вЛЃЌ ЩюШыРэНтRedologШежОЕзВудРэ
дйПДБОЦЊЮФеТжЎЧАЃЌПЩвдНсКЯЁО9ЁПЩюШыРэНтmysqlжДааЕФЕзВуЛњжЦ етЦЊЮФеТРДСЫНтmysqlФкВПжДааsqlЕФЙ§ГЬЁЃ
1ЃЌinnodbв§ЧцЕзВуЪТЮёдРэ
ЪТЮёЕФЫФДѓЬиаджївЊЪЧЪЧacidЃЌЗжБ№ЪЧдзгадЁЂвЛжТадЁЂИєРыадКЭГжОУадЁЃЦфдзгадЪЧ ЭЈЙ§етИіundolog РДБЃжЄЕФЃЌГжОУадЪЧ ЭЈЙ§redolog РДЪЕЯжЕФЃЌИєРыадЪЧЭЈЙ§ЪТЮёЕФ ЖСаДЫј+mvccЛњжЦ РДЪЕЯжЕФЁЃдкетЫФДѓЬиаджаЃЌвЛжТадCЪЧзюживЊЕФЃЌЫћЪЧзюжеФПЕФЃЌжЛгаЦфЫћШ§ИіЪЕЯжСЫЃЌВХгаПЩФмЪЕЯжетИівЛжТадЃЌМД вЛжТадЪЧзюжеФПЕФЃЌЦфЫћШ§ИіОЭЪЧЪЕЯжЕФЪжЖЮ ЁЃ
1.1ЃЌWAL
дкЪТЮёЕФОпЬхЪЕЯжЕФЛњжЦжаЃЌmysqlЪЧЭЈЙ§етИіWAL(Write-ahead logging)ЃЌМДдЄаДШежОЕФЗНЪНРДЪЕЯжЕФЁЃ
ОйИіЛљБОЕФР§згЃЌМйЩшвЛИізЊЧЎЕФВйзїЃЌШчЙћAИјBзЊЧЎЃЌДЫЪБAМѕСЫ100ЃЌЖјдкBдкМг100ЕФЪБКђЃЌЭЛШЛЖЯЕчСЫЃЌФЧУДдкЪ§ОнПтжиЦєЕФЪБКђЃЌОЭЕУЛжИДЫћЖЯЕчЧАЕФзДЬЌЃЌДЫЪБОЭашвЊвЛИіШежОРДМЧТМЫћЪТЮёВйзїЧАЕФзДЬЌСЫЃЌЭЈЙ§етИіШежОжаЕФМЧТМРДЛжИДжЎЧАЕФзДЬЌЃЌХаЖЯЦфЪЧЗёашвЊЛиЙіВйзїЃЌЛЙЪЧашвЊжизіЕШВйзїЁЃЖјЪЕЯжетИіWBLЛњжЦЃЌжївЊЪЧЭЈЙ§етИіredologКЭundologетСНжжШежОЕФЗНЪНЪЕЯжЁЃ
mysqlжаГ§СЫЪЙгУетжжжїСїЕФWALЛњжЦжЎЭтЃЌЛЙЛсЪЙгУвЛаЉCommit LoggingиМShadow PagingЕШЁЃmysqlФЌШЯЪЙгУетИіWALЛњжЦЁЃ
2ЃЌredologШежОЮФМў
2.1ЃЌЮЊЪВУДвЊredologШежОЮФМў
вРОЩФУвЛИіИќаТгяОфОйР§ЃЌШчЯТЭМЃЌredologЪЧЗЂЩњдкЕк4ВНКЭЕк5ВНЃЌдкЪ§Ондкbuffer poolжаНјааЪ§ОнИќаТжЎКѓЃЌЛсАбОпЬхЕФТпМгяОфЃЌШчФФвЛвГФФвЛаавЊИќаТЕФзжЖЮвдМАИќаТЕФжЕЪЧЩЖЃЌЯШМгШыЕНredolog bufferжаЃЌЫцКѓдйШЛКѓЭЈЙ§зЗМгЕФЗНЪНГжОУЛЏЕНДХХЬЩЯЕФredologЮФМўжаЃЌдйВЛПМТЧserverВуЕФВйзїЃЌМДЬјЙ§6ЃЌ7ВНЃЌФЧУДОЭЛсЦєЖЏвЛИіКѓЬЈЯпГЬНјаавЛИіТфХЬЕФВйзїЁЃ

