баОПепЗжЯэСЫЫћУЧЖдздЖЏМнЪЛГЁОАжаИпаЇПьЫйНјааЪБађНЈФЃКЭЖрЮяЬхзЗзйЗжИюЕФЫМПМЁЃ
БОЮФЪЧЖдЫеРшЪРСЊАюРэЙЄЁЂЯуИлПЦММДѓбЇКЭПьЪжПЦММЕФТлЮФЁЖPrototypical Cross-Attention Networks for Multiple Object Tracking and Segmentation- PCANЁЗЕФНтЖСЃЌИУТлЮФБЛ NeurIPS 2021 НгЪеЮЊ spotlightЁЃ

- ТлЮФЕижЗЃКhttps://arxiv.org/pdf/2106.11958.pdf
- ЯюФПжївГЃКhttps://www.vis.xyz/pub/pcan/
- GitHub ЕижЗЃКhttps://github.com/SysCV/pcan
- жЊКѕдЮФЃКhttps://zhuanlan.zhihu.com/p/445457150
- B еОЕижЗЃКhttps://www.bilibili.com/video/BV1Rb4y1i7zS?spm_id_from=333.999.0.0
ЩюЖШбЇЯАФЃаЭЕФбЕСЗКЭЦРЙРРыВЛПЊДѓаЭЪ§ОнМЏЕФжЇГХЁЃБОЮФЬсГіЕФдаЭНЛВцзЂвтСІЭјТчЃЈ Prototypical Cross-Attention Network, PCANЃЉЪЧЛљгкЫеРшЪРСЊАюРэЙЄКЭ UC ВЎПЫРћЭЦГіЕФбЇЪѕНчзюДѓЙцФЃЕФздЖЏМнЪЛЖрФПБъИњзйКЭЗжИюЃЈMOTSЃЉЪ§ОнМЏ - BDD100K Tracking and SegmentationЁЃЦфжаЃЌBDD Tracking Segmentation Ъ§ОнМЏЕФЙцФЃЪЧ KITTI-MOTS ЕФ 6 БЖЃЈ3,0817 vs 5,027 бЕСЗЭМЯёЁЂ480K vs 26K ЪЕР§бкТыЃЉЃЌБъзЂЮяЬхЪ§СПЪЧ KITTI ЕФНќ 20 БЖЃЌВЂИВИЧАзЬьЁЂвЙМфЁЂ гъбЉЕШИќЮЊЗсИЛецЪЕЕФздЖЏМнЪЛГЁОАЁЃ
баОПепеЙЪОСЫдк BDD100K - Day Ъ§ОнМЏЩЯ PCAN ЕФГЕСОдЄВтНсЙћЃЈАзЬьГЁОАЃЉЁЃ

вдМА BDD100K-Night Ъ§ОнМЏЩЯ PCAN ЕФдЄВтНсЙћЃЈвЙЭэГЁОАЃЉЁЃ

в§бд
ЖрФПБъИњзйКЭЗжИюЃЈMOTSЃЉЃЌЪЧздЖЏМнЪЛКЭЪгЦЕЗжЮіЕШаэЖрЪЕМЪгІгУжаЕФвЛИіживЊЮЪЬтЁЃИУШЮЮёашвЊНЋЪгЦЕжаИјЖЈЕФРрБ№ЕФЫљгаЮяЬхНјааМьВтЁЂЗжРрЁЂИњзйКЭЯёЫиМЖЗжИюЁЃдкздЖЏМнЪЛГЁОАжаЃЌИДдгЕФТЗПіЁЂЪаЧјФкУмМЏЧвЯрЫЦЕФГЕСОКЭааШЫЁЂвдМАЖдЕЭЙІКФЕЭбгЪБЃЈlow computation & low memory cost & onlinЃЉЕФдЄВташЧѓгжИјетвЛШЮЮёДјРДСЫаТЕФЬєеНЁЃгЩгкв§ШыСЫДѓЙцФЃЪ§ОнМЏЃЌШч BDD100KЁЂKITTI ЕШзїЮЊЩюЖШбЇЯАФЃаЭбЕСЗКЭВтЪдЛљзМЃЌЖд MOTS/VIS ЕФбаОПаЫШЄе§бИЫйдіГЄЁЃ
MOTS ЕФДѓВПЗж online ЗНЗЈЃЈMaskTrack R-CNNЁЂSipMask ЕШЃЉжївЊзёбЛљгкМьВтЕФИњзйЗЖЪНЃЈtracking-by-detection paradigmЃЉЁЃЪзЯШдкЕЅеХЭМЦЌФкМьВтКЭЗжИюЖдЯѓЃЌШЛКѓЪЧжЁжЎМфЕФЙиСЊЁЃОЁЙметаЉЗНЗЈвбШЁЕУНЯКУЕФНсЙћЃЌЕЋдкЖдЪБађНЈФЃЩЯНіЯогкЮяЬхЙиСЊНзЖЮЃЌВЂЧвНідкСНИіЯрСкжЁжЎМфЁЃ
СэвЛЗНУцЃЌЪБМфЮЌЖШАќКЌЙигкГЁОАЕФЗсИЛаХЯЂЃЌЭЌвЛЮяЬхЕФВЛЭЌЪБМфЯТЖрИіНЧЖШЕФЪгЭМПЩвдЬсИпдЄВтЕФЮяЬхЗжИюЁЂЖЈЮЛКЭРрБ№ЕФжЪСПЁЃШЛЖјЃЌИпаЇЕиРћгУРњЪЗаХЯЂЃЈmemory informationЃЉШдШЛЪЧвЛИіЬєеНЁЃЫфШЛЛљгкзЂвтСІЛњжЦЕФЪБађНЈФЃЗНЗЈЃЈАќКЌ Self-Attention, Non-local Attention КЭ Transformer ЕШЃЉвбгІгУгкЪгЦЕДІРэЃЌЕЋЫќУЧЭЈГЃжБНгЖдИпЗжБцТЪЕФЩюЖШЬиеїЭМНјааВйзїЁЃГЄЪБМфађСаЩЯЕФУмМЏЕФЯёЫиМЖзЂвтСІВйзїЛсВњЩњЖдГЄЖШЕФЖўДЮИДдгадЃЈquadratic complexityЃЉЃЌНјвЛВНДјРДОоДѓЕФМЦЫуИКЕЃКЭ GPU ФкДцЯћКФЃЈР§Шч VisTR ЕШЃЉЃЌвВМЋДѓЕиЯожЦСЫЫќУЧЕФЪЕМЪгІгУЁЃ
PCAN ЬсГіСЫвЛжжМђЕЅИпаЇЕиРћгУЪгЦЕЪБађаХЯЂЕФЛњжЦ, ЭЈЙ§ЖдФПБъЮяЬхМАЙ§ШЅжЁЕФЭтЙлЬиеїзіИпЫЙЛьКЯНЈФЃЃЌЕУЕНЪ§СПНЯЩйЧвЕЭжШЃЈsparse and low-rankЃЉЕФБэеїЛьКЯдаЭЃЈПЩвдРэНтЮЊЖрИіВЛЭЌЕФ cluster centersЃЉ, ЪЕЯжСЫЖдРњЪЗаХЯЂЃЈmemory bankЃЉЕФбЙЫѕЁЃетвЛВйзїдкНЕЕЭзЂвтСІдЫЫуИДдгЖШКЭФкДцашЧѓЕФЭЌЪБ, вВЬсИпСЫЪгЦЕЮяЬхЗжИюЕФжЪСПКЭзЗзйЕФЮШЖЈадЁЃPCAN АќРЈжЁМЖЃЈframe-level moduleЃЉКЭЪЕР§МЖЃЈinstance-level moduleЃЉСНИіФЃПщЕФдаЭНЛВцзЂвтСІЃЈprototypical cross-attentionЃЉЃЌЧАепжиЙЙЙ§ШЅжЁЕФЩюЖШЬиеїВЂНЋЦфгыЕБЧАжЁЖдЦыЃЌЖјКѓепОлНЙгкЪгЦЕжаЕФБЛзЗзйЮяЬхЁЃ
ЮЊСЫдіЧПЖдЮяЬхЭтЙлЫцЪБМфБфЛЏЕФТГАєадЃЌPCAN ЭЈЙ§ЖдБШбЇЯАЃЈcontrastive learningЃЉЕФЛњжЦЗжБ№ЪЙгУ foreground/positive КЭ background/negative prototypesЃЈЧАОАКЭБГОАдаЭЃЉРДНјвЛВНБэЪОУПИіЖдЯѓЪЕР§ЃЌВЂЧвНЋетаЉдаЭвддкЯпЗНЪНДЋВЅИќаТЃЈonline updatingЃЉЁЃгЩгкУПИіЪЕР§ЛђжЁЕФдаЭЪ§СПгаЯоЃЌPCAN дкЪгЦЕжаОпгаЪБМфЯпадИДдгЖШЕФИпаЇЕижДаадЖГЬЬиеїОлКЯКЭДЋВЅЁЃ
ЗНЗЈИХЪі
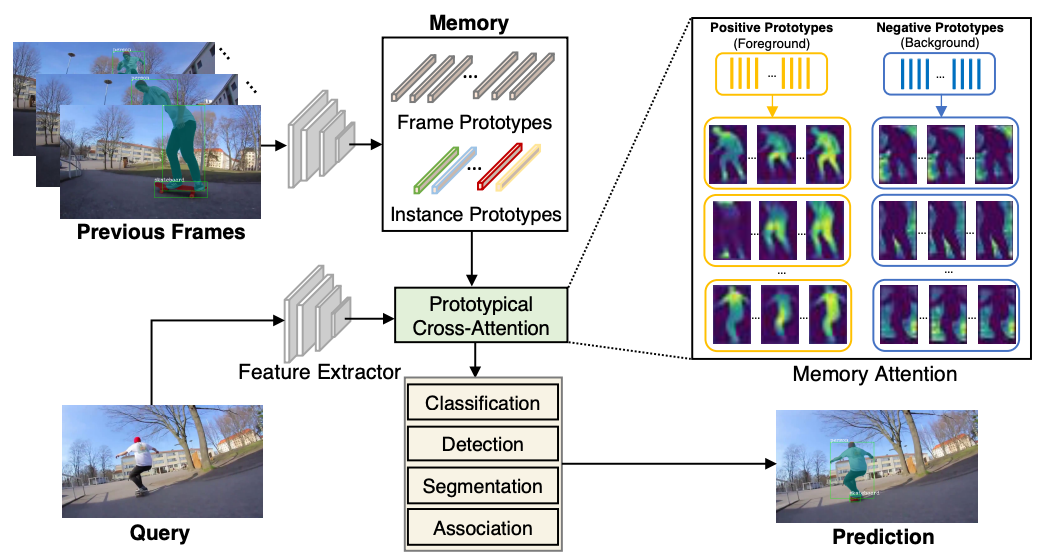
PCAN ЕФНсЙЙПђМм
PCAN ЪзЯШНЋРњЪЗаХЯЂЃЈmemory bankЃЉжаЕФИпЗжБцТЪЬиеїбЙЫѕЕНжЁМЖКЭЪЕР§МЖЕФдаЭЃЈprototypesЃЉжаЃЌШЛКѓЭЈЙ§даЭНЛВцзЂвтСІЃЈprototypical cross-attentionЃЉВйзїЃЌДггЩдаЭзщГЩЕФ space-time memory bank жаШЅЬсШЁКЭРћгУЙ§ШЅжЁжаАќКЌЕФЗсИЛЕФЭтЙлЁЂЮЦРэКЭЙВЯэаХЯЂЕШЁЃ
ПеМф - ЪБМфжаЕФДЋЭГНЛВцзЂвтСІЙЋЪНЃК
ПеМф - ЪБМфжаЕФдаЭНЛВцзЂвтСІЙЋЪНЃК
