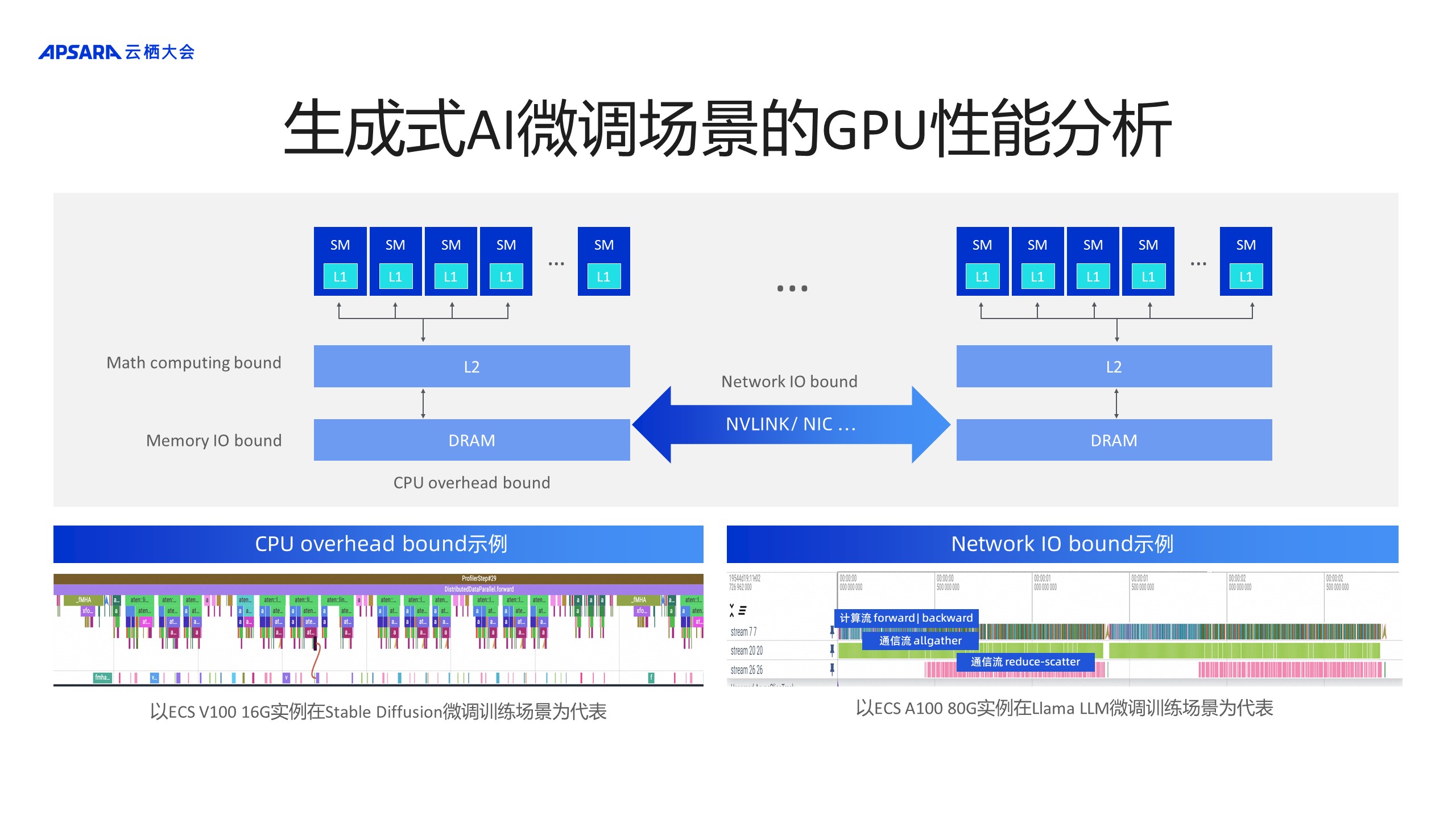
вдЩЯСНРрФЃаЭдкGPUМЦЫуЩЯДцдкЦПОБЁЃGPUЕФдРэВЂВЛИДдгЃЌМДвЛЖбаЁЕФMicroЕФМЦЫуЕЅдЊзіALUМЦЫуЃЌКЭаЁПщОиеѓГЫЗЈЁЃЕЋФЃаЭЛђЩюЖШбЇЯАЫуЗЈВЂВЛЪЧМђЕЅЕигЩОиеѓГЫзщГЩЃЌАќРЈtransform layerЕШЖдгІЕФactivationЕШЃЌШчКЮНЋЖбЕўЕФlayerгГЩфЕНЫуСІзЪдДЃЌИќКУЕиЗЂЛгГіЫуСІЕФefficiencyЪЧЮвУЧашвЊНтОіЕФГЁОАЁЃ
ОпЬхЕНЩњГЩЪНAIЕФЮЂЕїГЁОАЃЌЩЯЭМЕФзюЯТЗНСаСЫСНеХTimelineЭМЃЌзѓЯТНЧЪЧвдECS V100 16GЪЕР§дкStable DiffusionЮЂЕїбЕСЗГЁОАЮЊДњБэЃЌПЩвдПДЕНGPUМЦЫуТпМЪБМфађСагаКмЖрПеАзЃЌЫЕУїGPUЕФЫуСІУЛгаБЛЭъШЋЗЂЛгГіРДЃЌЦфзюживЊЕФЦПОБРДздгкCPUБОЩэЕФoverheadЬиБ№ДѓЃЌетЪЧv100ГЁОАЯТдкStable DiffusionЮЂЕїгіЕНЕФЦПОБЁЃ
