БОЦЊЮФеТЮЇШЦЕЏадМЦЫуЭЦРэНтОіЗНАИDeepGPUЪЕР§ШчКЮжЇГжStable DiffusionЮФЩњЭМЭЦРэЁЂStable DiffusionЭЦРэбнЪОЪОР§ЕШЯрЙиЛАЬтеЙПЊЁЃ

едДѓДЈ АЂРядЦЕЏадМЦЫуИпМЖММЪѕзЈМв
вЛЁЂGPUдЦЗўЮёЦїЭЦРэНтОіЗНАИЕФЬсГіБГОА
ЫцзХAIGCЪБДњЕФЕНРДЃЌСНИіживЊгІгУгІдЫЖјЩњЃЌвЛИіЪЧвдStable Diffusion DALL-EЮЊДњБэЕФЮФЩњЭМЃЌСэвЛИіЪЧвдChatGPTКЭLlamaЮЊДњБэЕФЮФЩњЮФЁЃетСНИіГЁОАбИЫйЛ№БЌШЋЧђЃЌНќЦкВЩгУШкКЯФЃЪННЋСНИігІгУШкКЯдквЛЦ№ЕФГЁОАвбОГіЯжЃЌМДвдChatGPT + DALL-EЮЊДњБэЕФШкКЯЖрФЃЬЌФЃаЭЁЃдкетбљЕФЧїЪЦЯТЃЌШкКЯФЃаЭНЋГЩЮЊаТЕФдіГЄЕуЁЃ
2015ФъЃЌResnet50ЕФЕЎЩњЪЙЭМЯёЪЖБ№ДяЕНЗЧГЃИпЕФОГНчЁЃЪБжСНёШеЃЌИУФЃаЭвРШЛЛюдОдкжїСїbenchmarkЕФВтЪдМЏжаЁЃ
2018ФъЃЌЫцзХBert BaseЕФЕЎЩњЃЌИїжжгІгУГЁОАЖдЫуСІЕФашЧѓДяЕНСЫаТЕФИпЗхЃЌдкЕфаЭЧщПіЯТЃЌашвЊЪЎБЖгкResnet50ЕФЫуСІЁЃдкетжжДѓБГОАЯТЃЌдНРДдНЖрЕФвЕЮёдЫгЊЗНПЊЪМИаЪмЕНСЫОоДѓЫуСІашЧѓДјИјздЩэЕФдЫгЊбЙСІЃЌМЬЖјДйЪЙЫћУЧИќМгЛ§МЋЕибАЧѓадФмгХЛЏЕФНтОіЗНАИЁЃОнЪ§ОнЭГМЦЃЌАЂРядЦжЇГжЕФПЭЛЇГЁОАжаЃЌBert BaseЕФгХЛЏашЧѓГЌЙ§СЫвЛАыЁЃ