етРяМйЩшinnodbФкВПУЛгаетИіredologетИіШежОЮФМўЃЌОЭЪЧдкЪ§ОнИќаТжЎКѓжБНгДгbuffer poolНЋЪ§ОнИјТфХЬЃЌШчЙћдкТфХЬЕФЪБКђЪ§ОнвГУЛгаЗЂЩњЫ№ЛЕЃЌФЧУДЫЋаДЛњжЦОЭДЅЗЂВЛСЫЃЌОЭУЛгаЛЛвГЕФВйзїЃЌДЫЪБЗЂЩњЖЯЕчЃЌФЧУДЛЙУЛРДЕФМАТфХЬЕФЪ§ОнОЭЛсжБНгЖЊЪЇСЫЃЌетОЭЛсгАЯьЪ§ОнЕФАВШЋадКЭГжОУЛЏЁЃ
Г§СЫЖЯЕчетИіЮЪЬтЃЌЛЙгаПЩФмвђЮЊвЛИіаЁаЁЕФИќаТгяОфЃЌОЭжБНгНЋећвГЪ§ОнИјНјааТфХЬВйзїЃЌетбљОЭКмРЫЗбГЩБОЃЛЛђепгіЕНвЛИіsqlКмИДдгЃЌашвЊЩцМАЕФБэКмЖрЃЌВЂЧвЪ§ОнСПКмДѓЃЌФЧУДОЭашвЊИќИФКмЖрвГФПТМЕФЪ§ОнЃЌШчЙћетаЉвГФПТМдкДХХЬЩЯЕФЗжВМЪЧЫцЛњЕФЃЌФЧУДдкЫЂХЬаДЪ§ОнЕФЪБКђЃЌОЭЛсВњЩњДѓСПЕФЫцЛњioЃЌвђДЫвВКмгАЯьФкВПЕФжДаааЇТЪКЭРЫЗбПеМфЁЃ
ЫљвдЮЊСЫНтОіЪ§ОнЕФАВШЋадвдМАinnodbЕФжДаааЇТЪЃЌОЭв§ШыСЫетИіredologШежОЮФМўЃЌОЭЪЧдкТфХЬЪБЯШаДвЛЗнЕНredologжаЃЌВЂЧваДЪ§ОнЪЧЫГађаДЃЌдкredologаДГЩЙІжЎКѓЃЌдйНјааТфХЬВйзїЃЌШчЙћГіЯжЖЯЕчЮЪЬтЃЌОЭгУетИіredologетИіЮФМўНјааЪ§ОнЕФжизіЁЃ
2.2ЃЌredologЕФФкВПНсЙЙ
redologжївЊЪЧМЧТМСЫФФаЉЪ§ОнзіСЫЪВУДаоИФЃЌвђДЫетИіredologгавЛИіЭЈгУЕФИёЪНЃЌШчЯТЭМЃК

| key | value |
| type | ОЭЪЧжЕЪ§ОнЕФРраЭЃЌРраЭзмЙВга53жж |
| Space ID | БэПеМфidЃЌМДаоИФЕФЖдгІБэПеМфЕФid |
| page Number | ЕБЧАвГЕФвГКХ |
| data | вЊаоИФЕФФкШн |
2.3ЃЌredologЕФЫЂХЬЪБЛњ
дкinnodbЕФЬхЯЕНсЙЙжаЃЌПЩвдЗЂЯждкзѓБпЕФФкДцНсЙЙжаЪЧгавЛИіLog BufferЕФЛКГхЧјЕФЃЌИУЛКГхЧјОЭЪЧЖдгІЕФredologЛКГхЧјЃЌдкИУЛКГхЧјжаЃЌЦфФЌШЯДѓаЁЮЊ16MЃЌВЂЧвФкВПЗжГЩСЫЖрИіаЁПщЃЌУПвЛПщЕФДѓаЁПеМфЮЊ512kbЁЃдкЪ§ОнаДШыетИіredologЕФЛКГхЧјЕФЪБКђЃЌЛсДгЭЗЕНЮВЕФвдзЗМгЕФЗНЪННЋЪ§ОнаДШыетаЉПщжаЃЌШчЙћКѓУцЕФПщПьаДТњЃЌФЧУДЛсНЋЧАУцЭЗВПЕФПщЕФЪ§ОнЩОЕєЃЌШЛКѓдйДгЭЗЕНЮВПЊЪМДцДЂЪ§ОнЃЌДХХЬЩЯУцЕФredologвГНсЙЙКЭетИівЛбљЁЃ

