2023Фъ10дТ31Ше-11дТ2ШеЃЌ2023дЦЦмДѓЛсдкжаЙњКМжнЁЄдЦЦмаЁеђОйааЃЌаЏГЬШнЦїгыЛьКЯдЦбаЗЂзмМрРжКшЛддкЁОдЦЗўЮёЦї & МЦЫуЗўЮёЁПзЈГЁжаДјРДСЫЬтЮЊЁЖЛьКЯдЦЕЏадШчКЮАяжњаЏГЬгІЖдвЕЮёЕФЕЭУдгыПьЫйЛжИДЁЗЕФжїЬтбнНВЃЌЗжЯэСЫаЏГЬЕФдЦдЩњжЎТУЁЂЛьКЯдЦЕЏадЪЕМљвдМАзюжеЪЕМљаЇЙћЁЃ
вдЯТЪЧЫћЕФбнНВФкШнећРэЃЌЙЉдФРРЁЃ

РжКшЛд аЏГЬШнЦїгыЛьКЯдЦбаЗЂзмМр
вЛЁЂаЏГЬЕФдЦдЩњжЎТУ
аЏГЬДг2017ФъжЎЧАОЭПЊЪМСЫШнЦїЛЏЃЌКмдчОЭЖддкЯпгІгУНјааСЫЯШЦкЬНЫїЃЛ2018ФъЪБЃЌЛљгкдЦдЩњМмЙЙвЕЮёЕФЮДРДЧїЪЦХаЖЯЃЌгУK8sДњЬцСЫдгаЕФMesosМмЙЙЃЌВЂвдK8sЮЊЦ№ЕуЙЙНЈШнЦїЦНЬЈЃЌНјаадЦдЩњЛЏИФдьЁЃ

дЦдЩњМмЙЙВЛНіЪЧШнЦїЛЏЃЌИќЪЧећИіinfrastructureМмЙЙвдМАгІгУВуЕФЯжДњЛЏЃЌЪЙЦфОпБИгаЕЏадЁЂЧсСПЁЂПЩЧЈвЦЕФЬиадЁЃЕН2020ФъЃЌЮвУЧОРњСЫвпЧщЃЌжБНгЕМжТвЕЮёНјШыСЫЕЭУдЦкЃЌЕЋЪЧЖдзіЛљДЁМмЙЙЕФШЫРДНВЪЧвЛИіЗЧГЃКУЕФЛњЛсЁЃЫљвдетМИФъвВЪЧЗЧГЃЗБУІЕФвЛЖЮЪБМфЃЌвЕЮёММЪѕЭХЖгвдМАЮвУЧЖдећИіМмЙЙзіСЫКмДѓЕФИФдьЃЌШЅДђдьвЛИіЕЏадЕФЁЂЛьКЯЖрдЦЕФЯЕЭГЁЃ