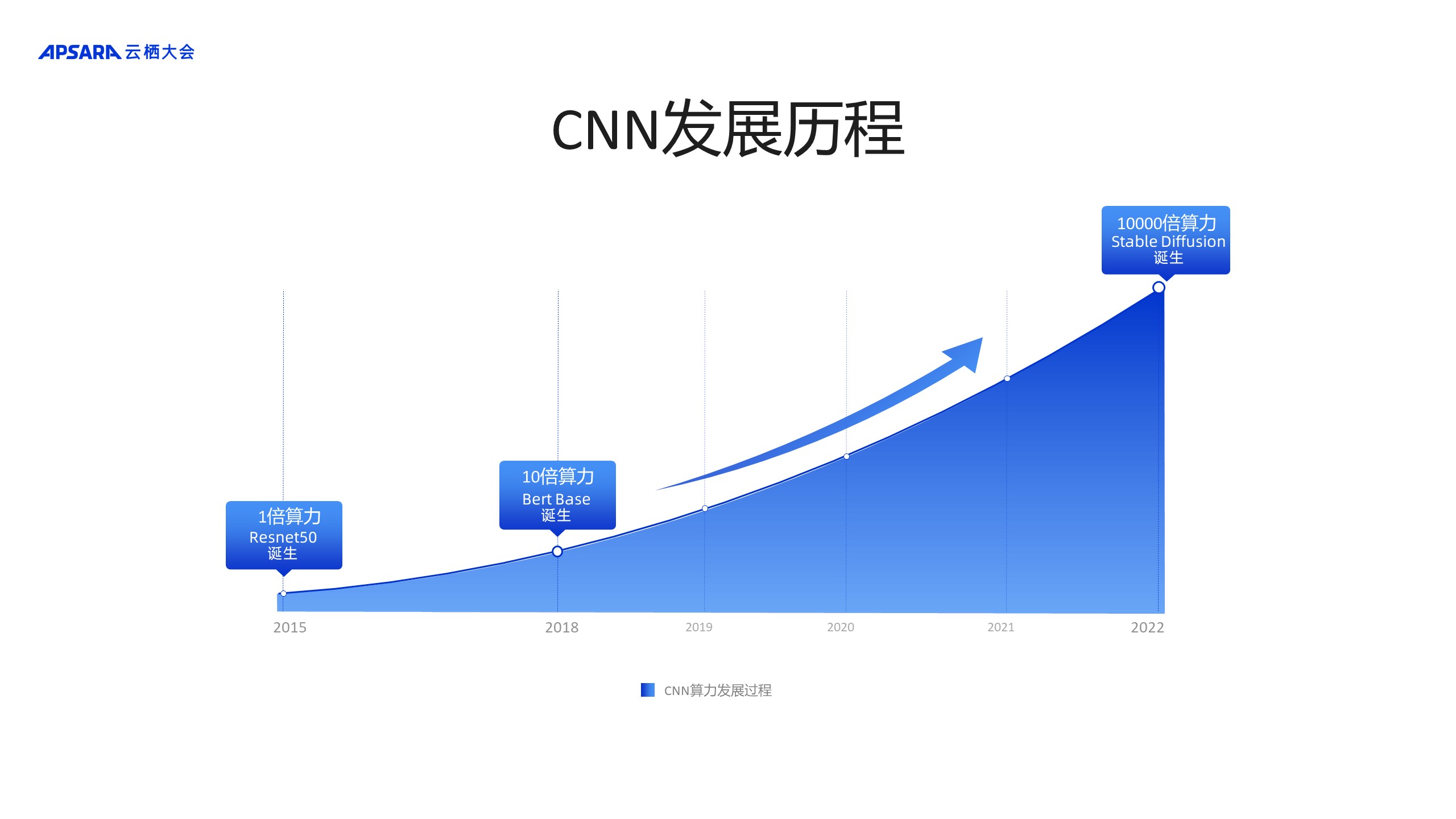
2022ФъЃЌStable DiffusionЮФЩњЭМвЛОЗЂВМБубИЫйЛ№БЌШЋЧђЃЌЫќДјРДЕФЫуСІашЧѓдіГЄОЊЪРКЇЫзЁЃЯрНЯгкResnet50ЃЌЫќЖдЫуСІЕФашЧѓСПдіГЄСЫдМ10000БЖЁЃ
ЯрНЯгкResnet50ЃЌBert BaseНіНіЪЧвЛИіЪ§СПМЖЕФЬсЩ§ЃЌБуШУвЕЮёдЫгЊЗНИаЪмЕНСЫОоДѓбЙСІЃЌЖјStable DiffusionЮФЩњЭМдкBert BaseЛљДЁЩЯгжЬсЩ§СЫШ§ИіЪ§СПМЖЕФЫуСІашЧѓЃЌетжжашЧѓЕФБфЛЏНЋЛсв§Ц№вЛГЁжиДѓЕФЫуСІЮЃЛњЁЃ
ЖўЁЂStable DiffusionЕЏадМЦЫуDeepGPUЪЕР§еќОШЮФЩњЭМЭЦРэ
дкЩЯУцЬсЕНЕФЫуСІашЧѓбИЫйРЉДѓЕФБГОАжЎЯТЃЌЕЏадМЦЫуGPUЪЕР§еыЖдЮФЩњЭМГЁОАНјааСЫЩюЖШгХЛЏЁЃ
ШчЯТЭМЫљЪОЃЌзюЕзВуЪЧGPUДЋЭГЕФгВМўЃЌШчGPUЁЂЭјТчЁЂДцДЂЕШЃЛдкетаЉгВМўжЎЩЯЪЧDeepGPUдіЧПЙЄОпАќЃЌЛљгкDeepGPUдіЧПЙЄОпАќПЩвдзюДѓЛЏЕиРћгУЕзВугВМўЕФадФмЃЌДгЖјИќКУЕижЇГХЩЯВугІгУЃЌАќРЈДѓгябдФЃаЭЁЂSDЕШНтОіЗНАИЁЃDeepGPUжївЊЪЧЮЊСЫАяжњПЭЛЇПьЫйЛљгкIaaSЙЙНЈЦѓвЕМЖгІгУЃЌЭЌЪБДѓЗљгХЛЏадФмЃЌНЕЕЭЪЙгУФбЖШЃЌзіЕНПЊЯфМДгУЃЌЬсЩ§гУЛЇЬхбщЁЃ