гвЯТНЧECS A100 80GЪЕР§дкLlama LLMЮЂЕїбЕСЗГЁОАЮЊДњБэЃЌзюЩЯУцвЛВуЪЧдкGPUЩЯЕФМЦЫужДааТпМЃЌЯТУцЪЧУмМЏЕФall gatherЭЈаХСїЃЌгжАщЫцзХУмМЏЕФ Reduce scatterЭЈаХСїЃЌЫќЪЧЭјТчIOГЩЮЊboundЕФМЦЫуworkloadЁЃ
гГЩфЕНЫуСІзЪдДЃЌCPU overhead boundКЭNetwork IO boundГЩЮЊСЫGPUдЫЫуЕФЦПОБЁЃ
Ш§ЁЂECS GPUЪЕР§ЮЊЩњГЩЪНAIЬсЙЉЫуСІБЃеЯ
ECS GPUдЦЗўЮёЦїЭЈЙ§ШэгВМўНсКЯЕФЗНЪНЃЌЮЊЩњГЩЪНAIЕФЮЂЕїГЁОАЬсЙЉСЫГфХцЁЂИпадФмЕФЫуСІБЃеЯЁЃ
1ЁЂECS вьЙЙМЦЫуЮЊЩњГЩЪНAIЬсЙЉХьХШЫуСІ
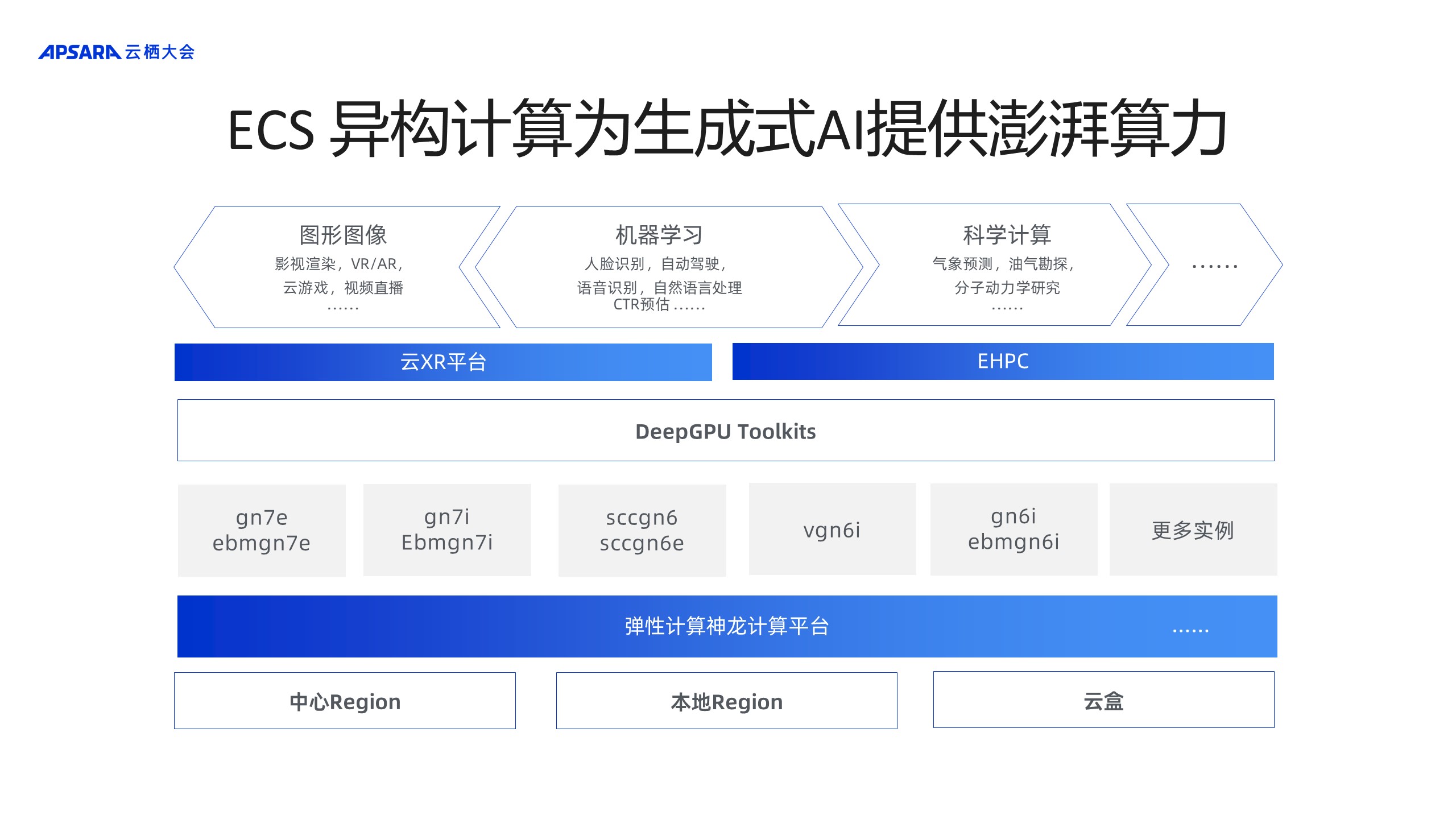
