1ЁЂв§бд
СЊАюбЇЯАНЋДЋЭГЛњЦїбЇЯАжаЕФЪ§ОнОлКЯзЊЛЛГЩФЃаЭОлКЯЃЌМДclientКЭserverдкСЊАюбЕСЗЙ§ГЬжаашвЊНјааФЃаЭДЋЪфЛђЬнЖШДЋЪфЁЃЫцзХШЮЮёИДдгадКЭЖдФЃаЭадФмвЊЧѓЕФж№НЅЬсЩ§ЃЌЩёОЭјТчЕФВуЪ§ГЪж№НЅМгЩюЕФЧїЪЦЃЌФЃаЭВЮЪ§вВЯргІЕФдНРДдНЖрЁЃвдШЫСГЪЖБ№ResNET-50ЮЊР§ЃЌдЪМФЃаЭгЕгаГЌЙ§2000ЭђИіВЮЪ§ЃЌФЃаЭДѓаЁГЌЙ§100MBЁЃдкФЃаЭВЮЪ§НЯЖрЁЂЭЈаХДјПэгаЯоЁЂclientНЯЖрЕШСЊАюбЇЯАГЁОАжаЃЌЗўЮёЦїНгЪеЕФЪ§ОнСПЗЧГЃХгДѓЃЌдьГЩНЯДѓЕФЭЈаХбЙСІЃЌбЯжигАЯьСЫећЬхбЕСЗаЇТЪЁЃвђДЫЃЌСЊАюбЇЯАжаНЕЕЭДЋЪфЪ§ОнСПЃЌВЂБЃжЄећЬхадФмаЇЙћКЭЪеСВЫйЖШГЩЮЊвЛИіШШУХЕФбаОПЗНЯђЁЃ
2ЁЂгХЛЏЗНЗЈ
ФПЧАГЃМћСЊАюбЇЯАЪ§ОнбЙЫѕЗНЗЈЗжЮЊСНДѓРрЃКclient-basedЃЈМѕЩйВЮгыОлКЯЕФclientЪ§СПЃЉКЭmodel-basedЃЈМѕЩйУПИіclientЩЯДЋЕФЪ§ОнСПЃЉЁЃ
2.1 client-based methods
ЃЈ1ЃЉвьВНИќаТ [1]
ДЋЭГЕФFedAVGЫуЗЈЪЧЭЌВНИќаТЫуЗЈЃЌМДЫљгаclientашвЊЭЌВНЩЯДЋФЃаЭ/ЬнЖШаХЯЂИќаТserverФЃаЭЁЃвђДЫдкУПДЮНјааФЃаЭОлКЯЪБЃЌserverЖЫЖМашвЊНгЪмДѓВПЗжЛђепШЋВПclientЕФФЃаЭЪ§ОнЃЌМЋДѓдіМгСЫserverЖЫЕФЪ§ОнЭЈаХбЙСІЁЃ
вьВНСЊАюбЇЯАЪЧжИclientвРДЮЩЯДЋВЂИќаТserverЖЫФЃаЭЁЃШчЭМ1ЫљЪОЃЌ[2]ЬсГівЛжжЛљгкЭЌЬЌМгУмЕФвьВНСЊАюбЇЯАЃЌclientжЎМфЪзЯШРћгУЕкШ§ЗНЗўЮёЦїЩшЖЈЯрЭЌЭЌЬЌМгУмЙЋдПКЭЫНдПЃЌВЂНЋЙЋдПЩЯДЋжССЊАюбЕСЗserverжаЃЛдкclientУПДЮНјаабЕСЗжЎЧАЃЌЯШДгserverЛёШЁзюаТЕФМгУмФЃаЭЃЌВЂРћгУЫНдПНтУмЕУЕНУїЮФФЃаЭИќаТclientФЃаЭЃЛclientiНјааБОЕибЕСЗЕУЕНЬнЖШ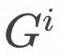 ЃЌНсКЯбЇЯАІСКЭЭЌЬЌМгУмЙЋдПЕУЕН
ЃЌНсКЯбЇЯАІСКЭЭЌЬЌМгУмЙЋдПЕУЕН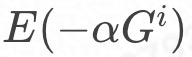 ЃЌЩЯДЋжСserverЃЛНјЖјИќаТserverФЃаЭЕУЕН
ЃЌЩЯДЋжСserverЃЛНјЖјИќаТserverФЃаЭЕУЕН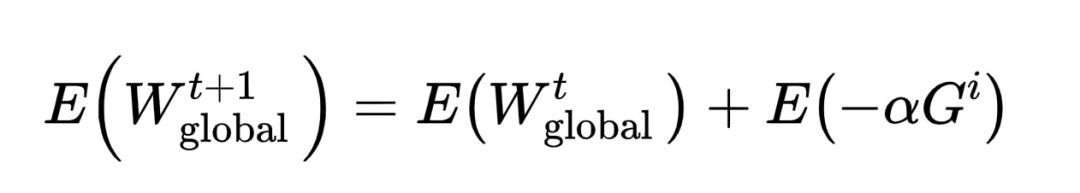 ЭъГЩвЛДЮвьВНбЕСЗЙ§ГЬЁЃ