ЖјетИіЛКГхЧјЫЂХЬЕФЧщПігаКУМИжжЃЌШчЯТЃК
1ЃЌlog bufferПеМфВЛзуЪБЃЌЫфШЛЫЕredologЛКГхЧјЪ§ОнДцТњЛсНЋЧАУцЕФЪ§ОнЩОГ§дйжиаТДцДЂЃЌЕЋЪЧЩОГ§жЎЧАвВЪЧвЊПМТЧЪ§ОнЕФГжОУЛЏЕФЃЌinnodbФкВПШЯЮЊЃЌЕБЪ§ОнСПДяЕНredologЛКГхЧјПеМфЕФвЛАыДѓаЁЪБЃЌОЭашвЊЧПжЦЕФНјаавЛДЮЫЂХЬВйзїЃЌДгЖјАбШежОТфХЬЕНДХХЬЩЯЁЃ
2ЃЌЪТЮёЬсНЛЪБЃЌдкЪТЮёЬсНЛЪБЃЌвВЪЧашвЊНЋЛКГхЧјжаЖдгІЕФФЧаЉШежОЪ§ОнЫЂаТЕНДХХЬЕФ
3ЃЌКѓЬЈФЌШЯЯпГЬЃЌКѓЬЈвВЪЧЛсЦєЖЏвЛИіФЌШЯЕФЯпГЬНјаавЛИіЫЂХЬВйзїЕФЃЌШчУПвЛУыЫЂаТвЛДЮ
4ЃЌЗўЮёЦїЪжЖЏЙиБеЃЌдкЗўЮёЦїЙиБеЪБЃЌвВЪЧашвЊНЋЮДЫЂХЬЕФЪ§ОнШЋВПЕФНјаавЛДЮЫЂХЬВйзїЁЃ
2.4ЃЌLog Sequence Number
МђГЦLSNЃЌЙЫУћЫМвхЃЌетИіОЭЪЧвЛИіШежОађСаКХЁЃКЭundologвЛбљЃЌдкжДаавЛЬѕИќаТЛђепВхШыгяОфЕФЪБКђЃЌОЭЛсЩњГЩвЛИіЪТЮёidЃЌетРяЕФађСаКХКЭundologЕФЪТЮёidЕФзїгУЪЧвЛбљЕФЃЌжївЊЪЧЪЧБЃжЄЪ§ОнЕФЮЈвЛадЁЃИУжЕЪЧвЛИізддіЕФађСаКХЃЌГѕЪМДѓаЁЮЊ8704ЃЌКѓУцУПдіМгвЛЬѕЪ§ОнЃЌЦфЖдгІЕФађСаКХЕФжЕОЭЛсМг1ЁЃМДLSNЕФжЕдНаЁЃЌФЧУДЦфЪТЮёВњЩњЕФдНдчЁЃ
Г§СЫетИіШежОжЎЭтЃЌinnodbФкВПЛЙгаЦфЫћЕФLSNгУРДМЧТМвбОЫЂХЬЕФЪТЮёidЁЃПЩвдЭЈЙ§ОпЬхЕФУќСюРДВщПДЯЕЭГжаИїжжLSNЕФжЕ
SHOW ENGINE INNODB STATUS\G

| key | value |
| Log sequence number | вбОаДШыredolog bufferЕФШежОСП(РлМгжЕ) |
| Log flushed up to | вбОаДШыДХХЬЕФredoШежОСП |
2.5ЃЌinnodb_flush_log_at_trx_commit