ЯТУцТоСаСЫвЛаЉдкЪлЕФЪЕР§ЙцИёЃКАќРЈРЯаЭКХШчT4ЁЂV100ЃЌвдМАAmpereМмЙЙЕФA100КЭA10ЁЃЛљгкAmpereМмЙЙЕФA100КЭA10ИќЪЪКЯStable DiffusionГЁОАЃЌдвђдкгкAmpereМмЙЙЬсЙЉЕФаТЕФЕзВугВМўЬиадФмЙЛКмКУЕиАяжњStable DiffusionЭЦРэЬсЩ§адФмЁЃ

ЯрЖдЖјбдЃЌA100дкStable Diffusion XL 1.0ЩЯЕФБэЯжИќМгЭЛГіЃЌЦфИљБОдвђЪЧдкгкStable Diffusion XL 1.0ЕФЫузгжївЊгЩМЦЫуУмМЏаЭзщГЩЃЌПЩвдГфЗжЗЂЛгA100ЕФЫуСІгХЪЦЁЃ
ЖјA10дђФмЙЛдкStable Diffusion 1.5ЩЯЬсЙЉНЯИпадМлБШЃЌЭЌЪБвВФмЖдStable Diffusion XL 1.0ЬсЙЉСМКУЕФжЇГжЁЃ
ЃЈ1ЃЉECS GPUЪЕР§ЛљгкDeepGPUЙЄОпАќдкSDЩЯЕФадФмБэЯж
ШчЯТЭМЫљЪОЃКзѓВрСНИіЭМБэЪЧГЃЙцадФмЕФЖдБШЃЌЩЯУцЪЧStable Diffusion 1.5ЃЌЯТУцЪЧStable Diffusion 2.1ЃЌећИіЦНЬЈЪЧдкA10ЕФGPUЩЯдЫааЃЌЯрБШНЯxformersЕФадФмдкВЛЭЌЕФЗжБцТЪЯТЬсЩ§СЫ60%~70%ЁЃ

гвЩЯЗНЕФБэИёжївЊТоСаСЫИїжжВЛЭЌГЁОАЃЌИќМгНгНќгкПЭЛЇецЪЕЕФЪЙгУЧщПіЃЌАќРЈвЛаЉБъзМВтЪдЁЂЖЏЬЌГпДчЃЌЛЙЕўМгСЫLORA + controlnetЕШЃЌЭЌЪБЛЙМадгвЛаЉФЃаЭЧаЛЛЃЌПЩвдПДЕНЛљгкВЛЭЌЕФГЁОАЃЌадФмЕФВювьНЯДѓЃЌзюЖрФмЬсЩ§МИБЖЃЌадФмЬсЩ§ЕФжївЊРДдДЪЧФЃаЭЧаЛЛЙ§ГЬжаЖдКФЪБЕФНкЪЁЁЃ
ЃЈ2ЃЉECS GPUЪЕР§ЕФПЭЛЇМлжЕ
ЯыШУПЭЛЇШЅНгЪмИУМгЫйЗНАИНігаадФмЬсЩ§ЪЧдЖдЖВЛЙЛЕФЁЃDeepGPUздЕЎЩњвдРДЃЌАќКЌSDЁЂLLMдкФквбгаЩЯАйИіПЭЛЇНјааЙ§ВтЪдЃЌФПЧАвбгаЪ§ЪЎИіПЭЛЇдкЯпЩЯЪЙгУDeepGPUМгЫйВњЦЗЁЃ
жЎЫљвдФмЙЛЛёЕУПЭЛЇЕФШЯПЩЃЌжївЊЕФдвђдкгкИУВњЦЗПЩвдАяжњПЭЛЇЛёЕУ7ДѓЪевцЃК
- ЬсЙЉSDФЃаЭадФмМгЫйЃЌЭъУРжЇГжЖЏЬЌГпДчгХЛЏЃЌЖјЖЏЬЌГпДчЪЧВЛЭЌПЭЛЇдкИїжжГЁОАЯТФмДяЕНдЫгЊФПБъЕФБиашЬѕМўЃЌВњЦЗЪЙгУЛЇЕФгІгУдкШЮвтЗжБцТЪЯТЖМПЩвдДяЕНМЋжТЕФадФмЫЎзМЃЛ
- LORAМгЫйадФмЮоЫ№ЁЃ
- жЇГжШЋФЃЪН controlnetМгЫйЁЃ
- SDЁЂLORAКЭcontrolnetФЃаЭЮоИаЧаЛЛЁЃЫцзХФЃаЭЕФЙцФЃдНРДдНДѓЃЌЪ§ОнзмСПМБОчЩЯЩ§ЃЌДцДЂЕФГЩБОвВЪЧПЭЛЇвЊПМТЧЕФжижажЎжиЁЃDeepGPUПЩвдЭЈЙ§ЛКДцНЕЕЭДцДЂЖСШЁбгЪБЃЌЖдГЃМћЕФSDЁЂLORAЁЂ controlnetФЃаЭНјааЮоИаЕФЧаЛЛЁЃ
- ШЋЭјЕФЭМгХЛЏЁЃЭМгХЛЏЪЧЖдФЃаЭНјаазюДѓГЬЖШгХЛЏЕФгааЇЗНЪНЃЌЕЋЦфашвЊАщЫцФЃаЭБрвыЕФЙ§ГЬЃЌИУЙ§ГЬЭљЭљЛсБШНЯКФЪБЁЃФПЧАЃЌDeepGPUПЩвддкУтБрвыЕФЧАЬсЯТЃЌЪЕЯжШЋЭјЕФЭМгХЛЏЃЌДгЖјДяЕНадФмЕФзюДѓЛЏЁЃ
- ФмЖдЖрИіФЃаЭНјааИпаЇЕФЙмРэЁЃ
- DeepGPUдкПЭЛЇЪЪХфЙ§ГЬжаЃЌЖдПЭЛЇЕФДњТывдМАФЃаЭЮоШЮКЮЧжШыадЁЃ
ЃЈ3ЃЉStable Diffusion XLМЋЫйЭЦРэ
Stable Diffusion XLзЈЮЊИпЧхЭМЦЌЩњГЩЖјЩњЃЌЫќФмЙЛЬсЙЉИќЖрЕФЭМЯёЩњГЩЯИНкКЭИќИпЕФЛжЪЃЌЪЧЖдSDЕФжиДѓИФНјЃЌвВЪЧвЕНчЩњГЩЭМЕФживЊЗЂеЙЧїЪЦЁЃадФмЖдБШМћвдЯТСНИіЭМБэЃК