ЭъГЩвЛДЮвьВНбЕСЗЙ§ГЬЁЃ
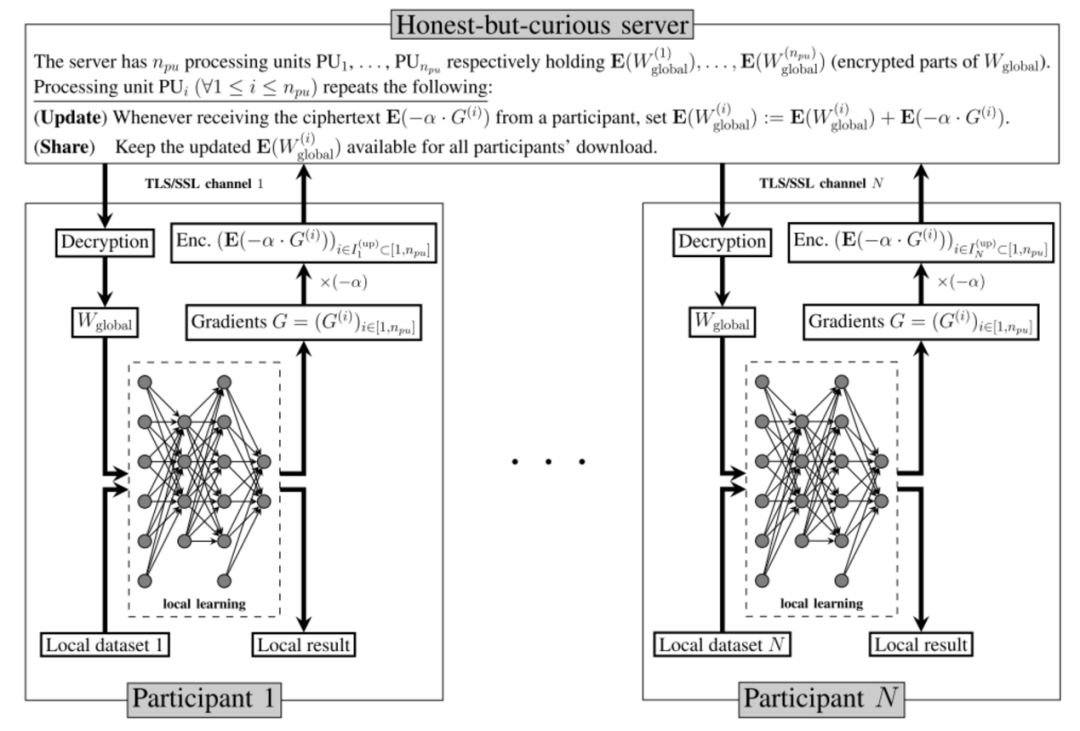
ЭМ1вьВНСЊАюбЇЯА
ЃЈ2ЃЉclientВЩбљ [3]
гывьВНСЊАюЯрРрЫЦЃЌclientВЩбљЗЈЭЈЙ§МѕЩйУПДЮОлКЯЙ§ГЬжаclientЕФЪ§СПРДМѕЩйserverЖЫНгЪеЕФЪ§ОнСПЁЃРћгУOrnstein-UhlenbeckЙ§ГЬЖдСЊАюОлКЯЕФclientНјааВЩбљЃЌДгЖјМѕЩйЕЅДЮОлКЯЪБЪ§ОнЩЯДЋЕФзмСПЁЃ
ЃЈ3ЃЉМѕЩйСЊАюОлКЯЦЕТЪ [4]
діМгFedAVGжаclientБОЕиЕФбЕСЗДЮЪ§ЃЌДгЖјМѕЩйећЬхЕФЩЯДЋЦЕТЪЃЌДяЕНМѕЩйећЬхЭЈаХЪ§ОнСПЕФФПЕФЁЃБОЕибЕСЗДЮЪ§ВЛФмЮоЯодіМгЃЌЗёдђЛсгАЯьећЬхЕФЪеСВЫйЖШЁЃ
2.2 model-based methods
ЃЈ1ЃЉОиеѓЗжНтЗЈ [4]
НЋдЪМФЃаЭШЈжиОиеѓWЗжНтГЩСНИіОиеѓЕФГЫЛ§ЃЌМДW=ЃЌЦфжаОиеѓBЕФааЪ§аЁгкWЕФааЪ§ЃЌСаЪ§ЕШгкWЕФСаЪ§ЃЌНЋвђзгОиеѓAзїЮЊЛљОиеѓЃЌЩЯДЋСэЭтвЛИіОиеѓBЃЌДгЖјМѕЩйФЃаЭДѓаЁЁЃИУЗНЗЈЪмЯогкЛљОиеѓЕФбЁдёЃЌгЩгкЛљОиеѓВЛвЛЖЈЪЧЗНОиеѓЃЌПЩФмВЛДцдкЯргІЕФФцОиеѓЃЌвђДЫЮоЗЈЧѓЕУОиеѓBЃЛЕБЛљОиеѓAЮЊСаТњжШОиеѓЪБЃЌДцдкЯргІЕФзѓФцОиеѓЃЌЕЋОиеѓBЯрБШгкWЕФбЙЫѕБШгаЯоЃЌФЃаЭЩЯДЋЕФЭЈаХбЙСІвРШЛНЯДѓЁЃ
ЃЈ2ЃЉФЃаЭЯЁЪшЗЈ
МДдкНјааФЃаЭЩЯДЋЪБЃЌАДееФГжжЗНЗЈЃЈР§ШчЫцЛњЯЁЪшЗЈ[4]ЁЂTopkЯЁЪшЗЈ[5][6]ЁЂФЃаЭМєжІ[7][8]ЕШЗНЗЈЃЉбЁдёФЃаЭЛђепЬнЖШжавЛЖЈБШР§ЕФдЊЫиЃЌНіНЋбЕСЗГЩдБЕФетаЉдЊЫиЩЯДЋжСЗўЮёЦїжаЃЌАДеедЊЫиЕФЪЕМЪЮЛжУдкЗўЮёЦїЖЫНјааАВШЋОлКЯЃЌНјЖјИќаТФЃаЭЁЃ
ЃЈ3ЃЉФЃаЭСПЛЏЗЈ
МДЖдбЕСЗГЩдБЕФЩЯДЋФЃаЭНјааСПЛЏДІРэЃЌМѕЩйдЊЫиЕФЮЛЪ§ЃЌДгЖјМѕЩйЪ§ОнЭЈаХСПЃЌЪЕЯжФЃаЭбЙЫѕЕФаЇЙћЁЃГЃМћЕФЗНЗЈжївЊгаЃК1-bitbinaryСПЛЏ[9]ЁЂmulti-bitСПЛЏ[10]ЁЃФЃаЭСПЛЏвЛАуНЋЩЯДЋФЃаЭЕФдЊЫиЮЛЪ§НјааЩОМѕЃЌЕББЃСєЮЛЪ§НЯЖрЪБЃЌбЙЫѕБШР§гаЯоЃЛЕББЃСєЮЛЪ§НЯЩйЪБЃЌФЃаЭИќаТЕФаХЯЂЪмЫ№ЃЌгАЯьФЃаЭЕФЪеСВЫйЖШЁЃ
ЃЈ4ЃЉЛьКЯЗЈ