дкЪ§ОнНјааЫЂХЬЕФЪБКђЃЌЪ§ОнвВВЛЪЧжБНгЕФДгredologЛКГхЧјНЋЪ§ОнжБНгЫЂЕНДХХЬФкВПЃЌЖјЪЧашвЊЕїгУВйзїЯЕЭГЃЌЭЈЙ§ВйзїЯЕЭГНјаавЛИіТфХЬЕФВйзїЁЃдкВйзїЯЕЭГжаЃЌЛсгавЛИіВйзїЯЕЭГЕФЛКГхЧјЃЌЪ§ОнЛсЯШдкЛКГхЧјжаДцЗХЃЌШЛКѓдйЭЈЙ§ВйзїЯЕЭГЕФЕїЖШНЋЪ§ОнНјаавЛИіТфХЬЕФВйзїЁЃ
етИіЯЕЭГБфСПЕФУћГЦОЭЪЧinnodb_flush_log_at_trx_commitЃЌПЩвдЬсЙЉИјЭтВПЕїгУЃЌШчkafkaЃЌmysqlЖМЖдетИіБфСПНјааСЫЕїгУЁЃетИіБфСПзмЙВгаШ§ИіВЮЪ§ЃЌЗжБ№ЪЧ0ЁЂ1ЁЂ2ЃЌВЛЭЌЕФВЮЪ§ДњБэзХВЛЭЌЕФКЌвхЃК
ИУжЕЮЊ0ЪБЃЌБэЪОдкЪТЮёЬсНЛЪБВЛСЂМДЯђДХХЬжаЭЌВНredoШежОЃЌетИіШЮЮёЪЧНЛИјКѓЬЈЯпГЬзіЕФЁЃ
ИУжЕЮЊ1ЪБЃЌБэЪОдкЪТЮёЬсНЛЪБашвЊНЋredoШежОЭЌВНЕНДХХЬЃЌПЩвдБЃжЄЪТЮёЕФГжОУадЃЌетИіЪЧmysqlЩшжУЕФЯЕЭГФЌШЯжЕЃЌЕБЪТЮёЬсНЛЪБЃЌЛсНјаавЛИіЧПжЦЫЂХЬЕФВйзїЁЃ
ИУжЕЮЊ2ЪБЃЌБэЪОдкЪТЮёЬсНЛЪБашвЊНЋredoШежОаДЕНВйзїЯЕЭГЕФЛКГхЧјжаЃЌЕЋВЂВЛашвЊБЃжЄНЋШежОеце§ЕФЫЂаТЕНДХХЬЁЃШчЙћЪ§ОнЛЙдкВйзїЯЕЭГЛКДцжаЭЛШЛЖЯЕчЃЌФЧУДЮДТфХЬЕФЪ§ОнвВЛсЖЊЪЇЁЃ

3ЃЌundologШежО
ЩЯУцжївЊСЫНтredologШежОЃЌredologжївЊЪЧЮЊСЫБЃжЄетИіЪ§ОнЕФГжОУадЃЌACIDжаЕФDОЭЪЧППетИіredologРДБЃжЄЕФЁЃЖјНгЯТРДвЊЬжТлЕФundologШежОЃЌundologШежОжївЊЪЧЮЊСЫБЃжЄЪ§ОнЕФдзгадЃЌдкmvccФЧЦЊhttps://blog.csdn.net/zhenghuishengq/article/details/127889365ЃЌжавВЯъЯИЕФЗжЮіСЫетИіundologЃЌвВЯъЯИЕФУшЪіСЫundologШежОАцБОСДТЗКЭreadviewНсКЯРДБЃжЄЪТЮёЕФИєРыадЃЌНгЯТРДдйЖдетИіundologЗжЮівЛВЈЁЃ
3.1ЃЌundologЛиЙіЕФЗНЪН
undologШежОжажївЊЪЧМЧТМБЛаоИФЛђепаТдіЕФжЕЕФМЧТМЃЌЕБашвЊЛиЙіЪБЃЌдђНЋетИіДцДЂundologЕФжЕгУРДЛиЙіЁЃЦфЛиЙіЧщПіжївЊгаШчЯТМИжжЃК
1ЃЌЕБВхШывЛЬѕМЧТМЪБЃЌашвЊАбетЬѕМЧТМЕФжїМќжЕМЧЯТРДЃЌЛиЙіЕФЪБКђжЛашвЊАбетИіжїМќжЕЖдгІЕФМЧТМЩОЕєЁЃ