ЯТУцЪЧАЂРядЦвьЙЙМЦЫуВњЦЗДѓЭМЁЃЕззљЪЧECSЕФЩёСњМЦЫуЦНЬЈЃЌжЎЩЯЬсЙЉСЫАќРЈgn7eЁЂgn7iвдМАЦфЫћзіМЦЫуМгЫйЪЕР§ЕФгВМўзЪдДзщЁЃдкЫуСІЕФЛљДЁжЎЩЯЃЌЬсЙЉDeepGPU ToolkitsЃЌЦфФПБъдкгкЯЮНгЩЯВуAIгІгУКЭЕзВугВМўзЪдДЃЌНјааШэНсКЯвЛЬхЛЏЕФгХЛЏЃЌЬсЩ§ECS GPUдЦЗўЮёЦїгыгбЩЬЯрБШЕФВювьЛЏОКељСІЃЌЗўЮёгкПЭЛЇвдДяЕНИпадФмКЭИпадМлБШЕФAIбЕСЗКЭЭЦРэаЇЙћЁЃ
2ЁЂECS вьЙЙМЦЫуDeepGPUЬсЩ§ЩњГЩЪНAIаЇТЪ
вдЯТЪЧDeepGPUЕФМђЭМЁЃ
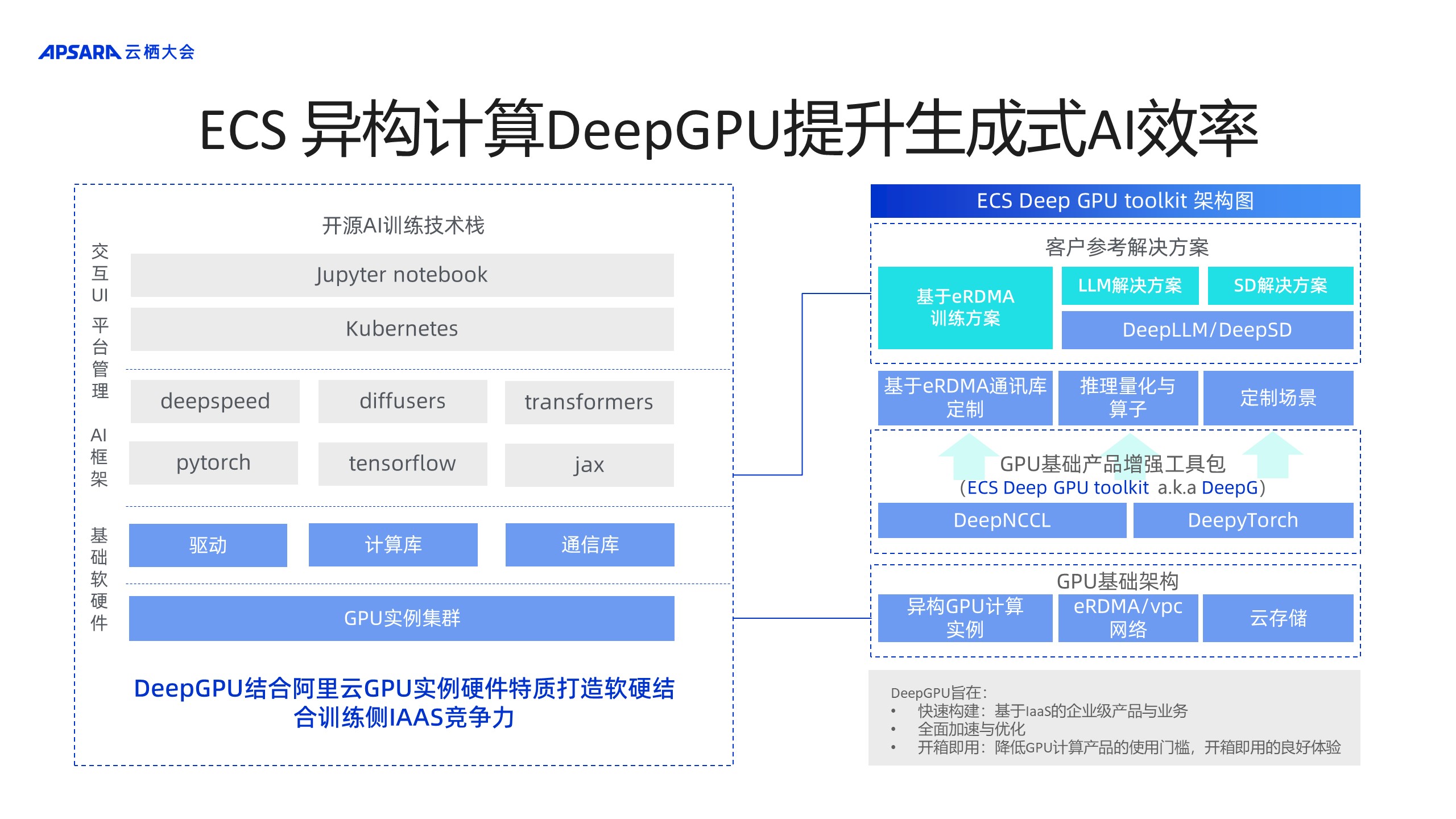
зѓВрЪЧПЊЗЂФЃаЭЕФбЕСЗММЪѕеЛЃЌЭЈГЃПЊЗЂШЫдБжЛЙизЂСНВПЗжЃЌЕквЛЃЌЪЧЗёФмЬсЙЉзуЙЛЕФЫуСІЗўЮёЃЌПЩвдЭЈЙ§ПЊдДЕФЕїЖШЦївдМАПЊдДЕФФЃаЭПђМмДюНЈФЃаЭЫуЗЈЕФПЊЗЂСїГЬЁЃDeepGPUЕФЙЄзїдђЪЧдкПЭЛЇВЂВЛДЅМАЕФВПЗжЃЌАќРЈЧ§ЖЏМЖЁЂМЦЫуПтКЭЭЈаХПтЃЌећКЯАќРЈCIPUЁЂECS GPUдЦЗўЮёЦїЕФФмСІЬсЩ§дкФЃаЭбЕСЗКЭЭЦРэЕФаЇЙћКЭФмСІЁЃ
гвВрЪЧDeepGPUЕФећЬхМмЙЙЭМЃЌЦфЕзВуЪЧвРЭагкGPUЕФЛљДЁМмЙЙЃЌАќРЈвьЙЙGPUМЦЫуЪЕР§ЁЂeRDMA/vpcЭјТчвдМАдЦДцДЂЃЌдкЛљДЁВњЦЗдіЧПЙЄОпАќжаЬсЙЉАќРЈЛљгкeRDMAбЕСЗЕФПЭЛЇВЮПМНтОіЗНАИЃЌзюжеЕФФПЕФЪЧАяжњПЭЛЇдкЛљгкECS GPUдЦЗўЮёЦїЩЯЃЌЦфФЃаЭЕФбЕСЗЭЦРэЕФадФмПЩвдДяЕНзюМбЁЃ
3ЁЂАЂРядЦCIPU + DeepGPUЬсЩ§ЗжВМЪНбЕСЗаЇТЪ
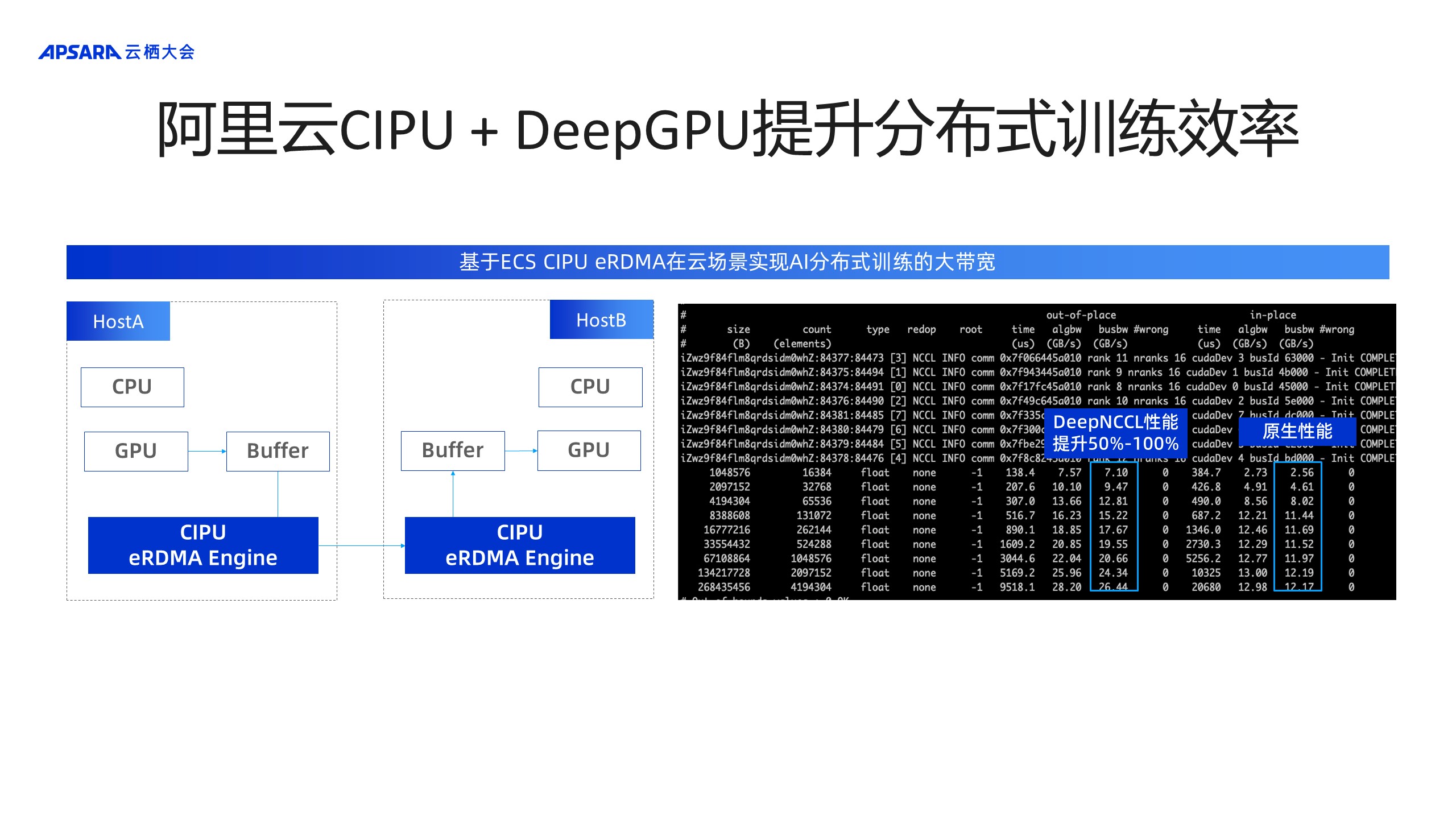