ФПЧАЃЌЮвУЧвбОЛљгкШнЦїЦНЬЈАбНќ60%вдЩЯЕФЫуСІНјааСЫШнЦїЛЏЃЌАќРЈВПЗжгазДЬЌЕФЗўЮёЁЃЭЌЪБЃЌЮвУЧвВЙЙНЈСЫвЛИіЛьКЯЖрдЦЕФМмЙЙЃЌГфЗжРћгУЕЏадЕїЖШЕФЪжЖЮЃЌНјааНЕБОдіаЇЃЌЬсЩ§дЫгЊЕФаЇТЪЁЃ

етеХЭМЪЧКНПеПЭдЫСПЕФЪ§ОнЃЌПЩвдПДЕНдквпЧщЦкМфЕФВЈЖЏЗЧГЃДѓЃЌећИівЕЮёЩЯЕФВЛШЗЖЈадЖдЮвУЧдьГЩвЛИіЗЧГЃДѓЕФбЙСІЃЌетИівЕЮёЕФВЈЖЏЛсЗДгГдкЖдећИіЛљДЁЩшЪЉЩЯЕФашЧѓКЭЬєеНЁЃ
вдЧАЃЌЮвУЧЪЧЛљгкIDCетбљДЋЭГЕФШнСПдЄВтЃЌЯрЖдРДНВЪЧвЛИіПЩдЄВтЕФЗЖЮЇЃЌЪВУДЪБКђШЅНЈЩшIDCЁЂЪВУДЪБКђШЅзМБИЪВУДбљЕФзЪдДЁЃЕЋЪЧвЛЕЉНјШывпЧщЦкМфЃЌетИіЪЧЗЧГЃФбзіЕНЕФЃЌЛљБОЩЯвдЧАЕФРњЪЗЪ§ОнвбОЮоаЇСЫЁЃ
СэвЛИіЮЪЬтЃЌвпЧщЦкМфЖдЙЋЫОЕФвЕЮёгАЯьБШНЯДѓЃЌЫљвдНЕБОбЙСІЗЧГЃДѓЃЌвЊОЁСПЖХОјзЪдДРЫЗбЁЃЭЌЪБЃЌвЛЕЉЛжИДЃЌНЋЛсгРДвЛИіУЭСвЕФЗДЕЏЃЌЖдзЪдДгаПьЫйРЉеЙЕФашЧѓЁЃМШвЊНЕБОЃЌгжвЊгІЖдЮДРДМЋЫйРЉеЙЕФашЧѓЃЌЖдећИіММЪѕЬхЯЕЕФШнСПЙмРэКЭЕЏадЪЧЗЧГЃДѓЕФвЛИіЬєеНЁЃ

гІгУШнСПЕФЙмРэЃЌдкжЎЧАЪЧЪжЙЄНјааЕФЃЌУцСйвдЯТШ§ИіЮЪЬтЃК