Memory bank жа prototypes ЕФЪ§СП ЃЌетгааЇЕиБмУтСЫЖдећИіИпЗжБцТЪЕФРњЪЗЬиеїзіж№ЯёЫиУмМЏЕФ attention ВйзїЁЃPCAN ВЩгУИпЫЙЛьКЯФЃаЭЃЈGaussian Mixture Models, GMMЃЉРДНјааЮоМрЖНЬиеїОлРрЃЌВЂбЁШЁ EMЃЈExpectation-MaximizationЃЉЕќДњЫуЗЈЕФЕУЕНЕФИпЫЙЗжВМФтКЯОлРржааФзїЮЊ prototypesЁЃЦфжаЃЌУПИіЯёЫиЬиеїЕуЕН prototype жааФ
ЃЌетгааЇЕиБмУтСЫЖдећИіИпЗжБцТЪЕФРњЪЗЬиеїзіж№ЯёЫиУмМЏЕФ attention ВйзїЁЃPCAN ВЩгУИпЫЙЛьКЯФЃаЭЃЈGaussian Mixture Models, GMMЃЉРДНјааЮоМрЖНЬиеїОлРрЃЌВЂбЁШЁ EMЃЈExpectation-MaximizationЃЉЕќДњЫуЗЈЕФЕУЕНЕФИпЫЙЗжВМФтКЯОлРржааФзїЮЊ prototypesЁЃЦфжаЃЌУПИіЯёЫиЬиеїЕуЕН prototype жааФ ЕФОрРыЖЈвхЮЊ
ЕФОрРыЖЈвхЮЊ ЁЃИќЮЊЯъЯИЕФЙЋЪННВНтЧыВЮПМдТлЮФЃК
ЁЃИќЮЊЯъЯИЕФЙЋЪННВНтЧыВЮПМдТлЮФЃК
PCAN ПђМмИХРРЭМШчЯТЃК
Frame-level PCAN
Ждгк memory bank жаЕФжЁЬиеїЃЌбаОПепЪзЯШНјааЛљгк GMM ЕФОлРрЃЈИпЫЙЗжВМФтКЯЃЉвдЛёЕУ key КЭ value prototypesЃЌВЂИљОнЕБЧАжЁЕФВњЩњЕФ key ИљОн cross-attention weights НЋЦфЕЭжШжиНЈЁЃ
ЛљгкдаЭКЭЕБЧАжЁжиНЈжЁЬиеїЁЃ
жиНЈЕФЬиеї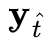 ВЛНігыЕБЧАжЁ
ВЛНігыЕБЧАжЁ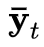 ЖдЦыЃЌЛЙЭЈЙ§гаЯоЪ§СПЕФИпЫЙЗжВМФтКЯШЅГ§СЫЬиеїжаШпграХЯЂ (noise reduced)ЃЌдкБЃГжЯёЫиЕуЬиеїПеМфВювьЕФЭЌЪБЃЌЯрЫЦЕуМфЕФФкВПВювьЕУЕННјвЛВНЫѕаЁЁЃЫцКѓЃЌжиНЈЬиеїгыЕБЧАжЁЬиеїзіМгШЈШкКЯЃЌВњЩњЕФаТЪБађЬиеїгУгкКѓај MOTS жаЕФЗжРрЃЌМьВтЃЌЗжИюКЭзЗзйЕШЖрИізгШЮЮёЁЃ