2ЃЌЕБЩОГ§СЫвЛЬѕМЧТМЃЌашвЊвЊАбетЬѕМЧТМжаЕФФкШнЖММЧЯТРДЃЌЛиЙіЪБдйАбгЩетаЉФкШнзщГЩЕФМЧТМВхШыЕНБэжаЁЃ
3ЃЌЕБаоИФСЫвЛЬѕМЧТМЃЌашвЊвЊАбаоИФетЬѕМЧТМЧАЕФОЩжЕЖММЧТМЯТРДЃЌЛиЙіЪБдйАбетЬѕМЧТМИќаТЮЊОЩжЕЁЃ
3.2ЃЌundologЪТЮёidаЮГЩЛњжЦ
дкmysqlжаЃЌжївЊгажЛЖСЪТЮёКЭЖСаДЪТЮёЁЃдкжЛЖСЪТЮёжаЃЌЦеЭЈЕФБэЪЧВЛФмНјаадіЩОИФВйзїЕФЃЌЖјСйЪБЕФБэЪЧПЩвдНјаадіЩОИФЕФЃЛЖјЖСаДЪТЮёжаЃЌЪЧЖМПЩвдНјаадіЩОИФВйзїЕФЁЃЭЌЪБдкжЛЖСЪТЮёжаЃЌгЩгкСйЪББэПЩвдНјаадіЩОИФЃЌвђДЫжЛЖСЪТЮёЕФСйЪББэжавВЪЧПЩвдВњЩњетИіЪТЮёidЕФЁЃ
undologВњЩњЕФЪТЮёidКЭетИіLSNетИіађСаКХЪЧвЛбљЕФЃЌвВЪЧвЛИізддіЕФШЋОжБфСПidЃЌдкinnodbжаЃЌУПвЛааЪ§ОнЖМЛсгавЛИіДцДЂетИіЪТЮёidЕФЕиЗНЃЌдкжЎЧАЕФааИёЪНжавВЬИЕНЙ§ЃЌетаЉвўВиОлДиЫїв§idЃЌЪТЮёidЃЌЛиЙіжИеыЕШЖМДцДЂдкетаЉааИёЪНЃЌжаЁЃШчЯТЭМжаЕФrow_id,trx_id,roll_ptrЕШ

3.3ЃЌВхШыВйзї
дкЪ§ОнНјааВхШыЕФВйзїЪБЃЌШчЙћДЫЪББэжагазХЖўМЖЫїв§ЃЌФЧУДДЫЪБГ§СЫЯђжїМќЫїв§ЫљдкЕФB+ЪїжаДцЗХећааЪ§ОнЃЌЛЙвЊЯђЖўМЖЫїв§жаДцЗХЖдгІЕФСавдМАжїМќidетИізжЖЮЁЃШчЙћГіЯжЪ§ОнЛиЙіЕФЧщПіЃЌФЧУДВЛНівЊЩОГ§жїМќЫїв§жаЕФЪ§ОнЃЌвВвЊЩОГ§ЖўМЖЫїв§жаЖдгІЕФЪ§ОнЃЌЕЋЪЧетИіidМДДцдквЛМЖЫїв§жаЃЌвВДцдкЖўМЖЫїв§жаЃЌвђДЫundologдкМЧТМетИіВхШыВйзїЕФЪ§ОнЕФЪБКђЃЌжБНгНЋИУааЪ§ОнЕФжїМќidжЕДцЗХдкетИіundologЕФАцБОСДТЗжаЃЌШчЙћГіЯжЛиЙіЕФЛАЃЌЪЧФЧУДжБНгЭЈЙ§idЩОГ§ЃЌОЭФмАбЪ§ОнШЋВПЛиЙіЛиШЅСЫЁЃ
3.4ЃЌЩОГ§Вйзї
дкЪ§ОнНјааЩОГ§ЪБЃЌ ЛсашвЊгУЕНааИёЪНжаЕФвЛИіdelete_mask зжЖЮЃЌетИізжЖЮдкМЧТМЭЗаХЯЂРяУцЃЌШчЙћИУзжЖЮЮЊ0ЃЌдђБэЪОУЛгаЩОГ§ЃЌИУзжЖЮЮЊ1ЃЌБэЪОвбОЩОГ§ЁЃ

дкinnodbжаЃЌЮЊСЫБЃжЄmvccЕФЖрАцБОВЂЗЂПижЦЛњжЦЃЌredologдкЩОГ§ЪБв§ШыСЫвЛИіжаМфзДЬЌЃЌМДдкЩОГ§ЪБЯШв§гУТпМЩОГ§ЃЌНЋdelete_maskетИізжЖЮНЋжЕБфЮЊ1ЃЌЫцКѓдкЪТЮёЬсНЛжЎКѓЃЌдйЭЈЙ§КѓЬЈЦєЖЏвЛИіЯпГЬЃЌЭЈЙ§ТжбЏЗНЪНШЅЪеМЏетИізжЖЮЮЊ1ЕФФЧаЉааЪ§ОнЃЌШЛКѓдйНЋжЕИјЩОГ§ЁЃ
гЩгкЫљгаЕФЪ§ОнЖМЪЧЭЈЙ§ЫЋЯђСДБэЕФЗНЪНДЎдквЛЦ№ЃЌвђДЫдкЩОГ§ЕФЪБКђЃЌжЛашвЊНЋСДБэЕФЧАЧ§КЭКѓМЬаоИФМДПЩЃЌВЂЧвЛсНЋетИіашвЊЩОГ§ЕФЪ§ОнЃЌЙвдиетИіPage FreeвГЕФЩЯУцЁЃPage FreeвГУцЩЯЕФЪ§ОнБэЪОИУПеМфЩЯУцЕФвГУцПЩвдБЛжиИДРћгУЁЃ
3.5ЃЌИќаТВйзї
дкupdateЗНУцЃЌОЭЛсЯрЖдЕФБШаТдіКЭЩОГ§СНжжЗНЪНИќМгЕФТщЗГвЛаЉЃЌжївЊЗжЮЊИќаТжїМќКЭВЛИќаТжїМќЁЃ
3.5.1ЃЌВЛИќаТжїМќ
дкВЛИќаТжїМќЪБЃЌгжЗжЮЊОЭЕиИќаТКЭЮяРэЩОГ§дйВхШыЁЃШчЙћдкЖдФГИізжЖЮзіИќаТЪБЃЌЦфвЊИќаТЕФжЕЕФГЄЖШВЛБфЃЌФЧУДОЭЛсжБНгбЁдёОЭЕиИќаТЃЌШчдРДЕФжЕЮЊ"еХШ§"ЃЌЯждкНЋжЕИФЮЊ"РюЫФ"ЃЌИФБфЕФжЕЕФГЄЖШВЛБфЃЌФЧУДОЭВЛЛсгАЯьећвГЪ§ОнЕФНсЙЙЃЌЦфбЁдёОЭЕиИќаТЃЛШчЙћИќаТжЕЕФГЄЖШКЭдРДЕФГЄЖШВЛвЛбљЃЌШчдРДЪЧвЛИі"еХШ§"ЃЌЯждкБфГЩСЫ"еХШ§Зс"ЃЌЫћЕФжЕКмУїЯдВЛвЛбљЃЌФЧУДОЭЛсбЁдёЯШЩОГ§ОЩМЧТМЃЌдйВхШыаТЕФМЧТМЁЃЛЛОфЛАЫЕЃЌОЭЪЧПДПеМфДѓаЁЪЧЗёЗЂЩњИФБфЃЌВЛБфдђОЭЕиИќаТЃЌБфдђЯШЩОГ§КѓВхШыЁЃ
3.5.2ЃЌИќаТжїМќ
ИќаТжїМќВйзїКЭЩОГ§ВйзїгаЕуРрЫЦЃЌЮЊСЫБЃжЄmvccЛњжЦЃЌвВЪЧЭЈЙ§МЧТМЭЗаХЯЂжаЕФdelete maskзжЖЮРДзїЮЊвЛИіжаМфзДЬЌЃЌМДНЋетИізжЖЮЕФжЕИФЮЊ1ЃЌШЛКѓдйЪТЮёЬсНЛжЎКѓдйНЋетЬѕЪ§ОнЩОГ§ЁЃЩОГ§жЎКѓдйаТдівЛЬѕЪ§ОнЃЌИљОнаТЕФжїМќжЕдкB+ЪїжаевЕНаТЕФЖЈЮЛЃЌШЛКѓНЋЪ§ОнаТдіЕНДЫЕиЁЃОЭЪЧИќаТжїМќПЩвдПДГЩЪЧСНВНВйзїЃЌЯШdeleteВйзїЃЌдйinsertВйзїЃЌвђДЫдкИќаТжїМќЪБЃЌОЭЛсВњЩњСНЬѕundoШежОЁЃ