- ЙмРэаЇТЪЕЭЁЃвђЮЊЖМЪЧЪжЙЄЙмРэЃЌЫфШЛгавЛаЉИЈжњЕФдЄВтЙЄОпЃЌЕЋЪЧаЏГЬгавЛЭђЖрИігІгУЁЂСНЭђЖрИіВПЪ№зщЃЌашвЊЯћКФДѓСПЕФбаЗЂШЫдБЁЂSREЕФОЋСІЁЃ
- ШнСПЗчЯеИпЁЃЪжЙЄРЉШнШнвзДцдкЦЋВюЃЌвЛЕЉГіЯжЪ§ОнВЈЖЏЃЌгІгУМЋгаПЩФмдьГЩПжЛХадЕФРЉШнЃЌдьГЩШнСПМЗЖвЁЃ
- ЛљгквдЩЯЮЪЬтЃЌбаЗЂЧуЯђгкЬсЧАГЌСПРЉШнЃЌзюжеЕМжТбЯжиЕФзЪдДРЫЗбЁЃ
ЖўЁЂЛьКЯдЦЕЏадЪЕМљЃКЬсГіШЭадгХЯШМмЙЙ
еыЖдвдЩЯЬєеНгыЮЪЬтЃЌЕЏадЯЕЭГЪЧЗЧГЃКУЕФНтОіЗНАИЁЃЕЋДгЪжЙЄЙмРэЕНЕЏадЕФздЖЏЛЏЯЕЭГЃЌЖдШнЦїЦНЬЈЙЙНЈепЖјбдЃЌдѕУДШУЮвУЧЕФбаЗЂШЫдБЁЂФЫжСећИіЙЋЫОаХШЮетЬзЯЕЭГЃЌВЂдкЙиМќЪБПЬЦ№зїгУФиЃПЮвУЧАбетИіЮЪЬтДгШ§ИіЮЌЖШНјааСЫВ№НтЁЃ

- ЕЏЕУПьЃЌМДИњЩЯСїСПЁЃ
- ППЕУзЁЃЌМДЙиМќЪБКђВЛЕєСДзгЁЃ
- ШнСПзуЃЌШнСПВЛзувЛЧаЖМЪЧУтЬИЕФЁЃ

ЕквЛИіЃЌЪЧЕЏЕУПьЃЌЪЧадФмЮЪЬтЁЃЪзЯШЃЌЮвУЧЕНЕзашвЊЖрИпЕФадФмЃПЕквЛЗДгІПЯЖЈЪЧадФмдНИпдНКУЃЌЕЋЪЧЭЌбљвтЮЖзХБпМЪГЩБОЛсдНРДдНИпЁЃЫљвдЃЌШчКЮЦРЙРКЯРэЕФФПБъЗЧГЃживЊЁЃЮвУЧЪЧЛљгкГЁОАРДЦРЙРадФмФПБъЕФЃЌетаЉГЁОААќРЈШеФкРЉШнЁЂНкМйШеРЉШнЃЌЖдЮДРДЕФдіГЄдЄЦкЃЌЯЕЭГЕФШпгрЯЕЪ§ЁЃЛљгкЩЯЪіГЁОАЕФЪ§ОнМАЦРЙРЃЌРДЧУЖЈФПБъSLOЁЃШЛКѓЃЌЪсРэКЫаФСДТЗЃЌЖдСДТЗНјааВ№НтЃЌНјааЪ§ОнТёЕуЁЂЦєЖЏбЙВтЃЌЗжЮіЦПОБдйгХЛЏЕФЙ§ГЬЁЃ
дкгХЛЏЩЯЃЌГ§СЫДњТыгХЛЏЃЌИќживЊЕФЪЧМмЙЙЩЯЕФгХЛЏЁЃШчЙћжЛдкВПЗжГЁОАЪЙгУСЫШнЦїЁЂK8sЃЌЕЋЦфЫќЕФМмЙЙЩњЬЌЛЙЪЧЛљгкДЋЭГЕФОВЬЌЫМТЗЙЙНЈЃЌЖјВЛНјааЕїећЃЌФЧУДЛсЖдећЬхЕФадФмгыПЩППаддьГЩЗЧГЃДѓЕФгАЯьЁЃећЬхРДНВЃЌдЦдЩњИќживЊЕФЪЧећИіМмЙЙЕФЯжДњЛЏЙ§ГЬЁЃ

ЕкЖўИіЮЪЬтЃЌШчКЮШЗБЃЙиМќЪБПЬВЛЕєСДзгЁЃЖдгкбаЗЂШЫдБРДНВЃЌПЩвдДгОжВПзіКУУПИіЯЕЭГЕФгХЛЏЁЂбЙВтЃЌзіКУПЩППадБЃеЯЃЌЬсЩ§ОжВПЕФПЩППадЁЃЕЋЪЧШчЙћДгМмЙЙЁЂДгздЩЯЖјЯТЕФНЧЖШРДЫМПМЮЪЬтЃЌОжВПЕФЙЪеЯЪЧВЛПЩФмБмУтЕФЁЃШчЙћОжВПГіЯжЙЪеЯЃЌдѕУДШЅБЃжЄећЬхЕФПЩППадЃЌБЃжЄЖдвЕЮёЕФГаХЕЪЧФмЙЛДяЕНЕФЃПвдЯТНщЩмМИИіОЕфЕФИпПЩгУЕФЩшМЦОбщЃК
ЕквЛЃЌзіЕНЙЪеЯЕФИєРыЁЃвЊБЃжЄЯЕЭГвЛЕЉГіЯжОжВПЮЪЬтЕФЪБКђЃЌБмУтДгвЛИіОжВПЕФЙЪеЯбнБфГЩвЛИіећЬхЕФЙЪеЯЁЃдкетЛљДЁжЎЩЯЃЌПЩвддкЙЪеЯгђжЎМфзіШпгрВПЪ№ЃЌвЛЕЉЗЂЩњЙЪеЯЃЌОЭПЩвдРћгУЧаЛЛЪжЖЮЭъГЩЙЪеЯзЊвЦЁЃПЩФмДѓМвЁЂАќРЈЮвУЧздМКвВЛсзпвЛаЉЭфТЗЃЌЮвУЧвдЧАОГЃЙизЂЕФЪЧШпгрВПЪ№КЭЙЪеЯзЊвЦЃЌЭљЭљКіЪгСЫЙЪеЯИєРыЃЌЕЋЪЧЦфЪЕЁИЙЪеЯИєРыЁЙЪЧЦфжазюживЊЕФвЛИіЕуЃЌШчЙћзіВЛЕНЙЪеЯИєРыЃЌКѓУцСНИіЦфЪЕЖМЪЧЮоаЇЕФЁЃ
ЛљгкЩЯЪіЫМЯыЃЌЮвУЧЬсГіСЫШЭадгХЯШМмЙЙЁЃ

ДгНсЙЙЩЯРДПДЃЌРћгУRegion ЁЂAZЕШЙЋЙВдЦЬсЙЉЕФЬьШЛЙЪеЯгђЃЌдкетЙЪеЯгђжЎФкЃЌЙЙНЈpartitionетбљИќаЁЕФЙЪеЯгђЁЃВЛЭЌгквЕНчЁЂЩчЧјЃЌЮвУЧЕФK8sЪЧВЛПчЙЪеЯгђВПЪ№ЕФЃЌЖјЪЧВПЪ№дкpartitionФкЕФЁЃ
ЛљгкетбљЕФМмЙЙЫпЧѓЃЌВЛПЩБмУтЕУЛсГіЯжКмЖрЕФМЏШКЃЌдкЬсЙЉИјЩЯгЮЕФПЭЛЇЛђЩЯгЮЕФЯЕЭГгУЕФЪБКђЃЌЮвУЧвЊМђЛЏЫќЕФИДдгадЁЃЫљвддкетжЎЩЯЃЌУПИіRegionвВВПЪ№СЫвЛЬзFederationЃЌЩЯВуPaaSгыЪЙгУЗНЖдНгFederationЃЌгЩFederationЬсЙЉRegionФкВПЪ№ЕФЕїЖШФмСІМАЙмПиФмСІЁЃ
ЛљгкетбљЕФНсЙЙЃЌЮвУЧв§ШыСЫвЛаЉдМЪјЁЃЖдШЭадгХЯШМмЙЙЕФдМЪјжївЊгавдЯТСНЕуЃК
ЕквЛЃЌКЫаФЕФЁЂЕЏадЕФИпЦЕСДТЗгІИУЪеСВдкЙЪеЯгђФкЃЌдкЖЋЮїЯђВЛФмГіЯжЦЕЗБЕФПижЦСДТЗ/Ъ§ОнСДТЗЕФНЛЛЅЃЌвђЮЊетЛсДђЦЦЙЪеЯИєРыЕФддђЃЛ