ЮЊСЫНјвЛВННЕЕЭЩЯДЋЪ§ОнСПЕФДѓаЁЃЌПЩНЋФЃаЭЯЁЪшЗЈКЭСПЛЏЗЈНјааНсКЯЃЌМДЖдsparseФЃаЭжаЕФдЊЫидйНјааСПЛЏДІРэЁЃИУРрЗНЗЈЕФpaperжївЊгаЃК[11][12][13]ЁЃ
3ЁЂОпЬхЪЕМљ
ЮвУЧЛљгквўгя/fasciaПђМмРћгУСЊАюбЇЯАдкDrgsвНСЦГЁОАЯТНјааСЫЖрЗНСЊКЯбЕСЗКЭвЕЮёТфЕиЁЃгЩгкclientЖЫЩЯДЋДјПэгаЯоЃЌЭЈаХЪБМфНЯГЄГЩЮЊжЦдМећЬхбЕСЗаЇТЪЕФЦПОБЁЃЮвУЧЛљгкTok-SparseЫуЗЈЩшМЦСЫСЊАюбЇЯАИіадЛЏЯЁЪшЫуЗЈЃЌНЕЕЭСЫФЃаЭЪ§ОнДЋЪфЕФбЙСІЃЌЬсИпСЫNon-IIDЯТЕФФЃаЭзМШЗадЁЃРћгУИУЗНЗЈЃЌЮвУЧНЋЭЈаХСПбЙЫѕжСдЭЈаХСПЕФ1/10ЪБЃЌФЃаЭЕФзМШЗадБЃГжВЛБфЃЌМЋДѓЬсИпСЫСЊАюбЇЯАЕФадФмЁЃ
4ЁЂНсгя
ЖдСЊАюбЇЯАНјааЭЈаХбЙЫѕгажњгкНЕЕЭЭЈаХбЙСІЃЌЬсИпбЕСЗаЇТЪЃЌдіМггУЛЇЪ§СПЃЌЖдгквЕЮёТфЕиОпгаНЯЮЊУїЯдЕФдівцЁЃЮвУЧНЋЛсдкФПЧАЫуЗЈЕФЛљДЁЩЯЬНЫїбЕСЗЫйЖШИќПьЁЂбЙЫѕБШИќИпЁЂТГАєадИќКУЕФгХЛЏЫуЗЈЃЌЛЖгДѓМввЛЦ№ЬНЬжЁЃ
Reference
ЁО1ЁПXieC, Koyejo S, Gupta I. Asynchronous federated optimization[J]. arXivpreprint arXiv:1903.03934, 2019.
ЁО2ЁПAonoY, Hayashi T, Wang L, et al. Privacy-preserving deep learning viaadditively homomorphic encryption[J]. IEEE Transactions onInformation Forensics and Security, 2017, 13(5): 1333-1345.
ЁО3ЁПRiberoM, Vikalo H. Communication-efficient federated learning via optimalclient sampling[J]. arXiv preprint arXiv:2007.15197, 2020.
ЁО4ЁПKone?n?J, McMahan H B, Yu F X, et al. Federated learning: Strategies forimproving communication efficiency[J]. arXiv preprintarXiv:1610.05492, 2016.
ЁО5ЁПAsadM, Moustafa A, Ito T. FedOpt: Towards communication efficiency andprivacy preservation in federated learning[J]. Applied Sciences,2020, 10(8): 2864.