ЖдЦыЃЌЛЙЭЈЙ§гаЯоЪ§СПЕФИпЫЙЗжВМФтКЯШЅГ§СЫЬиеїжаШпграХЯЂ (noise reduced)ЃЌдкБЃГжЯёЫиЕуЬиеїПеМфВювьЕФЭЌЪБЃЌЯрЫЦЕуМфЕФФкВПВювьЕУЕННјвЛВНЫѕаЁЁЃЫцКѓЃЌжиНЈЬиеїгыЕБЧАжЁЬиеїзіМгШЈШкКЯЃЌВњЩњЕФаТЪБађЬиеїгУгкКѓај MOTS жаЕФЗжРрЃЌМьВтЃЌЗжИюКЭзЗзйЕШЖрИізгШЮЮёЁЃ
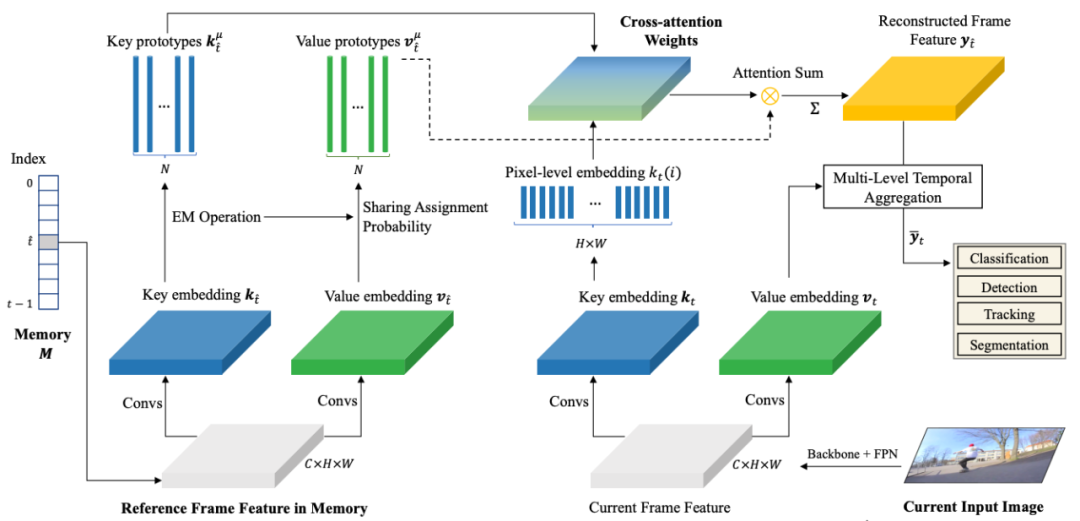
frame-level даЭНЛВцзЂвтСІИХРРЭМЁЃ
Instance-level PCAN
Ждгк MOTS жаИааЫШЄзЗзйЕФЮяЬхЃЌбаОПепНјвЛВНИљОнГѕЪМЕФ mask КЭ bounding box ЖдЮяЬхзіЧАКѓБГОАЕФЧјЗжЃЌЧАОАЃЈЛЦЩЋЧјгђЃЉНЈФЃЮЊ positive instance prototypesЃЌБГОАНЈФЃЃЈРЖЩЋЧјгђЃЉЮЊ negative prototypesЁЃетаЉ instance specific ЕФ prototypes ЫцзХЪБМфВЛЖЯИќаТЃЌИќаТЛњжЦВЩгУЛЌЖЏЦНОљРДИќаТЃЌРрЫЦгк LSTM жаЕФ hidden stateЁЃ
дкЕкжЁЪБЃЌетаЉ positive КЭ negative ЕФ prototypes ЗжБ№ВњЩњВЛЭЌЕФ attention mapsЃЌДгжавВФмПДГіВЛЭЌ prototype ЕФЙизЂДњБэЧјгђЁЃзюКѓНЋГѕЪМЕФЮяЬх maskЁЂВњЩњЕФ instance attention mapЁЂвдМАШкКЯЪБађаТЕФ frame feature concat дквЛЦ№ЃЌЭЈЙ§вЛИіМђЕЅЕФЗжИю FCN ЭјТчЕУЕНзюжеЕФ mask дЄВтЁЃ
ЫцЪБМфИќаТЪЕР§даЭЁЃ
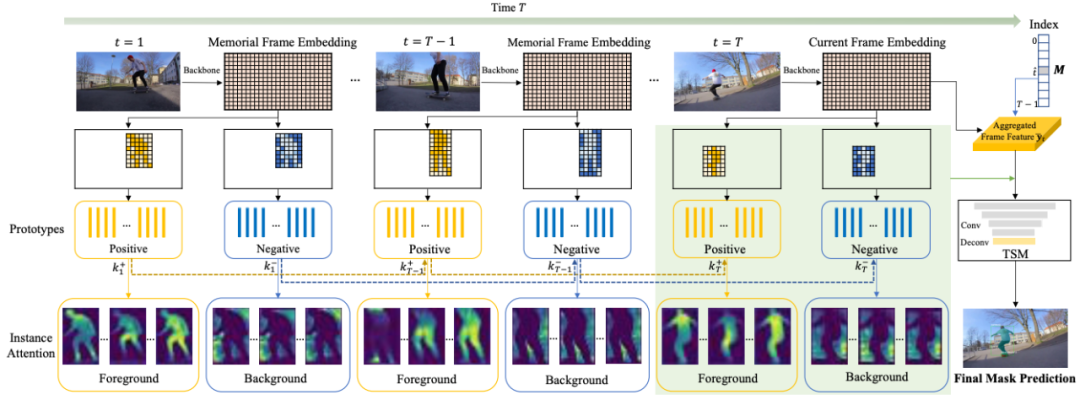
ОпгаЧАОАКЭБГОАдаЭЁЂЪБађДЋВЅЕФЪЕР§МЖдаЭзЂвтСІЁЃ
ЪЕбщ
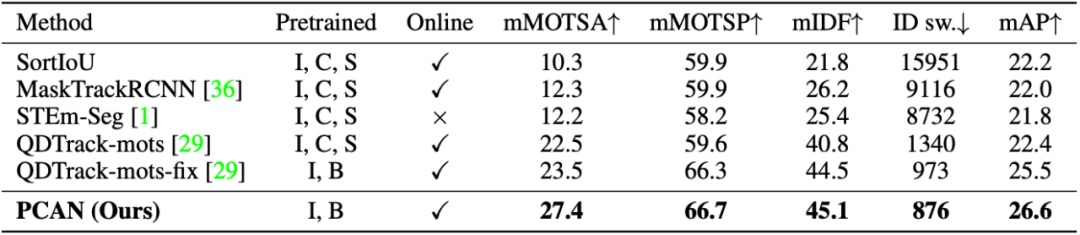
PCAN зїЮЊвЛИі online method дкСНИізюДѓЙцФЃЕФ MOTS Ъ§ОнМЏ BDD100K КЭ Youtube-VIS ЩЯЖМШЁЕУСЫСьЯШадФмЁЃ
BDD100K ЗжИюзЗзйбщжЄМЏЩЯЕФБШНЯНсЙћЁЃ

Youtube-VIS бщжЄМЏЩЯЕФБШНЯНсЙћЁЃ
PCAN дк Youtube-VIS ЕФадФмЫцзХ memory tube length КЭ prototype Ъ§СПЕФБфЛЏЃЌДгжаПЩПДГіГЄЪБађНЈФЃКЭдквЛЖЈЗЖЮЇФкдіЖр prototype Ъ§СПЕФДјРДЕФадФмИФЩЦЁЃ