ЕкЖўЃЌгІгУвЊдкЖрИіЙЪеЯгђ partitionжЎМфНјааШпгрВПЪ№ЃЌдкБфИќЕФЙцЗЖЩЯЃЌВЛдЪаэЭЌЪБПчдНЖрИіAZЁЂЖрИіpartitionЁЂЖрИіЙЪеЯгђжЎМфЕФБфИќЃЌвђЮЊетаЉБфИќЖЏзїЭЌбљвВЛсДђЦЦЙЪеЯИєРыЕФЧАЬсЁЃвЛАуКЫаФСДТЗЩцМАЕНЕФЛЗНкКЭЯЕЭГЗЧГЃЖрЃЌжЛгаетаЉЛЗНкКЭЯЕЭГЖМзіЕНСЫетбљЕФМмЙЙЖдЦыЃЌВХЛсеце§ЪЕЯжШЭадгХЯШЃЌетЪЧвЛИіАйУмвЛЪшКЭГжајадЕФЙЄзїЁЃ
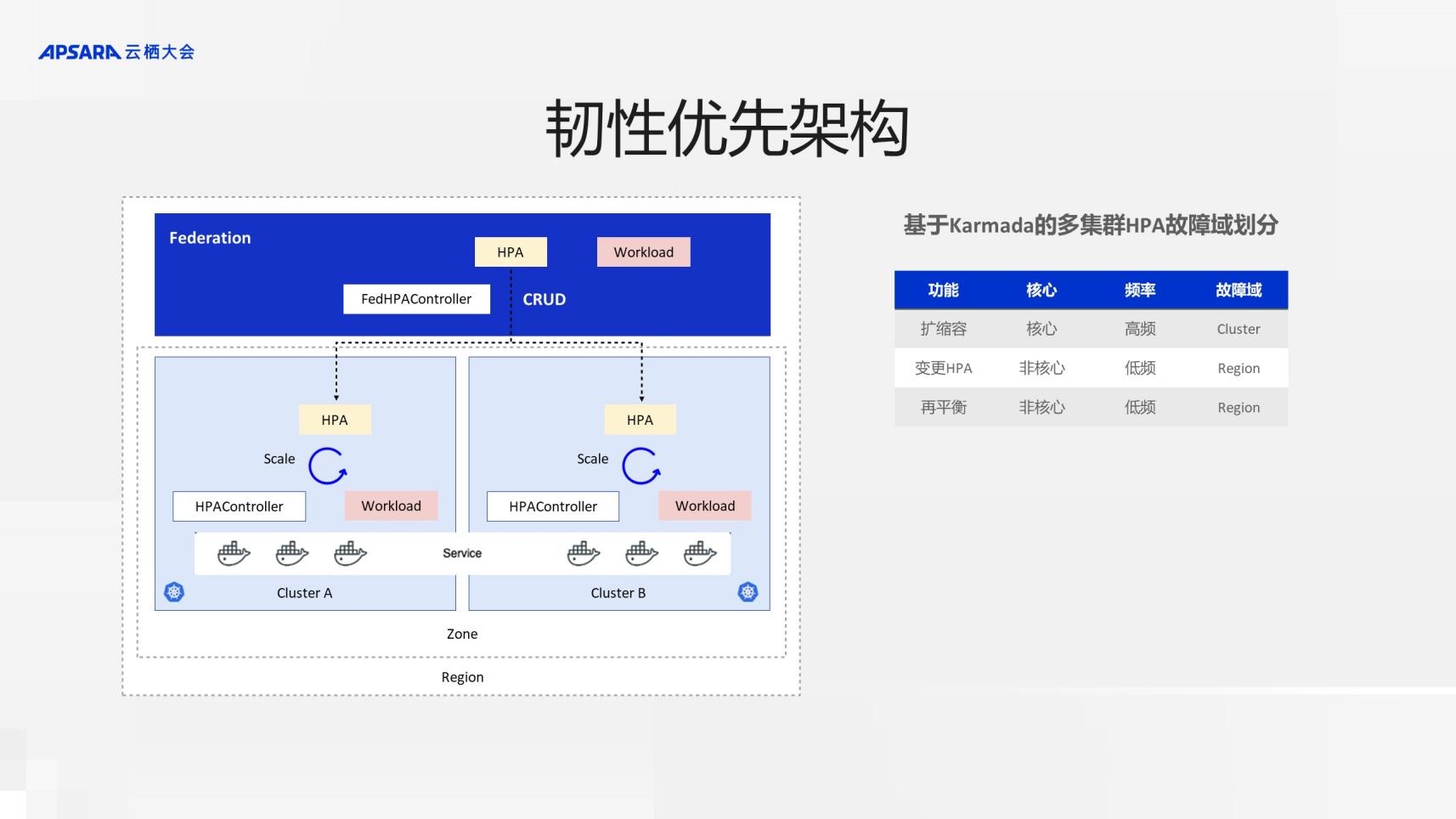
ЛљгкетбљЕФМмЙЙЫМЯыЃЌЮвУЧвВЩшМЦСЫЖрМЏШКЕФHPAЗНАИЃЌЪЕЯжHPAЙІФмЕФШЭадгХЯШЁЃ
ЪзЯШЃЌЗжЮіHPAгаФФаЉЙиМќСДТЗЁЃЕквЛИіЃЌзюКЫаФЕФЪЧЖдгІгУШнСПЕФздЖЏРЉЫѕШнЃЌЕкЖўИіЪЧHPAЕФзЪдДЕФБфИќЃЌЕкШ§ИіЪЧЖрЧјгђжЎМфШнСПЕФдйЦНКтЁЃвђЮЊРЉЫѕШнЛсгАЯьгІгУГадиСїСПЕФФмСІЃЌЫќвВЪЧзюИпЦЕЕФЃЌетЬѕСДТЗзюЮЊКЫаФЃЌЫљвдЫќЕФЙЪеЯгђЩшМЦЩЯвЊзіЕНзюаЁЃЌЙЪеЯгђЯоЖЈдкK8s ClusterЁЃМДРЉЫѕШнЕФЖЏзїдкK8s ClusterФкОЭПЩвдЗтБеЃЌЮоашИњЭтВПНјааНЛЛЅЁЃЖјдйЦНКтжївЊЪЧЮЊСЫЦНКтИїМЏШКМАAZЕФШнСПЃЌаЁЪБМЖБ№ЕФВЛПЩгУЖМВЛЬЋгАЯьвЕЮёСїСПЕФГадиЃЌЫќЕФЙЪеЯгђвЊЧѓЛсЫЩвЛЕуЃЌЮЊећИіRegionЁЃHPAзЪдДЕФБфИќРрЫЦЃЌЙЪеЯгђЖЈвхЮЊRegionЁЃ