МђЕЅНщЩмDeepNCCLШчКЮЭЈЙ§АЂРядЦЬигаЕФЛљДЁЩшЪЉДяЕНШэгВНсКЯЕФбЕСЗМгЫйЕФаЇЙћЁЃзѓВрЭМЪЧCIPUЕФЛљДЁЩшЪЉЃЌЫќЬсЙЉСЫeRDMA EngineЃЌПЩвдДяЕНДѓЭЬЭТЁЂЕЭбгЪБЕФЭјТчЭЈаХЕФФмСІЃЌЕўМгDeepNCCLШэгВНсКЯЕФадФмгХЛЏЃЌгвЭМЯдЪОallgatherЕФNCCL testадФмЪ§ОнЃЌгвВрЪЧдЩњЕФЪ§ОнЃЌзѓВрЪЧDeepNCCLМгГжЕФадФмЪ§ОнЃЌDeepNCCLЪЕЯжСЫБШдЩњЪ§ОнЬсЩ§50%~100%ЕФprimitiveЕФNCCLМЏКЯЭЈаХЕФЫузггХЛЏФмСІЁЃ
ЫФЁЂгІгУГЁОААИР§
етВПЗжЭЈЙ§МИИіЕфаЭЕФГЁОАНщЩмECS GPUдЦЗўЮёЦїЕўМгDeepGPUдкЩњГЩЪНAIЕФгІгУГЁОАвдМАЖдгІЕФадФмМгЫйаЇЙћЁЃ
1ЁЂECS A10 DeepGPU DiffusionЮЂЕїбЕСЗАИР§