ГЄЦкЪБађаХЯЂКЭдаЭОлРрЕФгАЯьЁЃ
даЭНЛВцзЂвтСІПЩЪгЛЏ
ЁОInstance-levelЁПЖдКьЩЋащЯпПђжаЕФЦћГЕЕФ instance attention ПЩЪгЛЏЁЃбаОПепбЁдёЧАЫФИіЧАОА / БГОАдаЭзїЮЊЪОР§ЃЌЦфжаУПИіЖМзЈзЂгкЬиЖЈЕФЦћГЕзгЧјгђЃЌР§ШчЕквЛИі prototype ЙизЂгкГЕЭЗЕФЮЛжУЃЌВЂЧветвЛ attention ЗжВМЫцзХЪБМфЕФЭЦвЦОпгавўЪНЮоМрЖНвЛжТадЁЃ

гЩКьЩЋЕуБпНчПђЖЈЕФЦћГЕЪЕР§НЛВцзЂвтСІ
ЖдКьЩЋащЯпПђжаЕФааШЫЕФ instance attention ПЩЪгЛЏЃК
КьЩЋЕуБпНчПђЖЈЕФааШЫдаЭЪЕР§НЛВцзЂвтСІЕиЭМЁЃ
ЁОFrame-levelЁПЖдећеХЭМ frame-level ЕФПЩЪгЛЏЃЌЦфжаЫцЛњбЁдёСЫ 8 Иі frame prototypes ВЂдкЭМЯёЩЯЯдЪОСЫЫќУЧЕФзЂвтСІЗжВМЁЃЯдШЛЃЌУПИі frame prototype ЖМбЇЛсЖдгІЭМЯёЕФвЛаЉгявхИХФюЃЌКИЧЧАОАКЭБГОАЧјгђЃЌР§ШчШЫЁЂЛЌАхЁЂгъЩЁКЭЭјЧђХФЕШЕШЃЌетаЉЖМЪЧЭЈЙ§ЮоМрЖНОлРрЫљбЇЯАЕНЕФЁЃ

ПЩЪгЛЏЫцЛњжЁдаЭЕФ frame-level даЭНЛВцзЂвтСІЕиЭМЁЃ
BDD100k ЪЕР§ЗжИюзЗзйОКШќ

- BDD100K Dataset ЕижЗЃКhttps://www.bdd100k.com/
- BDD100K Tracking & Segmentation ХХааАёЃКhttps://eval.ai/web/challenges/challenge-page/1295/overview
ВЮПМСДНг
- Non-local Neural Networks: https://arxiv.org/abs/1711.07971
- EMANet: Expectation-Maximization Attention Networks for Semantic Segmentation
- KITTI MOTS: MOTS: Multi-Object Tracking and Segmentation
- Space-Time Memory Networks: https://arxiv.org/abs/1904.0060