ЖўЁЂ ModelScopeЩчЧјжњСІгявєAIЗЂеЙ
ДяФІдКгявєЪЕбщЪвЭЈЙ§ModelScopeЩчЧјЃЌАбЙ§ШЅЛ§РлЕФгХауЫуЗЈПЊдДЃЌВЂПЊЗХСЫЫуЗЈЩњВњЕФФЃаЭЁЃДяФІдКЯЃЭћУПИіФЃаЭПЊЗЂепЖМПЩвдЭЈЙ§ModelScopeЩчЧјЃЌНгДЅЕНДяФІдКЕФЫуЗЈКЭдЄбЕСЗФЃаЭЁЃ

дкModelScopeЩчЧјЃЌФЃаЭПЊЗЂепВЛЕЋПЩвдИДдДяФІдКЩњВњЕФдЄбЕСЗФЃаЭЃЌЖјЧвПЩвддкздМКЕФЪ§ОнСьгђЃЌНјааЖЈжЦЛЏПЊЗЂЁЃ

ФПЧАЃЌДяФІдКдкModelScopeЩчЧјПЊЗХСЫЮхДѓСьгђЕФШ§ЪЎЖрИіВЛЭЌФЃаЭЁЃАќРЈгявєЪЖБ№ЁЂгявєКЯГЩЁЂгявєЛНабЁЂгявєаХКХДІРэЁЂПкгягябдДІРэСьгђЁЃ

гУЛЇПЩвддкУПИіФЃаЭЕФЯъЧщвГЃЌПДЕНЯъЯИЕФФЃаЭаХЯЂМАФЃаЭаЇЙћЁЃгУЛЇПЩвджБНгЭЈЙ§ЭјвГНјааНЛЛЅЃЌжБЙлЬхбщгявєЪЖБ№ИњгявєКЯГЩЕФаЇЙћЁЃ

НгЯТРДЃЌНщЩмвЛЯТДяФІдКДДаТЕФгявєЪЖБ№ФЃаЭЁАParaformerЁБЁЃФПЧАЃЌжїСїгявєЪЖБ№ФЃаЭЪЧЖЫЕНЖЫЕФздЛиЙщФЃаЭЁЃParaformerФЃаЭдкздЛиЙщФЃаЭЕФЛљДЁжЎЩЯЃЌДѓЗљЬсЩ§СЫЭЦРэЪБЕФаЇТЪЃЌИјгшгУЛЇЪЎБЖЕФаЇФмЬсЩ§ЃЌНЕЕЭФЃаЭЕФЗўЮёГЩБОЁЃ

гыДЫЭЌЪБЃЌАЂРядЦЯпЩЯUni-ASRФЃаЭЭЈЙ§ModelScopeЩчЧјЃЌЪзДЮПЊЗХПЊдДЁЃАЂРядЦЯЃЭћаавЕгІгУепЃЌбаОПЛњЙЙЕФбаОПепПЩвддкДЫЛљДЁЩЯЃЌВњГіБШДяФІдКИќКУЕФФЃаЭЁЃ

Г§СЫжаЮФФЃаЭЃЌДяФІдКЕФаТМгЦТЪЕбщЪвдкModelScopeЩчЧјПЊЗХСЫКмЖрЦфЫћгяжжЕФгябдФЃаЭЁЃ

дкгявєКЯГЩЗНУцЃЌModelScopeЩчЧјПЊЗХСЫДяФІдКДДаТЕФгявєКЯГЩЩљбЇФЃаЭSAMBERTЃЌВЂЧвПЊЗХСЫДяФІдКдЄЯШбЕСЗКУЕФвєЩЋЃЌЗНБуДѓМвжБНгЪЙгУЁЃЕБгУЛЇашвЊЖЈжЦЩљвєЃЌжЛашвЊЪЙгУtraining pipelineЃЌЭЈЙ§дЄбЕСЗФЃаЭМгЗвыЕФЗНЪНЃЌзджїЖЈжЦздМКЯВЛЖЕФвєЩЋЁЃ

дкгявєЛНабЗНУцЃЌДяФІдКПЊЗХСЫгявєЛНабДЪЖЈжЦФЃаЭЁЃгУЛЇжЛашвЊЪеМЏЩйСПЕФЛНабДЪЪ§ОнЃЌОЭПЩвдЖЈжЦздМКЯВЛЖЕФЛНабДЪЁЃ