4ЃЌЪТЮёЕФећЬхжДааСїГЬ
ЭЈЙ§ЩЯУцЕФredologКЭundologЕФПЩжЊЃЌredologЪЧЮЊСЫБЃжЄЪТЮёЕФГжОУадЃЌЫћОпгажизіЕФЙІФмЃЌundologЪЧЮЊСЫБЃжЄЪТЮёЕФдзгадЃЌЫћОпгаГЗЛиЕФЙІФмЁЃвђДЫдкПЊЦєвЛИіЪТЮёЪБЃЌПЩвдзмНсвЛЯТИїИіШежОжаЕФзїгУвбОећИіЪТЮёЕФжДааСїГЬЁЃ

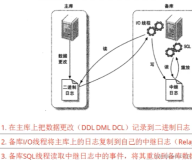
1ЃЌвдвЛИіИќаТгяОфЮЊР§ЃЌдкПЊЦєЪТЮёжЎКѓЃЌЛсНЋДХХЬжавЊИќаТЕФЪ§ОнвдвГЕФЗНЪНМгдиЕНbuffer poolЛКГхЧјжа
2ЃЌдкжДааИќаТгяОфЪБЃЌЛсЭЈЙ§undologМЧТМБЛаоИФЕФжЕЁЃдкinnodbжаЃЌЮЊСЫБЃжЄundologШежОБОЩэЕФГжОУадЃЌвђДЫвВЛсЭЈЙ§вЛИіredologШежОРДМЧТМРяУцаТдіЕФМЧТМЃЌШчundologЕФАцБОПижЦСДТЗаТдівЛИіНсЕуЪБЃЌredologОЭЛсМЧТМдкетЬѕСДБэЕФЪВУДЮЛжУМгШыСЫФФИіНсЕуЃЌМЧТМЭъжЎКѓНЋМЧТММгШыЕНRedologЕФЛКГхЧјжаЃЌдйЭЈЙ§вЛЖЈЕФЗНЪННјааЫЂХЬГжОУЛЏЃЌЫљвддкећИіЪТЮёЕФЙ§ГЬжаЃЌredologБШundologЯШЫЂХЬЁЃЫцКѓНЋвЊИФБфЕФжЕМгШыЕНbuffer poolжа
3ЃЌдкbuffer poolжажДааsqlЕФИќаТЃЌНЋвЊИќаТТпМгяОфвВМгШыЕНRedologЛКГхЧјжаЃЌДЫЪБвВЛсгавЛИіredologЫЂХЬВйзїЁЃ
4ЃЌ дкЬсНЛЪТЮёЪБЃЌвВЛсШУЖдгІЕФredologШежОМЧТМНјаавЛИіЫЂХЬВйзїЁЃ
5ЃЌЫцКѓundologЛсНјааЫЂХЬВйзїЃЌbuffer poolжаЕФЪ§ОнвВЛсЭЈЙ§КѓЬЈЕФЯпГЬНјаавЛИіЪ§ОнЫЂХЬЕФВйзїЁЃ
6ЃЌдкundologШежОКЭredologШежОЃЌЪ§ОнвГШЋВПЫЂХЬЭъГЩжЎКѓЃЌЪТЮёжДааЭъБЯЁЃ
5ЃЌredologКЭbinlogЕФЙиЯЕ
ДгЯТЭМРДПДЃЌredologЪЧЪєгкв§ЧцВуЕФЃЌМДЪєгкinnodbДцДЂв§ЧцЬигаЕФЃЌЖјbinlogЪЧЪєгкserverВуЕФЃЌМДЫљгаЕФв§ЧцВуЙВгаЃЌinnodbгаЃЌMyIsamвВгаЁЃДгећИіСїГЬРДПДЃЌbinlogКЭredologЖМЪЧЖдвЛЗнЪ§ОнНјааЕФДцДЂЃЌВЂЧвдкДцДЂЙ§ГЬжаЃЌашвЊЭЈЙ§ЪТЮёБъМЧРДБЃжЄСНИіШежОжаМЧТМЕФжЕвЛбљЁЃ