ЙигкDeepGPU DiffusionЮЂЕїЕФбЕСЗАИР§ЕФадФмМгЫйЗНАИЃЌЧАУцЕФФкШнжадјЬсМАЙ§ИУГЁОАЕФФПБъЃЌМДбЕЭЦвЛЬхЁЃЛЛбджЎЃЌПЭЛЇЪзДЮЛђЖўДЮНјШыЖМвЊПьЫйЩњГЩФЃаЭЃЌдђЦфбЕСЗвЛЖЈвЊПьЃЌвВОЭЪЧЫЕЦфдкФЃаЭЩЯгавЛЖЈЕФелжаЃЌШчЭЈЙ§LoRAНЕЕЭзмМЦЫуСПЃЛЦфДЮЃЌФЃаЭжаашвЊгазЈЪєгкУПИіПЭЛЇздМКЕФfeatureЃЌЭЈГЃЪЧдкDiffusionжаЭЈЙ§DreamboothЛђcontrolnetЬсЙЉзЈЪєФЃаЭЕФгХЛЏФмСІЁЃ
ЭЈЙ§ЫуЗЈЩЯЕФМгГжПЩвдаЮГЩгУЛЇзЈЪєФЃаЭЃЌСэЭтПЩвдБЃжЄПьЫйЁЃдйЕўМгgn7eЁЂgn7iЬсЙЉЕФИпЕЏадЫуСІБЃеЯЃЌПЩвдЬсЩ§ећИібЕЭЦвЛЬхЕФЫуСІашЧѓЃЌЭЌЪБDeepGPUШэгВНсКЯПЩвдЖюЭтДјРД15%~40%ЕФадФмЬсЩ§ЁЃРрЫЦЕФАИР§вбОдкПЭЛЇУюбМДѓЙцФЃЩЯЯпЃЌЭЈЙ§ПьЫйЕиЕЏГіДѓСПЕФA10ЁЂV100ЪЕР§вдМАDeepGPUЕФадФмМгГжЃЌАяжњУюбМПьЫйгІЖдИпЗхЦкгУЛЇЭЦРэКЭбЕСЗЕФЧыЧѓЁЃ