дкаХКХДІРэЗНУцЃЌДяФІдКЪзХњПЊЗХСЫНЕдыФЃаЭЃЌЛиЩљЯћГ§ФЃаЭЁЃЗНБугУЛЇЖдгявєНјааНЕдыЃЌЛиЩљЯћГ§ЕШЕШЁЃ

дкПкгягябдДІРэЗНУцЃЌДяФІдКПЊдДПЊЗХСЫзюаТЕФПкгяГЄЮФБОгябдДІРэЛљДЁФЃаЭЁАPoNetЁБЁЃPoNetжївЊгУРДДІРэПкгяГЄЮФБОЕФЦЊеТМЖФкШнЃЌдкдЫЫуаЇТЪИњРэНтФмСІЩЯЃЌгХЪЦЭЛГіЁЃДѓМвПЩвдНЋPoNetФЃаЭЃЌзїЮЊдЄбЕСЗФЃаЭЪЙгУЁЃ

ШчЩЯЭМЫљЪОЃЌModelScopeЩчЧјЮЊAIФЃаЭПЊЗЂепЬсЙЉПЊЯфМДгУЕФЛЗОГЃЌДѓМвжЛашЕуЛїгвЩЯНЧМДПЩЁЃ

ШчЩЯЭМЫљЪОЃЌгУЛЇжЛашвЊСНааДњТыЃЌОЭФмдкЗўЮёЦїКѓЖЫРЦ№ФЃаЭЃЌАбФЃаЭМгдиЕНБОЕиВЂдЫааЁЃВЛЭЌФЃЬЌЕФФЃаЭЖМПЩвдЭЈЙ§аоИФСНааВЮЪ§ЃЌжБНгЛёШЁЁЃ
ФПЧАЃЌЦНЬЈЕФШ§АйЖрИіФЃаЭЖМПЩвдЭЈЙ§СНааДњТыжаЕФСНИіВЮЪ§ЪЕЯжРШЁЁЃШчЙћгУЛЇашвЊАбФЃаЭВПЪ№ЕНздМКЕФдЦЖЫЃЌШУдЦЖЫЗўЮёНјааЭЦРэЁЃгУЛЇПЩвдЭЈЙ§SDKжБНгЪЕЯжЁЃ

Г§ДЫжЎЭтЃЌДяФІдКЮЊAIФЃаЭПЊЗЂепЬсЙЉСЫЃЌЭъећЕФЙЄвЕМЖгявєКЯГЩФЃаЭбЕСЗrecipeЁЃДяФІдКдкModelScopeЩчЧјЃЌНЋSAMBERTгявєКЯГЩФЃаЭПЊдДЁЃ
ПЊЗЂепПЩвдЛљгкДяФІдКModelScope SAMBERTдЄбЕСЗФЃаЭМАздгавєПтЃЌЪЕЯжЭъШЋзджїгявєКЯГЩФЃаЭбЕСЗЁЃФПЧАЃЌИќЖрЦфЫќИїРрФЃаЭбЕСЗrecipeТНајПЊдДжаЁЃ

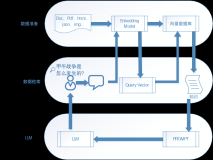
дкгІгУВрЃЌАЂРядЦМДНЋЭЦГігявєAIФЃаЭЗўЮёЁЃЕБгУЛЇНјШыгявєAIФЃаЭЗўЮёЃЌжЛашгявєФЃаЭЃЌОЭФмНЈСЂвЛИіAPIЗўЮёЁЃгУЛЇдкЯэЪмФЃаЭИпОЋЖШЕФЭЌЪБЃЌИУЗўЮёЪЧЭъШЋЕЏадЕФЁЃШУДѓМввдИќИпОЋЖШЁЂИќЕЭГЩБОЃЌЪЙгУФЃаЭAPIгІгУЁЃ

ДяФІдКЯЃЭћЭЈЙ§ModelScopeЩчЧјЃЌЪЭЗХAIФЃаЭДДаТЕФдЖЏСІЃЌЭЈЙ§АЂРядЦгявєAIФЃаЭЗўЮёЃЌЮЊгУЛЇЬсЙЉвЛеОЪНЕФAPIЗўЮёЁЃModelScopeЩчЧјгыAIДДаТепЁЂгІгУепВЂМчаЏЪжЃЌШУгявєAIММЪѕВњЩњИќИпМлжЕЁЃ