5.1ЃЌЮЊЪВУДгУredologЛжИДЪ§ОнЖјВЛгУbinlog
1ЃЌbinlog ЛсМЧТМБэжаЫљгаИќИФВйзїЃЌАќРЈИќаТЩОГ§Ъ§ОнЃЌИќИФБэНсЙЙЕШЕШЃЌжївЊгУгкШЫЙЄЛжИДЪ§ОнЃЌШчПЊСЫbinlogЩОПтвВВЛгУХмТЗЃЛЖјredologжївЊЪЧmysqlФкВПЪЙгУЕФЃЌдкЪ§ОнПтЭЛШЛБРРЃmysqlФкВПЛсздЖЏЕФЭЈЙ§етИіredologНјаавЛИіжизіЕФВйзїЁЃ
2ЃЌredologЪЧInnodbв§ЧцВуЬигаЕФЃЌbinlogЪЧServerВуЪЕЯжЕФ
3ЃЌredologМЧТМЕФЪЧЮяРэШежОЃЌШчдкФФвЛвГФФвЛааФФИізжЖЮзіСЫЪВУДаоИФЃЌЦфаЇТЪИќИпЃЛbinlogОЭЪЧдЪМЕФТпМЃЌКЭдРДЕФsqlВюВЛЖр
4ЃЌredologФЌШЯДѓаЁЮЊ48MЃЌЦфФкДцЪЧгаЯоЕФЃЌвђДЫЦфФкВПЪЧЭЈЙ§бЛЗаДЕФЗНЪНШЅБЃДцЪ§ОнЃЌВЂЧвЦфФкВПжЛМЧТМЮЊЫЂХЬЕФЪ§ОнЃЌвбЫЂХЬЕФЪ§ОнЛсздЖЏЕФДгетИіredologжаЩОГ§ЃЛbinlogВЩгУЕФЪЧзЗМгаДЃЌЫљгаЕФМЧТМЖМЛсБЃДцЁЃЖјдкЛжИДЪ§ОнЕФЪБКђжЛашвЊЛжИДетВПЗжЮДЫЂХЬЕФМДПЩЃЌВЛашвЊШЋВПОЭаавЛИіЖдБШдйВйзїЁЃ
5ЃЌШчЙћдйвЛИіЪТЮёжаГіЯжСНЬѕЯрЭЌЕФsqlЃЌШчset age = age + 1 where id = 2ЃЌШчЙћbinlogвЛЬѕЫЂХЬГЩЙІвЛЬѕЫЂХЬЪЇАмЃЌФЧУДЫћЪЧВЛФмЧјЗжетСНЬѕЪЧгаУЛгаШЋВПЫЂХЬГЩЙІЛђепЪЇАмЕФЃЌЛЛОфЛАЫЕОЭЪЧгЩгквбОгавЛЬѕГЩЙІСЫЃЌФЧУДОЭВЛФмБЃжЄЪЧЕквЛЬѕГЩЙІСЫЛЙЪЧЕкЖўЬѕГЩЙІСЫЃЌвђДЫВЛЙмЪЧШЋВПЛжИДЛЙЪЧШЋВПВЛЛжИДЃЌФкВПЕФЪ§ОнПЯЖЈВЛЖдЃЛЖјredologОЭВЛвЛбљСЫЃЌжЛашвЊАбredologФкВПЮДЫЂХЬЕФНјаавЛИіЫЂХЬВйзїОЭКУСЫЁЃ
5.2ЃЌbinlogКЭredologШчКЮБЃжЄЪ§ОнЕФвЛжТад
mysqlжажївЊЪЙгУ2pcЃЌСННзЖЮЬсНЛРДБЃжЄЪ§ОнЕФвЛжТадЁЃЕквЛНзЖЮОЭЪЧЯШзівЛИізМБИЙЄзїЃЌПЊЦєвЛИіЪТЮёЬсНЛЦїЃЌШУЫљгаЕФзЪдДзМБИКУЃЌШЛКѓЛсШЅЪеМЏЫљгаЕФзЪдДзДЬЌЃЌЕБЫљгазЪдДЕФзДЬЌЖМзМБИКУСЫжЎКѓЃЌдйНјШыЕкЖўНзЖЮЃЌЗЂГівЛИіcommitЕФУќСюЃЌЫљгаЕФзЪдДНјаавЛИіcommitЬсНЛЁЃ