зѓБпЪЧA100ЃЌгвБпЪЧA10ЃЌдкЗжБцТЪНЯДѓЕФЧщПіЯТЃЌDeepGPUЯрЖдxformersПЩЬсЙЉ60%-70%ЕФадФмЬсЩ§ЃЌЖјдкЗжБцТЪНЯаЁЕФЧщПіЯТЃЌадФмгХЪЦЛсИќДѓЃЌДяЕН1БЖЩѕжС2БЖЖрЁЃгЩДЫПЩвдПДГіЃЌxformersдкаЁЗжБцТЪЩЯЕФжЇГжНЯШѕЁЃЭЌЪБПЩвдПДГіA100дкИпЗжБцТЪЯТЕФгХЪЦЗЧГЃУїЯдЁЃ
A100дкИпЗжБцТЪЯТгХЪЦУїЯдЃЌжївЊдвђгаСНИіЃЌЦфвЛЃЌA100ЕФЫуСІКмЧПЃЌИпЗжБцТЪгажњгкA100ЗЂЛгЫуСІгХЪЦЃЛЦфЖўЃЌA100ХфБИЗЧГЃДѓЕФЯдДцЃЌПЩвдЖдИпЗжБцТЪЯТОоДѓЕФЯдДцашЧѓЬсЙЉСМКУЕФжЇГжЃЌПЩвдПДЕНдк2048ЗжБцТЪЯТЃЌA100ЕФадФмЪЧA10ЕФНќ3БЖЁЃ
Г§ДЫжЎЭтЃЌЖдвЕНчжїСїНгПкЕФЭъећжЇГжвВЪЧЗЧГЃживЊЕФвЛЯюЃЌФПЧАECS GPUжЇГжЕФжїСїНгПкАќРЈdiffusersЃЌwebUIЃЌcomfyUIЃЌвдТњзуВЛЭЌПЭЛЇЕФашЧѓЁЃ
Ш§ЁЂStable DiffusionЭЦРэбнЪОЪОР§
НгЯТРДЭЈЙ§ЪЕР§бнЪОРДИќжБЙлЕиЬхбщдкDeepGPUМгГжЯТЃЌSDЕФЭЦРэЙ§ГЬЃЌШчЯТЭМЃКетРяИјГіСЫ5ИіВЛЭЌЕФГЁОАЃЌЗжБ№ЖдгІН№зжЫўЕФ5ИіВуМЖЃЌдННгНќгкЫўМтЃЌЖдЫуСІвдМАЯдДцЕФашЧѓдНПСПЬЁЃ