ЛљгкетбљЕФЩшМЦгыЪЕЯжЃЌШчЙћCluster AЙвСЫЃЌСїСПЛсздЖЏАбИКдиОљКтЕиДЋЕМЕНCluster BЃЌдкCluster BРЉЫѕШнЕФзщМўЛсздЖЏРЉШнЁЃвВОЭЪЧЫЕећИіМмЙЙЃЌВЛТлЪЧИіБ№ClusterхДЕєЛђепFederationхДЕєЃЌЖдЩЯВуЕФвЕЮёРДЫЕЭъШЋЪЧЮоИаЕФЃЌЛсе§ГЃЕиНјааРЉЫѕШнЁЃ
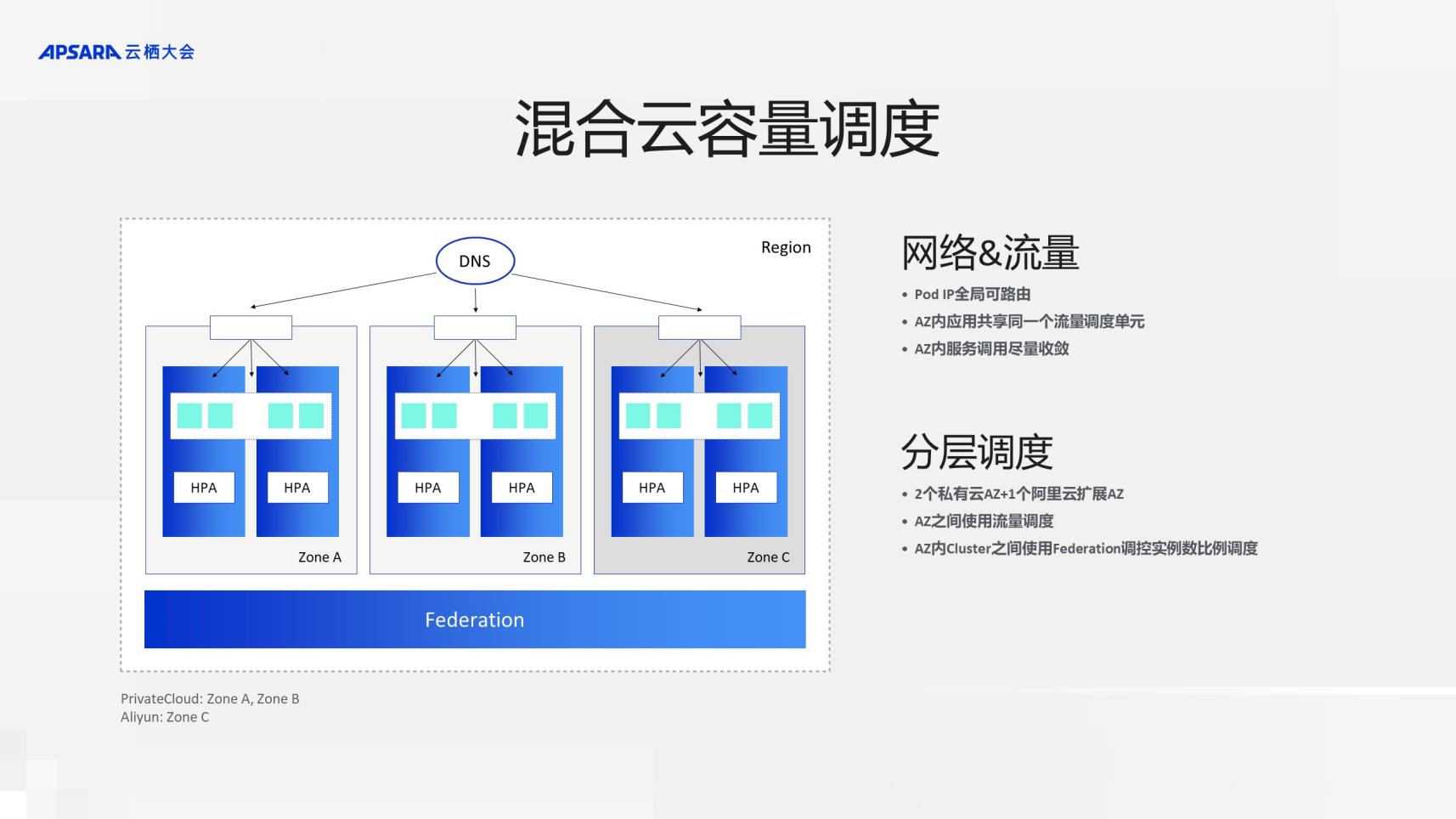
СэвЛЗНУцЃЌдѕУДНтОіШнСПЕФЮЪЬтЁЃаЏГЬвдЧАЪЧЛљгкIDCЙЙНЈЕФЃЌШнСПРЉеЙжмЦкНЯГЄЁЃФПЧАЪЧЭЈЙ§ДђЭЈАЂРядЦЃЌвдЛьКЯдЦЕФМмЙЙЃЌРћгУдЦЕФЕЏадРДРЉеЙШнСПЁЃ
ОпЬхРДПДЃЌдкаЏГЬШнЦїЕФIPЪЧШЋОжПЩТЗгЩЕФЃЌШЛКѓAZФкЪЧгІгУЙВЯэЭЌвЛИіСїСПЕїЖШЕЅдЊЃЌзіЕНЕїгУОЁСПЪеСВЁЃдкетбљЕФвЛИіНсЙЙЯТЃЌвВЬсГіСЫвЛаЉдМЪјЃКAZжЎМфШнСПЕФЧ§ЖЏЪЧгЩСїСПЕФЧ§ЖЏРДНјааЕФЃЌЕЋЪЧAZФкЕФШнСПИКдиЃЌЩѕжСЪЧЙЪеЯЧаЛЛЃЌЪЧгЩFederationНјааЕїПиЪЕР§Ъ§БШР§РДНјааЕФЁЃ
Ш§ЁЂаЇЙћЃКзюИпЗх1ЗжжгРЉШнНќ2000ИіШнЦїЪЕР§