ЁО6ЁПHaddadpourF, Kamani M M, Mokhtari A, et al. Federated learning withcompression: Unified analysis and sharp guarantees[J]. arXiv preprintarXiv:2007.01154, 2020.
ЁО7ЁПLiA, Sun J, Wang B, et al. Lotteryfl: Personalized andcommunication-efficient federated learning with lottery tickethypothesis on non-iid datasets[J]. arXiv preprint arXiv:2008.03371,2020.
ЁО8ЁПLinS, Wang C, Li H, et al. ESMFL: Efficient and Secure Models forFederated Learning[J]. arXiv preprint arXiv:2009.01867, 2020.
ЁО9ЁПBernsteinJ, Wang Y X, Azizzadenesheli K, et al. signSGD: Compressedoptimisation for non-convex problems[C]//International Conference onMachine Learning. PMLR, 2018: 560-569.
ЁО10ЁПMagnssonS, Shokri-Ghadikolaei H, Li N. On maintaining linear convergence ofdistributed learning and optimization under limited communication[J].IEEE Transactions on Signal Processing, 2020, 68: 6101-6116.
ЁО11ЁПBeguierC, Tramel E W. SAFER: Sparse secure Aggregation for FEderatedleaRning[J]. arXiv preprint arXiv:2007.14861, 2020.
ЁО12ЁПSattlerF, Wiedemann S, MЈЙller K R, et al. Robust andcommunication-efficient federated learning from non-iid data[J]. IEEEtransactions on neural networks and learning systems, 2019, 31(9):3400-3413.
ЁО13ЁПSunJ, Chen T, Giannakis G B, et al. Lazily Aggregated Quantized GradientInnovation for Communication-Efficient Federated Learning[J]. IEEETransactions on Pattern Analysis and Machine Intelligence, 2020.