2ЁЂECS A100 DeepGPU LLM ЮЂЕїбЕСЗАИР§
СэвЛВПЗжЃЌдкДѓгябдФЃаЭЕФЮЂЕїбЕСЗАИР§ЃЌЦфЬиЕуЪЧФЃаЭВЮЪ§СПЬЋДѓЃЌдкЕЅЛњКмФбзАдибЕСЗЃЌвђДЫФЃаЭВЮЪ§ашвЊshardingЕНВЛЭЌЕФGPUПЈКЭВЛЭЌЕФЛњЦїЩЯзібЕСЗЫуЗЈЕФЕќДњЃЌетЛсв§ШыДѓСППЈМфЭЈаХЃЌЧвЪЧЭЌВНЭЈаХВйзїЃЌвђДЫЖрПЈЛЅСЊЕФФмСІЪЧLLMдкЮЂЕїбЕСЗГЁОАЕФЦПОБЁЃ

ECS GPUдЦЗўЮёЦїЬсЙЉАќРЈeRDMAвдМАДѓДјПэЕФЫуСІКЭЭЈаХДјПэБЃеЯЃЌдйЕўМгDeepGPUЕФDeepNCCLМгГжЃЌПЩвдЮЊДѓгябдФЃаЭдкЖрЛњЖрПЈЕФЮЂЕїГЁОАДјРД10%~80%ЕФадФмЬсЩ§ЁЃетИіАИР§вВдкаэЖрПЭЛЇГЁОАЩЯЕУЕНСЫЪЕМљЁЃ
вдЩЯОЭЪЧБОДЮЗжЯэЕФШЋВПФкШнЁЃ