ЩЯЭМЪЧАЂРядЦЕФФГвЛИіAZЕФзЪдДЪЙгУЕФеЙЪОЁЃПЩвдПДЕНЃЌВЈЖЏЪЧЗЧГЃОчСвЕФЃЌвВЗЧГЃИааЛАЂРядЦдкECSЕФЕЏадЙЉгІЩЯгаЗЧГЃЧПЕФФмСІЃЌАяжњЮвУЧгІЖдСїСПЕФМтЗхКЭВЈЖЏЁЃ

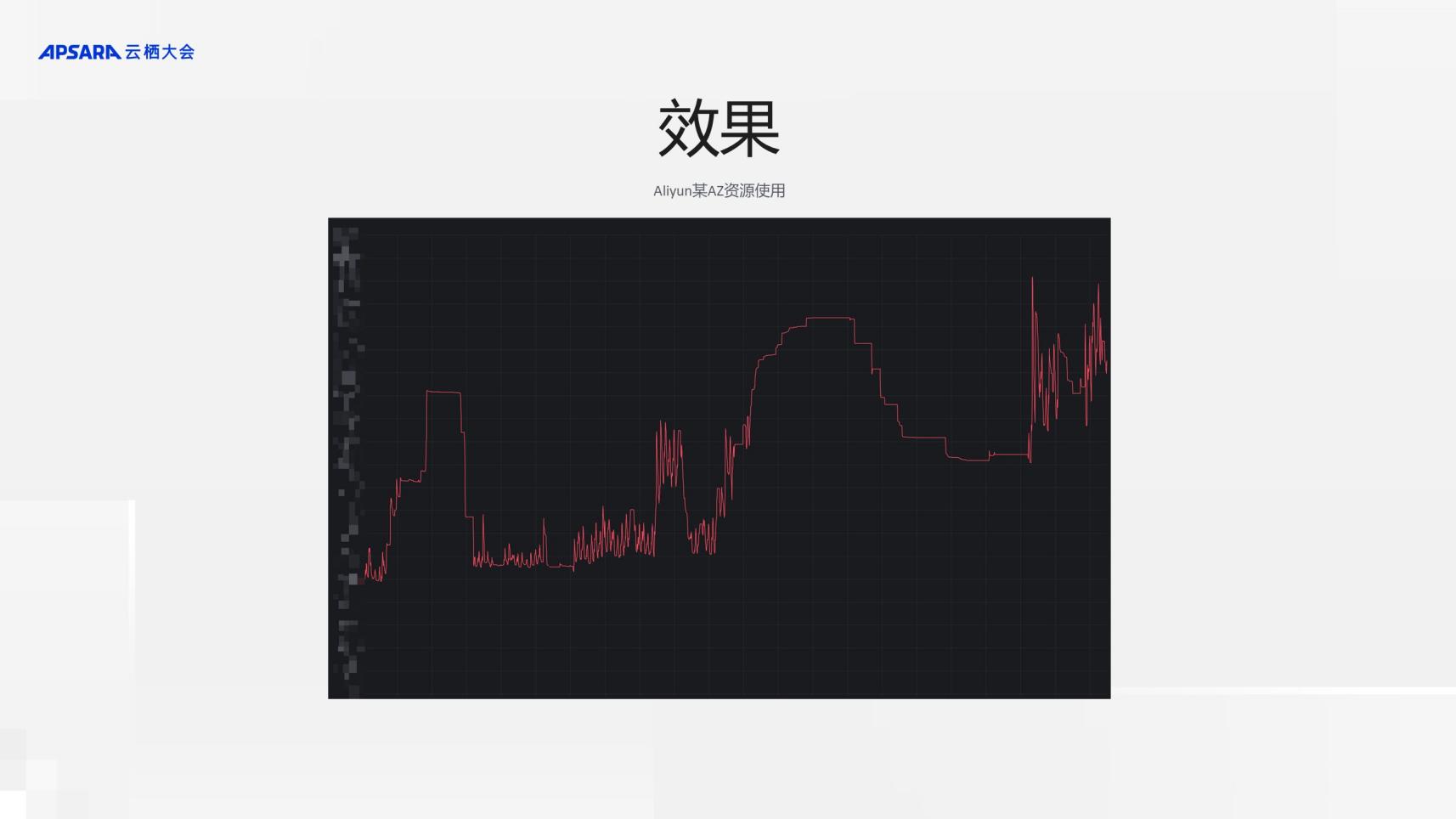
ДгЙ§ШЅвЛФъЕФжИБъПДЃЌЕЏадЯЕЭГПЩППадУЛгаЗЂЩњЙ§гАЯьвЕЮёЕФЙЪеЯЁЃЯёНёФъетУДДѓЬєеНЧщПіЯТЃЌЛљБОЩЯЯЕЭГЕФПЩППадДяЕНСЫРњЪЗзюИпЗхЁЃдкМйШеИпЗхЃЌФмЙЛзіЕНвЛЗжжггаНќ2000ИіШнЦїЪЕР§ЕФРЉШнЁЃРЉеЙадЩЯЃЌзюИпНЋ30%ЕФШнСПЕїЖШЕНАЂРядЦЃЛаЇТЪЩЯЃЌ90%вдЩЯЕФгІгУПЊСЫHPAЃЌЭЌЪБHPAБОЩэЕФВЮЪ§ЪЧгЩautopilotВњЦЗРДИКд№ШЅгХЛЏгыЙмПиЃЌвдДяЕНзюгХЛђепзёбЭГвЛЕФВпТдЃЌетбљЛљБОВЛашвЊШЫЕФВЮгыШЅдЫЮЌЁЃ
ГЩБОЗНУцЃЌЭЈЙ§ЕЏадЯЕЭГЃЌдкЯпгІгУCPUЕФЫожїЛњРћгУТЪдк25%ЕН30%жЎМфЁЃЕБШЛЫожїЛњРћгУТЪЕФЩЯЯовВЪмЕНЖрAZШнджЩшМЦЩЯЕФЯожЦЃЌШч2ИіAZЕФШнджМмЙЙвЛАуЫожїЛњЕФРћгУТЪВЛвЊГЌЙ§50%ЁЃ
вђЮЊУПИігІгУЪЧАДашЪЙгУзЪдДЕФЃЌЫљвдгІгУИњгІгУжЎМфЃЌвЕЮёИњвЕЮёжЎМфЫќгавЛИіДэЗхЕФаЇгІЁЃЛљгкДэЗхЕФаЇгІЃЌећИіЮхвЛЦкМфЃЌАбШнСПашЧѓЕФЗхжЕЯћМѕСЫ28%вдЩЯЃЌЭЌбљвВПЩвдДяЕННЕБОЕФаЇЙћЁЃ