1ЁЂЛљгкA100 SD1.5 512x512 50stepЕФгІгУГЁОА
етЪЧвЛИіЗЧГЃГЃМћЕФБъзМВтЪдГЁОАЃЌЭЈЙ§ЪЕМЪдЫааЃЌЗЂЯжЦфдЫааЪБМфЗЧГЃЖЬЃЌDeepGPUдк0.88УыНсЪјСЫећИіЙ§ГЬЃЌxformersНєЫцЦфКѓЃЌгУЪБ2.27УыЃЌадФмЬсЩ§ДѓдМЮЊ1.5БЖЁЃ
2ЁЂЛљгкA100 SD1.5 + controlnet + LORA 1024x1024 50stepГЁОА
ВтЪдЪБМфИќГЄЃЌЭЈЙ§ВтЪдПЩвдЗЂЯжDeepGPUвЛТЗСьЯШЃЌдк5.31УыТЪЯШЭъГЩећИіЭЦРэЙ§ГЬЃЌxformersЛЈЗб9.70УыЃЌадФмЬсЩ§дМ80%ЁЃ
3ЁЂЛљгкA100 SDXL base 1024x1024 50stepГЁОА
етЪЧStabilityAIНёФъзюживЊЕФФЃаЭИќаТЃЌЛљгкБъзМЕФSDXLВтЪдЁЃЭЈЙ§ВтЪдЗЂЯжЃЌDeepGPUгыxformersЖдБШМгЫйУїЯдЃЌDeepGPU 3.96УыЭъГЩВтЪдЃЌxformersЛЈЗб7.07УыЃЌадФмЬсЩ§дМ70%ЁЃ
4ЁЂЛљгкA100 SDXL base 2048x2048 50stepГЁОА
ЖдВтЪдНјааМгТыЃЌЭЈЙ§ВтЪдПЩвдЗЂЯжЃЌЫцзХЗжБцТЪЕФЬсЩ§ЃЌЭЦРэЕФЪБМфДѓЗљдіГЄЃЌDeepGPUЕФКФЪБЪЧ18.78УыЃЌxformersЭъГЩЭЦРэЕФЪБМфЪЧ32.8УыЃЌадФмЬсЩ§дМЮЊ70%ЁЃ
5ЁЂЛљгкA100 SDXL base + refiner + controlnet + LORA 2048x2048 50stepГЁОА
ВтЪдФбЖШГжајХЪЩ§ЃЌдкИУХфжУЯТЃЌЖдЫуСІКЭЯдДцЕФашЧѓМЋИпЃЌA100дкИУХфжУЯТЗЂЛгСЫЦфгВМўгХЪЦЃЌдкМгГжСЫDeepGPUжЎКѓадФмвЃвЃСьЯШЃЌDeepGPUгУЪБ26.56УыЃЌxformersгУЪБ46.06УыЃЌдкетвЛГЁОАЯТЃЌгУЛЇУїЯдЬхбщЕНСЫадФмжЪЕФЗЩдОЃЌадФмЬсЩ§дМ70%ЁЃ
ЙигкA10ЕФжїЪлЛњаЭадФмЖдБШЃЌПЩвддкАЂРядЦМЦЫуГВЭъГЩA10дкЮхжжВтЪдГЁОАЕФЖдБШЁЃ
вдЯТеЙЪОЕФЪЧАЂРядЦФПЧАЪЙгУDeepGPUНјааЭЦРэЕФВПЗжКЯзїЛяАщЁЃ

ДЫЭтЃЌГ§СЫАЂРяАЭАЭМЏЭХЁЂТьвЯМЏЭХЕФЖрИівЕЮёВПУХЃЌЛЙгаГЌ40МвЭтВППЭЛЇвВдкЪЙгУDeepGPUНјааМгЫй,ШчЙћгааЫШЄНјвЛВНСЫНтDeepGPUЕФМгЫйЃЌПЩвдСЊЯЕАЂРядЦЕФНтОіЗНАИМмЙЙЪІСЫНтЯъЯИЧщПіЁЃ
DeepSD 4.0вбдкМЦЫуГВЩЯЯпЃЌИааЫШЄЕФХѓгбПЩвджБНгЬхбщЃЌСДНгШчЯТЃК

ЖЄЖЄЩЈТыМгШыЁОLLMДѓгябдФЃаЭ-АЂРядЦжЇГжШКЁП

ЖЄЖЄЩЈТыМгШыЁОSDЗНАИ-АЂРядЦжЇГжШКЁП
вдЩЯОЭЪЧБОДЮЗжЯэЕФШЋВПФкШнЁЃ


